Archive
A typical enterprise Data Center (DC) is driven by the ITSM Change Management with a careful planning of the infrastructure. An overview to get the idea how typically services are built at Architecture and Change Management and how process looks like, can be found on Open Group Portal (PDF).
Constantly growing number of managed machines will eventually grow up even more. Therefore Salt is required to handle a vast amount of machines, while meet the requirements for a typical DC run. Due to the nature of various SUSE products, at least the following specifications needs to be met:
-
Change the configuration on the machines within a certain period of time.
This is a typical maintenance window, where N amount of machines needs to be updated per a specific time and so such operation must be finished within its boundaries.
-
Handle the resulting data of managed machines in the way so the other 3rd party systems can be equally integrated
In this case Salt needs to organise the data in the way that any 3rd party application should be able to cope with that amount of obtained data.
-
Allow horizontal scalability into a grid/cluster
Horizontal scalability allows to add more machine nodes that aren't necessary very powerful, as it is done in vertical scalability by adding more hardware. Grid layout would allow to certain vital points stay available after the impacts. In general, we should aim to be able to handle "infinite" amount of minions, where limits would be only hardware.
-
Be 3rd party app agnostic in doing previous requirements
Salt should not rely on a specific 3rd party application that becomes a direct dependency in order to perform data organising and handling, so it allows to build an infrastructures with desired components.
-
Multitenancy support
Salt should provide access to a different organizations under such setup and isolation between them.
By "fully processed" it means that three kind of information data state went through the full circle. That is:
- Requesting information (what a Minion should do) has been sent from Master to Minion
- Returning meta-data (about what Minion has been done) has been sent from Minion to Master
- Returned data (result of Minion job) has been sent from Minion to Master
With only one Master, Salt hits the limits of amount of machines that can be fully processed within a certain amount of time. So even if Salt Manager will fully process an N amount of minions, it still won't make it to fully process it within certain period of time and therefore won't meet the requirements for the ITSM Change Management.
As in any grid/cluster solutions, the complexity needs to be separated into a smaller parts.
Each Master machine has its limits to the certain amount of Minions. However, these limits are not static, are different from case to case and are not permanent. E.g., a Mainframe can be slower than a Raspberry Pi machine, because it "decided so" at the moment. But a server can perform slower on IO but faster on CPU and vice versa.
Minions can be connected to a multiple Master(s) machines. There are two ways of doing it:
- Hot-hot. Where everything is connected to everything. This allows high availability, but this doesn't scale.
- Random/selective. This allows a shard of minions from a general swamp to be connected to a different Master instance, this way reducing an amount of minions per a Master. However, the downside of this is that each Master needs to be operated separately.
The amount of prepared data from Salt for such applications and service is a problem of those applications and services. Salt should not take care if an application is about to collapse, because it is incapable to process prepared data. Solution to this: scale that application. However, Salt must take care of stale/obsolete prepared data and swipe it away if it gets old, so the storage buffer stays always fresh.
Salt between the meta-information about jobs done, it also can return a vast amount of data from the Minions. The data in this case is not understood as an information, but just a data for further processing by a 3rd party applications. The first bottleneck to solve is to make sure that the controlling information (i.e. commands and meta-data or a description) is separated from the payload returning response. First stays within ZMQ channel inside the Salt, the second is returned in a storage for further processing.
On the figure below blue lines depicts a command information, and red means returning data of the performed results:
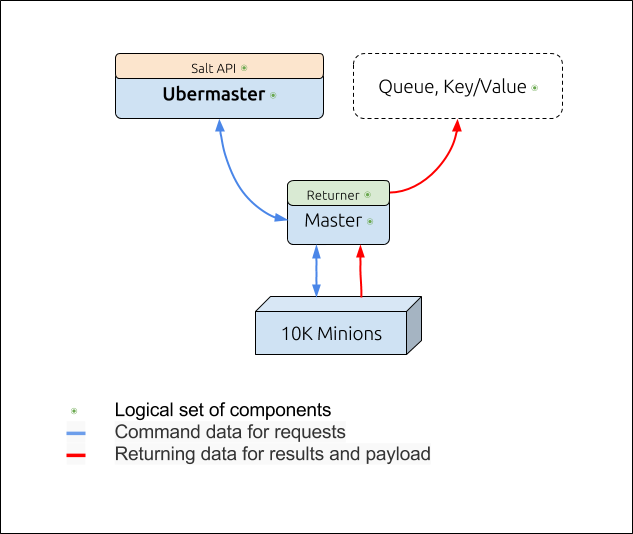
-
Ubermaster in this figure is a control centre, a "master of masters", where "child master to ubermaster" is like "minion to master" relation. That would mean that "child masters" are nothing else but an extended Syndic Masters that can:
- proxy-pass commands between the end minions and the Ubermaster.
- keep track which minion belongs to what child-master
- register minions
- provides standard Salt API and so the whole setup should be equally transparent to the existing one
In this scenario, child-master is a fully-automated instance and no manual work is expected to be done on it.
-
"Logical set" means that those components aren't physical, i.e. actually it can be more than one machine or node or an instance.
-
"Queue, Key/Value" (store) is a horizontally scalable component behind the necessary setup. For example, Redis. Concept currently does not shows how to secure such store component, Redis in particular. Because it might be some other implementation etc. As a possible solution, there could be a REST API over HTTPS with the authentication in front of such component with only one function
put.
In such architecture, requesting data and meta-data are still returned back to the Master and thus to the Ubermaster via ZMQ as usual. However, the amount of such data is way smaller than usually, as the main returned content is not flowing through these channels between the Ubermaster and Master, although still returned between the Master and the Minion(s). The Child master returns such data to the key/value store instead. This allows to add as much as possible sets of "child-master + N minions" and each of such sets returns their data to a horizontally scalable Key/Value store.
Figure below shows the layout of two such sets (Child-Master and corresponding a swamp of minions):

As an example, the layout of the Key/Value store not necessary needs to be on an isolated machines. Since it supposed to consist of a multiple instances/nodes, each node can run directly nearby the Child Master and so the 3rd party application can "talk" to a broker that connects to all of those instances. That said, amount of Child Masters equals to amount of Key/Value store scaled nodes behind such broker (not pictured on the figure above).
Such layout also is flexible for grouping minions, i.e. 1~N child masters per an organization or subnet etc. Essentially, "child master" is not very much different from the existing Syndic. However, it still does not separates the data into a different channels and does not work fully transparent so the minion registration can be done in the control node.
Any service or application that is going to integrate with this setup is either need to cope with the returned amount of data that sits in such Key/Value store as well as provide other 3rd party services to which minions are connected. In any case, integration of the resulting data is not designed to be a realtime as it doesn't have to be. That said, 3rd party applications are essentially controlling/displaying entities, that have the following obligations:
- Schedule a command(s) across N amount of Minions
- Optionally define the time when this has to be done
- At some point fetch already prepared data from the Key/Value store and empty it for the next iteration
Figure below gives an example how such layout can be achieved:

Because of the ability to operate multiple Child Masters, the Child Masters are isolated from each other and do not have any connections in between. That said, they are not "talking" to each other, but can be in different LANs, subnets, Data Centers etc. That would allow to have a multi-tenant control node (Ubermaster) that would provide ACL for a different organization that would have an access to their minions as end-points.
- What else could be used except the Redis? See the references for possible alternatives.
- Do we need an API in front of any case of #1 (Redis or something else)?
- How do we obsolete prepared data for a 3rd party app?
- Library for API in front of Redis: http://python-rq.org
- OpenStack queue: https://wiki.openstack.org/wiki/Zaqar
- Distributed task queue: http://www.celeryproject.org
- Redis: https://redis.io