Parser Combinators


We began the meeting by welcoming attendees new and old and James kicked things off by recapping his introduction to parser combinators.
The idea behind parser combinators is that each common operation in a parser can be implemented by a function, and then those functions can be combined into more elaborate operations. In general, a combinator is a function that takes an input state, typically the text to be parsed and an offset representing how far into the string you’ve already scanned. If the combinator matches the input at the current offset, it returns a parse tree and a new state: the text with the offset moved to the end of the text matched by the combinator. If it fails, it returns nothing, or the state it was given, depending on what’s most convenient for your implementation.
After explaining the core concept of parser combinators (covered more thoroughly in the aforementioned blog post) and touching on the issue of precedence and associativity in recursive descent, James introduced six useful combinators that he'd already implemented ahead of the meeting for us to mob with:
-
str(string, &action): match a literal stringstringand perform someactionwith the resulting tree; -
chr(pattern, &action): match some character classpattern(e.g.a-z) and perform someactionwith the resulting tree; -
seq(*parsers, *action): match a contiguous sequence of other combinatorsparsersand perform someactionwith the resulting tree; -
rep(parser, n, *action): match another combinatorparserat leastntimes and perform someactionwith the resulting tree; -
alt(*parsers, &action): attempt to match the given combinatorsparsersin order and perform someactionon the first matching combinator; -
ref(name): an indirect reference to a named combinator, allowing us to form recursive matches.

With the core concepts in place, we decided to mob a parser for the arith language introduced in the early chapters of "Types and Programming Languages". Specifically, this minimal language:
t = true
false
0
succ t
pred t
iszero t
if t then t else t
Our first goal being to parse the following expression:
if iszero pred succ 0 then true else false
Into our own representation using Ruby classes like so:
If.new(IsZero.new(Pred.new(Succ.new(Zero))), True, False)
We began by implementing the "constants" of our language, 0, true and false by writing some RSpec tests and choosing some representation of our terms as plain Ruby objects.
Using James' existing ParserCombinators library as a starting point, we wrote our own Parser class with the following minimal rules (note that the library assumes a method called root as a starting point for parsing):
class Parser
include ParserCombinators
def root
alt(zero, tru, fals)
end
def zero
str('0') { Zero }
end
def tru
str('true') { True }
end
def fals
str('false') { False }
end
endWe then went on to add support for a slightly more complicated term: succ t which can contain any other term as its argument. We began with a failing test, detailing our desired outcome:
Succ.new(Zero)And then added the rules to parse it:
class Parser
def root
alt(zero, tru, fals, succ)
end
def succ
seq(str('succ '), ref(:root)) { |node| Succ.new(node.last) }
end
endAs the node yielded to us for the term succ 0 would be the following Ruby array:
[:seq, [:str, 'succ '], Zero]We simply take the last element of this array as the inner term we want to wrap in a Succ.
We then decided to relax the whitespace requirement so that we could also parse expressions with more than one space between succ and 0 by extracting a separate whitespace rule:
class Parser
def succ
seq(str('succ'), whitespace, ref(:root)) { |node| Succ.new(node.last) }
end
def whitespace
rep(str(' '), 1)
end
endWe initially ignored Chris' pleas to abbreviate this to ws but later succumbed to defining an alias for whitespace called _.
class Parser
alias _ whitespace
endWith the liberal application of copy-paste technology, we had similar support for pred and iszero and then decided to do a Computation Club first: a little refactoring.
Specifically, we decided to introduce a brand new combinator just for these function call-like terms:
class Parser
def function_call(name, klass)
seq(str(name), whitespace, ref(:root)) { |node| klass.new(node.last) }
end
endThis meant we could express succ, pred and iszero more succinctly:
class Parser
def succ
function_call('succ', Succ)
end
def pred
function_call('pred', Pred)
end
def iszero
function_call('iszero', IsZero)
end
endWe were happy to discover that this meant we could parse arbitrarily nested terms like the following:
succ succ succ succ 0
Emboldened, we jumped into parsing our original goal by adding support for if t then t else t:
class Parser
def root
alt(zero, tru, fals, succ, pred, iszero, iff)
end
def iff
seq(str('if'), _, ref(:root), _, str('then'), _, ref(:root), _, str('else'), _, ref(:root)) { |node|
If.new(node[3], node[7], node[11])
}
end
endThe main trick here was trying to figure out the correct indexes into node which we double-checked by inspecting the raw AST output from our combinator:
[:seq,
[:str, "if"],
[:rep, [:str, " "]],
"(iszero (pred (succ 0)))",
[:rep, [:str, " "]],
[:str, "then"],
[:rep, [:str, " "]],
true,
[:rep, [:str, " "]],
[:str, "else"],
[:rep, [:str, " "]],
false]Having met our original goal, we were keen to get into thorny issues of associativity and so decided to spend the remaining time trying to implement the untyped Lambda Calculus, specifically the following Lambda expressions:
x
λx.x
λx.λy.x
x y
x y z
We began simply enough with variables such as x by defining them as a single lowercase letter:
class Parser
def root
alt(zero, tru, fals, succ, pred, iszero, iff, var)
end
def var
chr('a-z') { |node| Var.new(node.last) }
end
endWe then tackled abstractions:
class Parser
def root
alt(zero, tru, fals, succ, pred, iszero, iff, var, abs)
end
def abs
seq(str('λ'), ref(:var), str('.'), ref(:root)) { |node| Abs.new(node[2], node[4]) }
end
endHowever, things started to get tricky when we approached applications. Our first test case of x y seemed straightforward enough:
class Parser
def root
alt(zero, tru, fals, succ, pred, iszero, iff, var, abs, app)
end
def app
seq(ref(:root), _, ref(:root)) { |node| App.new(node[1], node[3]) }
end
endBut disaster! Instead of a lovely App object, we got a dastardly nil. This was our first exposure to the importance of the order of combinators in an alt as we were attempting to parse x y as a variable first. This happily matched the x but left the rest of the input unparsed causing our parser to bail out and return nil.
Refusing to be defeated, we realised that we needed to re-order our combinators so that app (the "greedier" combinator) needed to precede var:
class Parser
def root
alt(zero, tru, fals, succ, pred, iszero, iff, app, var, abs)
end
endBut oh no: it all went horribly wrong again and James cackled evilly to himself as we saw that this was an example of pesky left-associativity which is particularly tricky using this parsing technique.

More specifically, we were now attempting to parse x y by first calling root which then called app which then called root which then called app which then called... ad infinitum, never consuming any of the input and leaving us in a loop forever.
We decided to cheat a bit here and make our combinator a bit stricter instead:
class Parser
def app
seq(ref(:var), _, ref(:var)) { |node| App.new(node[1], node[3]) }
end
endThis worked for our first case of x y!
Rapidly running out of time, we decided to tackle x y z which should be parsed as if it were (x y) z and not x (y z).
We decided to try something bold and parse the term in a right-associative way (as that is easy enough to do with combinators) and attempt to rotate the tree ourselves:
class Parser
def app
seq(ref(:var), _, alt(ref(:app), ref(:var))) do |node|
case node[3]
when App
App.new(App.new(node[1], node[3].left), node[3].right)
when Var
App.new(node[1], node[3])
end
end
end
endThis actually worked for x y z but sadly not for the more general x y z a. We thought of ways we might be able to resolve this with a recursive tree rotation but alas we were out of time.
You can find our finished code in our parser-combinators repository.
Paul briefly showed off his LALRPOP grammar in Rust for the fullsimple language from TAPL to contrast how left-associativity is handled by a bottom-up parsing technique.
James took a minute after the mobbing to show his work to implement a parsing technique known as Unger's Method, as described in Parsing Techniques by Grune and Jacobs. This is a non-directional method, meaning that rather than scanning through the input from left to right, it looks at the input as a whole and tries to find every possible way of dividing it up in ways that match the grammar. Looking at different parsing techniques emphasises that the grammar we've developed is not the one true grammar, but one that works for the technique we're using.
Unger is able to deal with ambiguous grammars, such as the one TAPL gives for the basic terms:
Term → Var | Abs | App
Var → a | b | c | d | e | f | g | h | i | j | k | l | m |
n | o | p | q | r | s | t | u | v | w | x | y | z
Abs → λ Var . Term
App → Term Term
This is ambiguous because the rule for App means that an input like x y z
could parse as (x y) z or x (y z), and λx. y z could parse as (λx. y) z.
This highlights that although the above grammar might be the most obvious and
direct way to express the rules, it won't lead to a parser giving the exact
results we want: the grammar must be adapted to fit the parsing method we're
using.
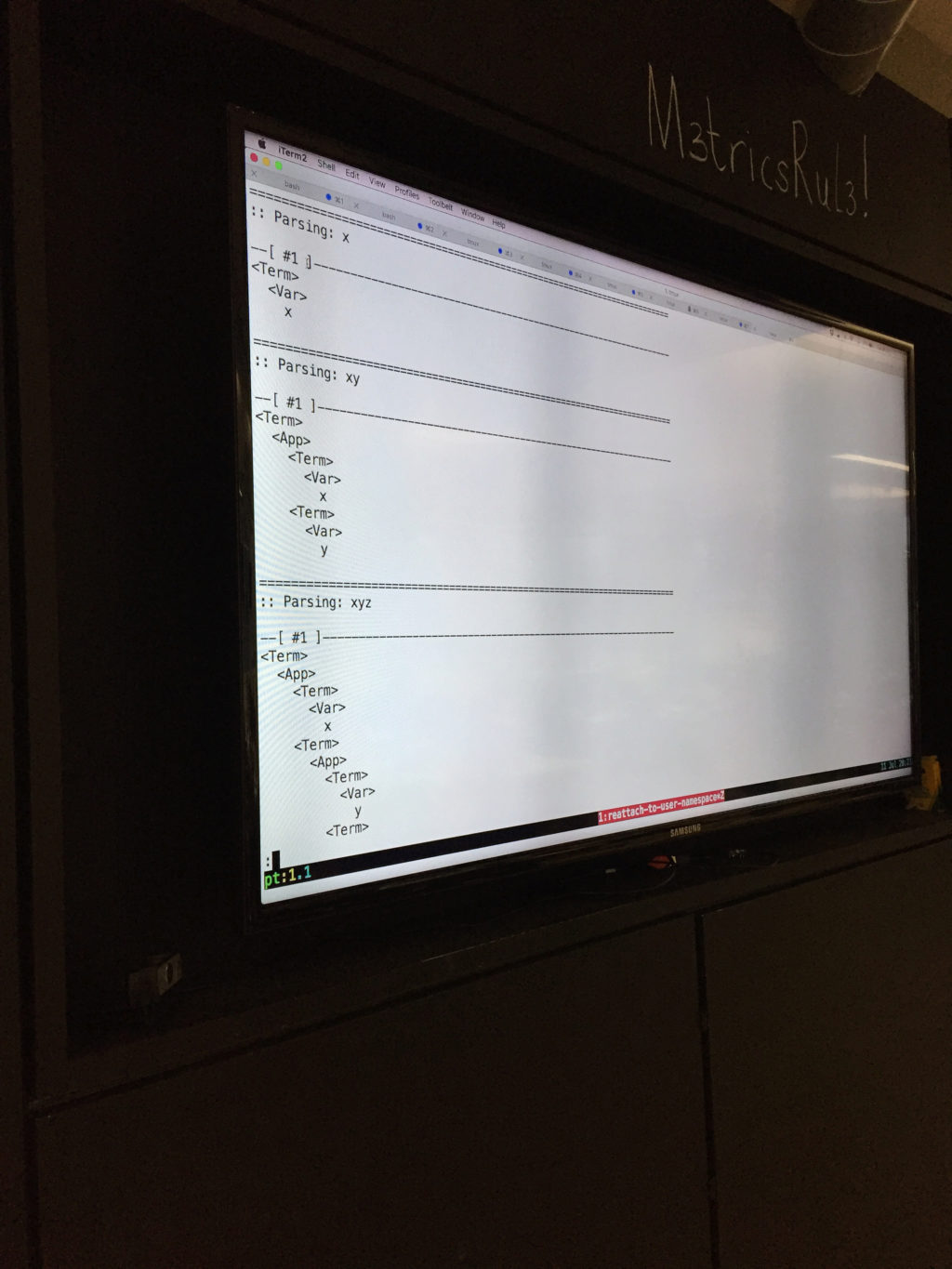
For example, Unger gives one parse for a simple application:
<Term>
<App>
<Term>
<Var>
x
<Term>
<Var>
y
but it gives two parses for three terms, one right-associative and one left-associative:
<Term>
<App>
<Term>
<Var>
x
<Term>
<App>
<Term>
<Var>
y
<Term>
<Var>
z
<Term>
<App>
<Term>
<App>
<Term>
<Var>
x
<Term>
<Var>
y
<Term>
<Var>
z
Similarly it gives two parses for λx. y z, and five parses for w x y z,
giving all possible groupings of applications.
Some parsing techniques let one write the rules as above and then provide hints about precedence in a different format, while others require one to make the grammar unambiguous. Some require the grammar to be refactored into a specific form to make parsing more efficient. Unger requires an unambiguous grammar to make unique parses.
We can change the grammar slightly to force left-associative nesting:
App → App Op | Op Op
Op → Var | Abs
The App Op part forces left-associativity (unlike our combinators approach,
and most other top-down methods, Unger can handle left recursion) and we now get
one parse for w x y z:
<Term>
<App>
<App>
<App>
<Op>
<Var>
w
<Op>
<Var>
x
<Op>
<Var>
y
<Op>
<Var>
z
However we still get two parses where an abstraction is involved:
<Term>
<Abs>
λ
<Var>
x
.
<Term>
<App>
<Op>
<Var>
y
<Op>
<Var>
z
<Term>
<App>
<Op>
<Abs>
λ
<Var>
x
.
<Term>
<Var>
y
<Op>
<Var>
z
To make abstractions "greedy" we need to make sure they can only appear in the final position in an abstraction:
App → App Last | Op Last
Op → Var
Last → Var | Abs
or,
App → Op Last
Op → App | Var
Last → Var | Abs
Now finally we get a unique parse for all applications and for terms like λx. y z:
<Term>
<Abs>
λ
<Var>
x
.
<Term>
<App>
<Op>
<Var>
y
<Last>
<Var>
z
From this we see that a grammar is not just a description of valid parse trees, it must be organised in a way that your parser gives the exact tree you want for ambiguous inputs, and there are multiple expressions of the grammar that will give a correct result.
- Feelings were largely positive about the meeting and there was a lot of appreciation for the obviously large amount of work James had done to prepare for the meeting.
- The specific focus of the meeting was praised as parsing is a very large topic (particularly compared to our previous interstitial).
- The idea of a start of meeting introduction, particularly with information helpful to new members, received wide support.
- There was agreement that the mobbing was more successful than last time (particularly after Paul was reminded not to drive and let the crowd steer).
- We decided to do a better job of providing soft drinks without people having to ask for them.
- There was concern that while this was a non-book meeting, we may have veered into assuming a familiarity with our progress in Types and Programming Languages (e.g. our choice of the
arithlanguage and particularly when we switched to the Lambda Calculus without much introduction).
Thanks to Charlie for organising the meeting, to Geckoboard and Leo for hosting and providing beverages, to Chris for providing bread and vital dips, to James for the huge amount of preparation and leading the meeting and to Laura for volunteering the organise the next meeting.