QLearning_faq
1. Value function is defined for three types of entities - tile, state (location) and state-action. How are these different from each other?
For both tiling approximator and nearest neighbor approximator, only the tile value is stored in the memory. There are 64 tiles, and hence 64 tile values (can be initialized to zeroes).
For the tiling approximator, each state (location) belongs to only one of the 64 tiles. State values are therefore same as corresponding tile values. Therefore, all 64 states within a given tile have the same value. For the nearest neighbor approximator, state values are computed using the weighted sum of the nearest neighbor tile values (using equations shown on the assignment page).
State-action value (also referred to as Q(state,action)) is the same as the value of the destination state reached after taking the action. Each state has 4 Q-values, one for each action (Up, Down, Left, Right). However, in deterministic environments (i.e. an environment where the result of taking a given action is always the same), the Q (state, action) value is equal to the value of the destination state (destination state is the state that the agent ends into after taking the action). Look at the figure below
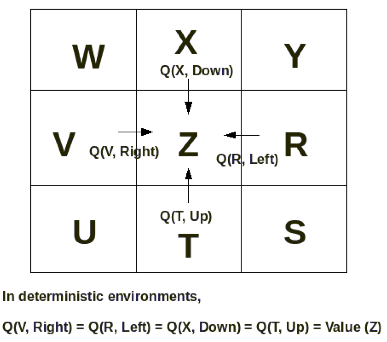
Therefore for tiling approximator,
Value (State, Action) = Value (Destination state) = Tile value corresponding to the destination state
and for nearest neighbor approximator,
Value (State, Action) = Value (Destination state) = Weighted Average of 3 tile values nearest to the destination state
Yes, for the tiling approximator, X, W, Y, Z (see figure on assignment page) will have the same value since they lie in the same tile. However, for nearest neighbor approximator, each can have a different value.
We are using tiles B and C (for nearest neighbor approximator) so that we can distinguish the adjacent locations in A (like W, X, Y, Z). The locations that are closer to B and C (in terms of Euclidean distance) will have values similar to B and C than the ones that are further away.
The figure on assignment page describes the value update equation for the nearest neighbor approximator. Notice, that tiling approximator is a special case of nearest neighbor approximator, where only the nearest tile is considered. The weight of this nearest neighbor tile is set to one (and rest to zero) in the nearest neighbor equations to obtain tiling approximator equations. Also note that the update equation for tile values is the same as the one given in your book (equation 21.13). Features f1, f2 ... fn in the book corresponds to Weight (A), Weight (B), Weight (C). Feature parameters θ(1), θ(2), ... θ(n) in the book corresponds to Value (A), Value (B) ... Value (64) These feature parameters (θ(n)/Value(n)) are the ones which are stored, updated and learned.
To simplify the implementation, you can check only the surrounding 9 tiles (including the tile that encapsulates the location) to find the 3 nearest, reachable tiles. Note, in certain cases you might find only 2 out of the 9 surrounding tiles to be reachable. In such a scenario, use only 2 tile values.
6. For nearest neighbor, do we update the value for tile A and the other two tiles we are considering or just tile A?
As described in the figure on the assignment page, you will update the values of all the tiles (A, B and C) that contributed to the value of the state-action (i.e. the value of destination state) that the agent executed. Note, that for tiling approximator, you will only update the value of one tile (tile which encapsulates destination state).
While computing nearest neighbor tiles, you need to take care of certain special cases -
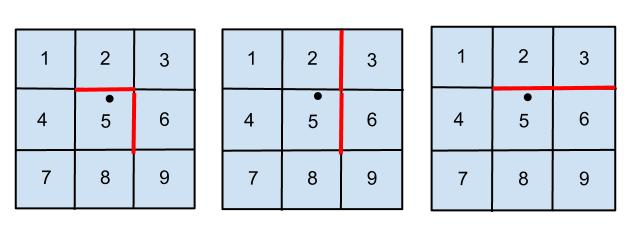
For example, in the figure on the left (with walls located at (2,5) and (5,6)), executing the following condition
if ((tile 5 coordinates), (tile 3 coordinates)) in get_environment().maze.walls:
will result false. Instead, to check whether tile 3 is reachable from tile 5, you need to check whether there exists a 'two tile step' path from 5 to 3.
- In tiling approximator, the 64x64 grid is divided into 8x8 tiles. Therefore, each tile stores the same value for some 8x8 locations. When you need to find the value of taking an action at a given location (like Value (Y, Left)), you just look up the tile value of the destination location (X).
- In nearest neighbor approximator, to calculate Value (Y, Left), compute the value of destination location X by taking the weighted average of the values of 3 nearest neighbor tiles of X. Notice that the tile encapsulating X is surrounded by 8 tiles (Up, Down, Left, Right, and 4 diagonal tiles). Find the tiles which are reachable from the tile encapsulating X, and then sort them in increasing order of their distance from X. Pick the closest 3 tiles (which of-course will include the tile which encapsulates X).
- Compute the values of all the other actions from Y (Value(Y, Right) and Value(Y, Down)). Once the values of all the possible actions from Y are available, select an action using epsilon greedy policy (look at get_epsilon_greedy () method in CustomRLAgent to see how this works). Lets say epsilon greedy policy selects action 'Move Left'.
- Once the agent takes the action 'Move Left', agent will move to a new location (X in the figure). Now after reaching X, you will update the values of the 3 nearest neighbor tiles (only one in case of tiling approximator) of X (A, B and C). These are the same nearest neighbor values which contributed towards calculating the value of X in step 1. Therefore, it makes sense that once we are at X, we update/learn their values.