Experiment tracking for XGBoost-trained models.
- Log, organize, visualize, and compare ML experiments in a single place
- Monitor model training live
- Version and query production-ready models and associated metadata (e.g., datasets)
- Collaborate with the team and across the organization
- metrics,
- parameters,
- learning rate,
- pickled model,
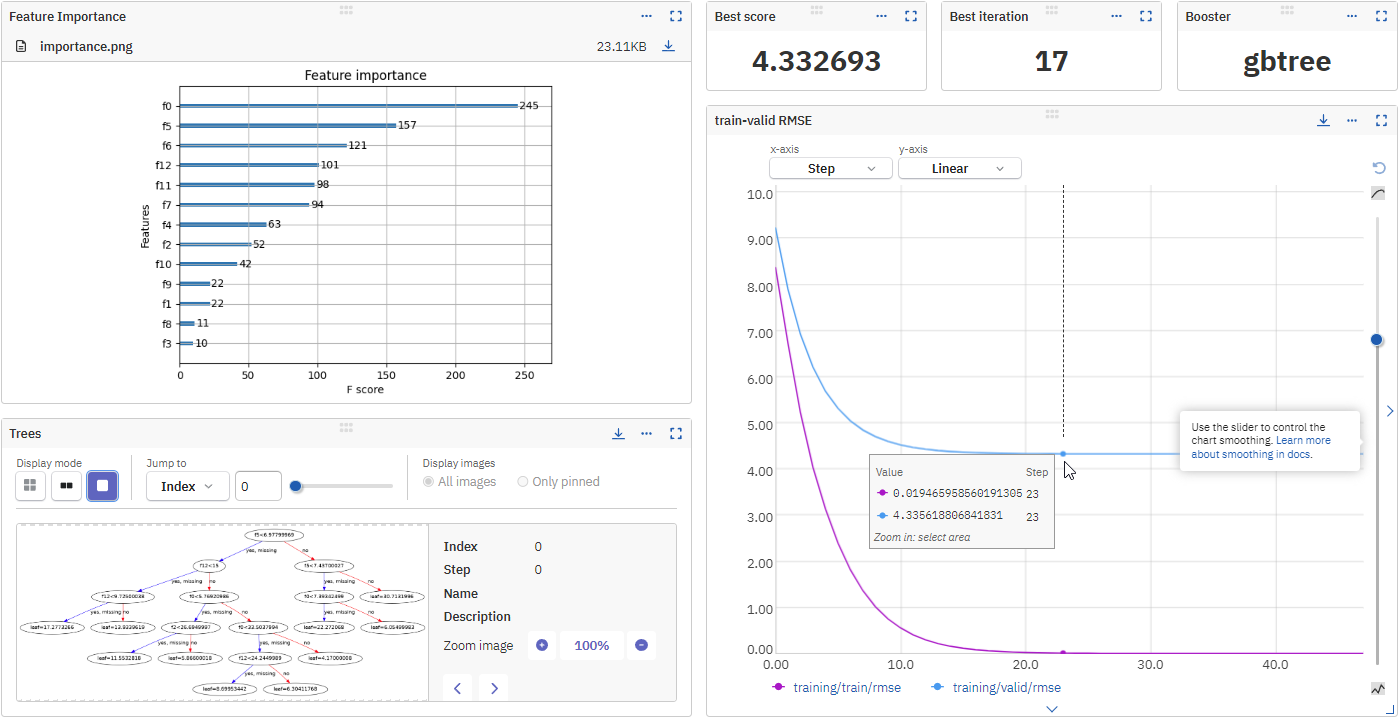
- visualizations (feature importance chart and tree visualizations),
- hardware consumption (CPU, GPU, Memory),
- stdout and stderr logs,
- training code and Git commit information,
- other metadata
- Documentation
- Code example on GitHub
- Example of a run logged in the Neptune app
- Run example in Google Colab
On the command line:
pip install xgboost>=1.3.0 neptune-xgboost
In Python:
import neptune
import xgboost as xgb
from neptune.integrations.xgboost import NeptuneCallback
# Start a run
run = neptune.init_run(
project="common/xgboost-integration",
api_token=neptune.ANONYMOUS_API_TOKEN,
)
# Create a NeptuneCallback instance
neptune_callback = NeptuneCallback(run=run, log_tree=[0, 1, 2, 3])
# Prepare datasets
...
data_train = xgb.DMatrix(X_train, label=y_train)
# Define model parameters
model_params = {
"eta": 0.7,
"gamma": 0.001,
"max_depth": 9,
...
}
# Train the model and log metadata to the run in Neptune
xgb.train(
params=model_params,
dtrain=data_train,
callbacks=[neptune_callback],
)If you got stuck or simply want to talk to us, here are your options:
- Check our FAQ page
- You can submit bug reports, feature requests, or contributions directly to the repository.
- Chat! When in the Neptune application click on the blue message icon in the bottom-right corner and send a message. A real person will talk to you ASAP (typically very ASAP),
- You can just shoot us an email at [email protected]