
CLIP is able to connect the meaning of a text with the meaning of an image. It converts the image into a long list of numbers. It also converts the text into a long list of numbers. Now that we only have numbers (hundreds of them!), we can compare both lists and check if the meaning of the text is similar to the meaning of the image. We can ask CLIP if a dog is in the image so we don't have to check every image manually. For building CLIP, the system was teached with millions of images with its description, so it could learn from the examples.
CLIP (Contrastive Language–Image Pre-training) is a neural network which efficiently learns visual concepts from natural language supervision, through the use of Contrastive Learning. It can be used as a classification tool where we can compare the embeddings of an image
Links:
- CLIP: Connecting Text and Images
- CLIP paper on Arxiv: Learning Transferable Visual Models From Natural Language Supervision
- The Beginner’s Guide to Contrastive Learning
- Research resources for CLIP from Zhuoning Yuan
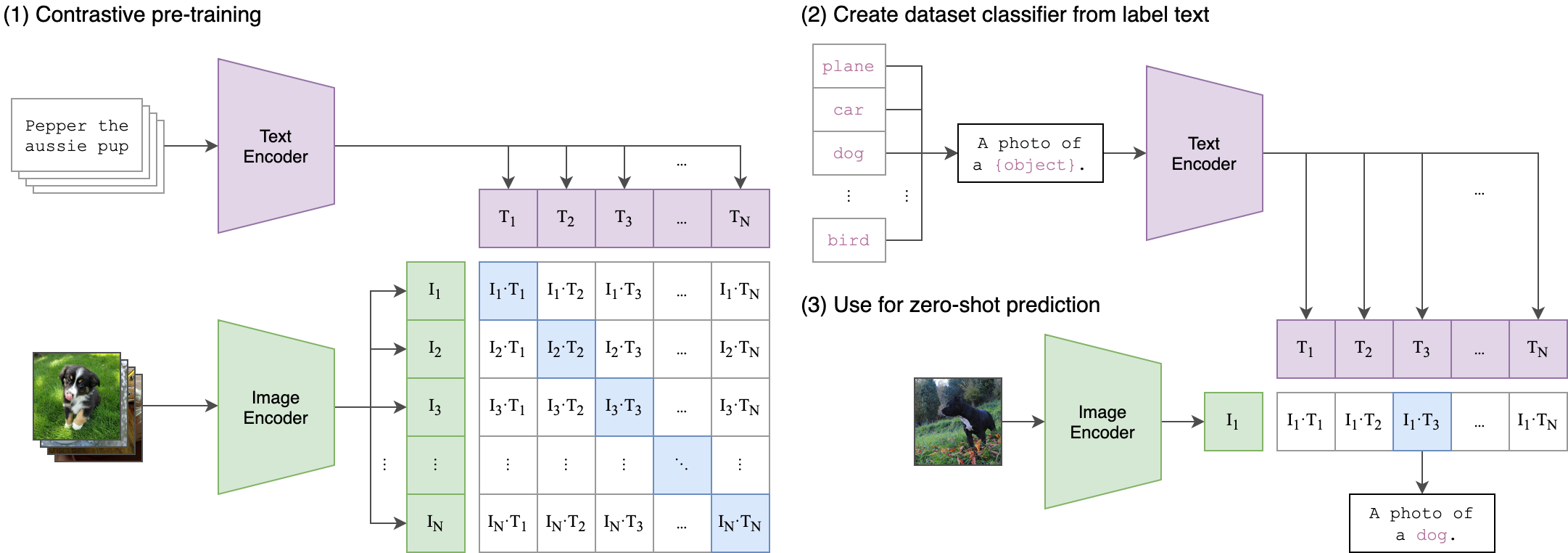 |
|---|
| Image Credit: https://github.com/openai/CLIP |
As seen in the picture above, during the pre-training phase, both encoders (image and text) are trained with image-text pairs and incentivized to create similar representations for the corresponding pairs (and not similar for the negative examples). For using CLIP as a Zero-Shot classifier, one will create a text that defines the class, and the will obtain its representation with the text encoder. Finally, the representation of the image is compared with each class with some distance metric (i.e. cosine similarity) and we can select the class that is closest.
There are many versions of CLIP. We could say that nowadays the term "CLIP" is more of a concept. In Huggingface there are now around one thousand models that has CLIP in its name. Most of them are fine-tuned versions of the original, but there are also new approaches, for example we find SigLIP that replaces the loss function used in CLIP by a simple pairwise sigmoid loss.
CLIP is a OpenAI product and it is available at Github but we will be using an alternative that's been trained on LAION (Large-scale Artificial Intelligence Open Network) and that provides multiple ViT sizes. OpenCLIP is provided by mlfoundations in the following repo: https://github.com/mlfoundations/open_clip.
LAION is a non-profit organization that provides datasets, tools and models to liberate machine learning research. In particular, for openCLIP, it's the dataset provider for the most downloaded model, with LAION-2B (the English subset of LAION-5B). You can find the models in HuggingFace.
It's relevant to note that a CLIP models will be expecting a short description for the image, based on the distribution of the descriptions in the training dataset. There's an interesting work around this and the concept of "effective length": the paper "Long-CLIP: Unlocking the Long-Text Capability of CLIP" (https://lnkd.in/dky8Hf8N) puts it around 20 tokens, and concludes: "This is because the majority of training texts are likely to be considerably shorter than 77 in the original CLIP model". In fact, in the following graph one can check the quantiles for the length of the text associated with the images:
 From: https://laion.ai/blog/laion-5b/#dataset-statistics
From: https://laion.ai/blog/laion-5b/#dataset-statistics
But this is not something we cannot modify, even with the bias on the dataset there are workarounds. Check the repo at https://github.com/facebookresearch/DCI (includes code to reproduce the paper A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions)
When preparing the model for inference, we can experience a very smooth learning curve. We can start with a python file that executes the model as-is, and then take small steps towards a more efficient approach. In this repo we will be using CLIP retrieval for batch inference and NVIDIA Triton Inference Server for online inference. For the online inference we will convert the model into ONNX and TensorRT, with reduced precision (FP16, INT8). Remember it's necessary to conduct benchmarking again when you modify the model.
- clip-as-service.Scalable embedding, reasoning, ranking for images and sentences with CLIP, from Jina AI.
- CLIP retrieval. Easily compute clip embeddings and build a clip retrieval system with them. 100M text+image embeddings can be processed in 20h using a 3080.
In this section I will experiment with some ideas around CLIP and will provide the notebooks.
| Demo | Description |
|---|---|
| How cosine similarity of CLIP embeddings decrease linearly with the number of pixels replaced by a grey pixel and how a different preprocessing method can drop cosine similarity by a lot | |
| CLIP activations (in the ViT, just after the GELU) change progressively from noise to image, and how in the first block the dynamics are the opposite of the last block. | |
| How CLIP reacts to different noise types. | |
| As we approach the final layers, sparsity emerges, hinting an hierarchical learning, with more abstract concepts at these layers. And the last layer is dense again, pushed by gradient flows. | |
| An example of adversarial machine learning, where we can trick CLIP into not recognizing a car by changing the value of just a few pixels . |
-
Vision Transformer (ViT) Prisma Library is an open-source mechanistic interpretability library for vision and multimodal models based on TransformerLens from Neel Nanda.
-
CLIP-Dissect is an automatic and efficient tool to describe functionalities of individual neurons in DNNs.
-
X-CLIP A concise but complete implementation of CLIP with multiple experiments
CLIP is nowadays more of a concept, and many models are based on the original idea but with a different approach.
-
SigLIP replaces the loss function used in CLIP by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet.
-
TULIP Method to upgrade the caption length of CLIP-like models to perform long caption understanding
-
A Picture is Worth More Than 77 Text Tokens: Evaluating CLIP-Style Models on Dense Captions)