Internals
This is an outdated document. Please update!
This page contains a few notes about Souffle's internal software architecture as well as a description of the essential components contributing to the processing of an input Datalog program.
Soufflé is implemented in C++. The source code is documented using Doxygen conventions. The configuration files are kept in the top-level directory of the repository. By default the documentation is not built. To generate Doxygen documentation in html format issue the following command
make doxygen-doc
that will create the directory doc/html which will contain the file index.html to view the documentation.
Configuration files and inputs to tests are located in the tests folder relative to the top-level directory of the project.
The outputs for failing test cases are placed to tests/testsuite.dir.
The output files for passing test cases are erased.
The main configuration file for the souffle test-suite is tests/testsuite.at. This file controls which tests are run, and defines and documents several m4 macros we use for testing of the datalog executable.
The test cases themselves are specified via test configuration files.
These files are included to tests/testsuite.at using m4_include macros.
The configuration files separate the test suite into several logical sections.
At the current stage the Datalog project uses the following test configuration files:
- tests/evaluation.at - tests that check correctness of results of evaluation of Datalog programs
- tests/interface.at - tests that check Soufflé's C++ interface
- tests/profile.at - tests that check the Soufflé profiler
- tests/semantic.at - tests for semantic features (i.e., groundness, relation definitions, variable types etc.)
- tests/syntactic.at - parser and lexer tests
There are two types of tests:
- Positive tests: store your fact files in the facts sub-directory and the expected output files (as .csv) in the directory of the testcase
- Negative tests: store your error file in the directory of the testcase
Within each .at file is a sequence of test cases in the following format:
POSITIVE_TEST([name], [category])
The test case should then be placed in category/name/ relative to the tests directory. This directory should contain:
-
name.dl: the datalog program to be tested -
name.out: expected stdout output -
name.err: expected stderr output -
output_rel.csv: the expected contents of any IDB relation of the nameoutput_reldefined inname.dl. -
facts/input_rel.facts: the contents of any EDB relation of the nameinput_reldefined inname.dl.
A test may also be defined as a multi-test:
POSITIVE_MULTI_TEST([name],[category], [[case_1], ... , [case_n]])
In this instance, name.dl is still located in category/name/, while the files listed above should be in category/name/case_i/, for the appropriate case, but .facts files should not be inside a facts/ directory.
The Engine can be set up in two different modes. an interpreter and a compiler mode. The corresponding modes are covered in the following subsections.
The following image illustrates the engines configuration in interpreter mode.
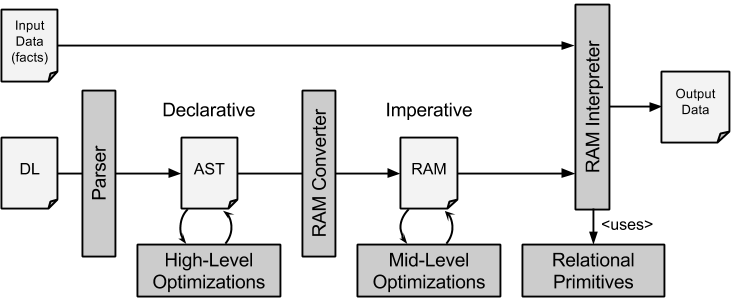
A datalog program (DL) is loaded and processed by the parser resulting in an AST (abstract syntax tree) based representation. The parser is thereby checking for syntactic errors and reports potential errors. If the parsing fails, the processing is aborted. Furthermore, during the parser phase, preprocessor directives (macros) and component instantiations are processed. The resulting AST consists solely of a set of relation declarations and clause definitions.
In the following step the AST representation is utilised for applying semantic checks, including a consistent utilisation of relation symbols (arity), the boundness of variables as well as type checks. If the input program is free of errors, a sequence of high-level optimisations are applied. These include the elimination of unreferenced and/or empty relations, the reduction of unused variables within clauses, and the introduction of auxiliary relations for the processing of aggregation operations. The range of covered operations may be further extend in the future.
The AST IR (intermediate representation) is now converted by the RAM converter into the RAM IR (RAM = relational algebra machine). Unlike the declarative nature of Datalog programs, and thus the AST IR, the RAM IR is a imperative language describing the evaluation of a Datalog process in a step-by-step fashion. The conversion is based on a modified ''semi-naive'' evaluation scheme, which will be discussed below.
On the RAM level, mid-level optimisations are covered. The include the selection of an optimal set of indices for the processed relations, the determination of query-execution plans, and the interleaved interpretation of filter constraints.
Finally, in the subsequent execution phase the RAM program, combined with a set of input facts, is interpreted step by step according to its imperative semantic. The necessary operations are supported by a set of algorithms and data structures offering relational primitives. The interpretation of a program starts by loading facts from a set of input files (fact files), followed by the conduction of the actual evaluation of the Datalog query and a final step of writing the content of selected relations to the selected output destination, e.g. output files, or the console.
The engine's compiler mode is illustrated in the following image:

Its black-box external interface is identical to the interpreter mode: an input, consisting of a set of fact files and a Datalog program, is loaded, processed, and the results are written into output files. Furthermore, all the phases up until the execution phase are identical to the interpreter mode. However, instead of interpreting the RAM program within the engine's process, a C++ program encoding the RAM query is generated, compiled to an executable, and executed. Only the executable is addressing the fact file.
For its task the generated C++ program relies on the same relational primitives for conducting the necessary computations as the RAM interpreter above. However, a variety of specialisations of the involved data structures have been added to increase the performance of the resulting executable. Those optimisations exploit static knowledge about the conducted relational operations that can not be harnessed easily in the interpreter mode.
The compiler mode may also be instructed to produce the executable (or only the C++ source file) as an output, instead of the actual output data. This way, a given analysis can be compiled and applied on several data sets without the overhead of the compilation process.
All the steps involved in the above configurations are individual modules to be sequenced by some engine driver to fit the illustrated execution modes. This role is covered by the engine's ''main'' procedure, parsing command line options and running through the various stages as desired by the user. Correspondingly, command line flags can be utilised to switch between the two main modes as well as to customise the behaviour of some of the phases. For more information on the available options use the ''-h'' option of the engine executable.
The AST IR is the intermediate representation utilised for high-level analysis and transformations. It is produced by the parser and the input/output format of a variety of utilities. The AstUtils.h utility library offers a variety of tools to conduct analysis and manipulations on top of the AST. Furthermore, the AstVisitor class provides a convenient infrastructure for implementing concise inspection utilities and the AstNodeMapper -- a generic framework for AST manipulations.
The AST IR itself is constituted by a collection of classes within a class hierarchy. The hierarchy is rooted by the AstNode and sub-types are declared in the various Ast*.h files.
To obtain the AST representation of an input program, the static member function AstProgram::parse and AstProgram::parseFile can be utilised. Those functions will take some input, parse it and create an AstProgram instance to be utilised for further processing. Instances of AstProgram are the main entity for handling and manipulating Datalog programs within the AST phase of the compiler. They also control the life-time of all associated elements.
To validate the semantically sound composition of a parsed or manipulated program, the AstProgram::validate member function can be utilised.
Unlike the declarative AST representation, the RAM representation provides an imperative description of the operational steps required to compute the fix-point solution of a query. The RAM intermediate representation is essentially a limited, imperative programming language comprising variable declarations, conditions and loops, limited to a single data type -- relations. For this type, a series of relational operations, including merge operations, emptiness checks, scans, range queries and insertions, are offered. Each of those constructs, as well as a few auxiliary constructs, are represented through corresponding RAM nodes (see RamNode.h as well as other Ram*.h files).
As for the AST IR, a visitor infrastructure is provided (see RamVisitor.h).
An AST representation of an input program can be converted into a RAM representation by an instance of the RamTranslator. This converter is analysing the relations among the rules enumerated in the AST to determine a proper evaluation order. The chosen evaluation strategy is following a slightly modified version of the semi-naive evaluation approach to be found in any textbook covering Datalog.
The following subsections covers the various stages of the engine in detail, including hints regarding the corresponding source references.
The parsing includes the following components and steps:
- a flex/bison based parser; main files:
scanner.llandparser.yy - the utilisation of the C preprocessor (cpp) to handle macros, which is conducted by
maininmain.cpp - the invocation of the parser by the member functions
AstProgram::parseFileorAstProgram::parse - the finalisation of the parsing covering the instantiation of components by the function
AstProgram::finishParsing
The result of the parsing is a instance of an AstProgram. An example of the utilisation of the full parse process can be found in main.cpp, examples for parsing embedded strings (not including the pre-processor step) in the ast_program_test.cpp unit test.
The AST validation is triggered by a call to the function AstProgram::validate as demonstrated in main.cpp.
Besides others, the validation covers:
- the consistent definition of types (e.g. no references to undefined types)
- the consistent definition of rules (e.g. no usage of undefined relation name or usage of wrong number of argument terms)
- the consistent utilisation of components (e.g. no references to undefined components)
- the correct utilisation of variables (e.g. ensures variables can be typed and are grounded where necessary)
- the correct utilisation of string, integer and null constants
- the proper utilisation of negations and aggregates (stratification must be possible)
All those tests are covered in the implementation of AstProgram::validate utilising functionality offered by the AstVisitor infrastructure and AstUtils.
AST Optimisations and re-write operations are implemented by a set of passes. Each pass takes an AstProgram and modifies the program accordingly. The application of those optimisation passes is orchestrated in main.cpp. Those passes include:
- elimination of aliases by the function
removeAliases(see inAstUtils.h) - elimination of relation duplicates by function
removeRelationCopies - creation of auxiliary relations for sub-queries of aggregation terms (
materializeAggregationQueries) - elimination of empty relations (code inlined in
main.cpp) - elimination of unreferenced relations (code inlined in
main.cpp)
New passes may be added by providing an implementation of the pass and adding it to the list of passes executed by main.
An optional optimisation pass is running aiming to determine improved schedules for the involved clauses. The current infrastructure is following a profiling based approach. The processed program is executed by the interpreter, thereby recording dynamic properties of the processed relation at every rule invocation point. Based on this, a schedule is derived and the AST representation is transformed correspondingly.
This feature is implemented by the autotune function constituting another transformation pass (see main.cpp for its utilisation and AstTuner.h and AstTuner.cpp for its implementation).
The conversion from the declarative AST to the imperative RAM IR is conducted by the member functions of the RamConverter class. The conversion is following the semi-naive evaluation approach for which a description can be found an most introductory literature on Datalog. Essentially, starting from empty relations, the rules of a Datalog program are repeatedly evaluated on the current state of the relations to produce new tuples until no more tuples can be obtained. The resulting smallest fixpoint is the desired result.
Beside the converter's main task of converting a declarative Datalog AST into an imperative RAM representation, the converter is conducting a set of additional optimisations while doing so:
- it determines a minimal set of indices required for the resulting index-joins (auto-indexing)
- it schedules constraints to be evaluated within joins as soon as all referenced data is available
- it deduces and introduces necessary packing / unpacking operations for records
- it introduces profiling / logging operations (optional) Many of those tasks provide essential contributions to the performance of the resulting system.
A RAM program can be processed by in two modes: through an interpreter and a compiler. A common interface for any entity capable of executing a RAM program is given by the abstract RamExecutor. Implementations are given by
-
RamGuidedInterpreter an RAM program interpreter essentially consisting of a RAM visitor applying the effect of various RAM modes on a internally maintained execution environment. Instances can be equipped with a
QueryExecutionStrategyutilised for scheduling RAM queries (=index-joins) before they get executed. This enables a dynamic re-scheduling of queries based on run-time properties of the involved relations like their size. A specialisation of the RamGuidedInterpreter is also utilised by the auto-scheduler to trace performance characteristics. - RamInterpreter is a instance of the RamGuidedInterpreter not interfering with the schedule determined by the RamConverter
- RamCompiler converts the RAM program into C++ code, compiles the code and runs the resulting binary to obtain the desired result. Due to the compilation, a large variety of query properties, including relation arities, element orders, indices, iterator types, and access modes can be hard-coded, thus statically bound and optimised by the trailing C++ compiler. For realising relational operators a templated library of corresponding primitives is referenced.
All executors share a common interface and set of basic configuration options, which might be extended by the various specialisations (see RamExecutorConfig).
For computing the solution to Datalog queries Souffle utilises specialised data structures. The general requirements are:
- the representation of finite sets of same-sized integer tuples
- scalable to hundreds of millions or billions of entries
- efficient support for scans, range-queries, inserts, unions, membership and emptiness tests
- highest performance on contemporary and future architectures
To obtain highest performance the utilised data structures have to be (a) cache friendly and (b) support concurrent operations. For the latter, we can weak the requirement to support concurrent inserts or concurrent query operations. There will not be any ongoing scan or query operations while new data is inserted.
Within souffle two data structures have been implemented and tuned for representing relations:
- BTrees -- a cache friendly in-memory version of the widely known secondary storage data structure
- Bries -- a highly specialised trie based data structure incorporating ideas from Quad- and BTrees as well a BitMaps for achieving highest parallel performance
In the following more details on those data structures will be provided.
The BTree implementation is covered by the BTree.h header. Its foundation is the templated container detail::btree providing an efficient implementation for collections of PODs (plane old data types). Template parameters allow to determine the element type, the order utilised for sorting those elements, the size of blocks of the b-tree structure and whether the tree should support duplicates (for modelling multi-sets) or not (for modeling sets). The generic classes btree_set and btree_multiset provide corresponding wrappers.
The BTree implementation provides efficient implementations for insertion, query and scan operations. Each operation supports a user-provided operation context which will be utilised to store cached information enabling the tree implementation to exploit temporal locality among consecutive operation invocations.
For its utilisation in a parallel context the BTree implementation offers a synchronised insertion operation, allowing multiple threads to concurrently insert new elements. This synchronisation is based on an optimistic locking approach that has been demonstrated to provide acceptable scaling on a variety of target architectures.
The implementation of this data structure is covered by the Trie.h header. It is based on a trie utilising a quad-tree like structure within its nodes for managing links to nested levels. Furthermore, the leaf level re-assembles a BitMap like data structure, avoiding long sequences of zeros. As such, Bries are essentially representing compressed, higher-dimensional BitMaps.
Due to their design, insertion and membership operations can be conducted more efficient on Bries as an BTrees, for large relations. This is in particular due to the elimination of the necessity of binary searches within nodes and the necessity of moving blocks of data during insert operations. Furthermore, to provide proper synchronisation for concurrent insert operations, atomic updates are sufficient. Consequently, Bries can be synchronised in a lock-free fashion, leading to superior parallel scalability.
The down side of the Brie is its memory requirements. In general Bries require much more memory than BTrees. Only for data exhibiting a critical spatial density the utilised compression can lead to a reduction of the memory requirement compared to the BTree approach. However, this property could be observed for large-scale, static program analysis -- souffle's major application domain.
Souffle's interpreter is strictly based on BTrees storing pointers to actual tuples. This design is imposed due to technical restrictions of an interpreting environment and the resulting required flexibility. The corresponding data structure wrapper is given by the RamRelation.
Souffle's RAM compiler on the other hand utilises a mixture of direct indices consisting of BTrees storing actual tuples, indirect indices storing pointers to tuples contained in other structures and Brie based indices for relations of small arty (up to 2). The organising data structure is a templated Relation class as defined in CompiledRamRelation. This header also manages the selection of the type of data structures to be utilised for the various use cases (relations and indices), mainly through the index_factory type trait.

A Souffle Program consists of Non-Recursive and Recursive Relations which are made up of one or more Non-Recursive and Recursive Rules respectively. Recursive Rules and Recursive Relations execute in one or more Iterations. The performance characteristics of a Relation or Rule consists of the following: runtime, recursive runtime, non-recursive runtime, merge time and number of tuples produced. Recursive Rules can be made up of different versions.

The log files that SouffleProf reads must follow the format shown above.
- Cell - An object holder to be inserted into a Table Row
- Cli - Controls the launching of SouffleProf
- DataComparator - Comparator functions for sorting tables
- html_string - Holds the HTML/JS string for the GUI
- Iteration - Data class for Iterations
- OutputProcessor - Controls data to table conversion
- ProgramRun - Data class of the Program Run
- Reader - Parses log file and generates data model (both offline/live)
- Relation - Data class for Relations
- Row - Holder for a vector of Cell objects of different types
- Rule - Data class for Rules
- StringUtils - A series of functions for string manipulation/file system
- Table - Holds a vector of Rows and sorts them
- Tui - Controls the Text User Interface
- UserInputReader - Controls user input for tab completion/history