4.6 并行化
Hawk使用了线程池的机制,可以设置最大工作线程数,只有之前的工作线程完成工作,才会填入新的任务。否则过多的线程会迅速占用所有系统资源。
你可以在数据清洗的 执行面板中,合理选择线程数,选择串行和并行模式,之后点击启动即可。

注意: 点击执行后,为了保证执行过程不受干扰,建议不要再修改各个模块的参数,此时刷新结果按钮无效,要想重新强制刷新,必须保证当前工作流停止生成数据,可参考本文档【任务管理】一节。
相比于Hawk2, Hawk3会自动分析可以并行的位置,因此多数情况下,直接运行就可以了。但是如果你想自定义并行化的行为,就需要阅读下面的内容。
在调试模式下,所有获取都是串行的。而执行模式下,执行器才会执行。为了更好地理解并行化,强烈建议阅读下面的内容。
我们以抓取某个网站的100个页面为例,第一个模块生成区间数,可以生成1-100的页面,自然地,就可以创建100个任务,分别抓取了。
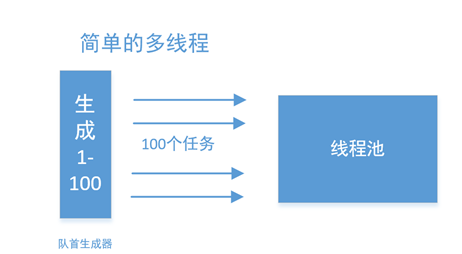
但是,但如果队首的生成器只生成了很少的元素,每个元素在后期,又会转换为大量的元素,那么这种方法就非常低下了。极端情况下队首生成器只生成一个元素,则并行化就毫无意义:

一种非常简单的思路,是将其切成两个任务,并行在任务中完成。
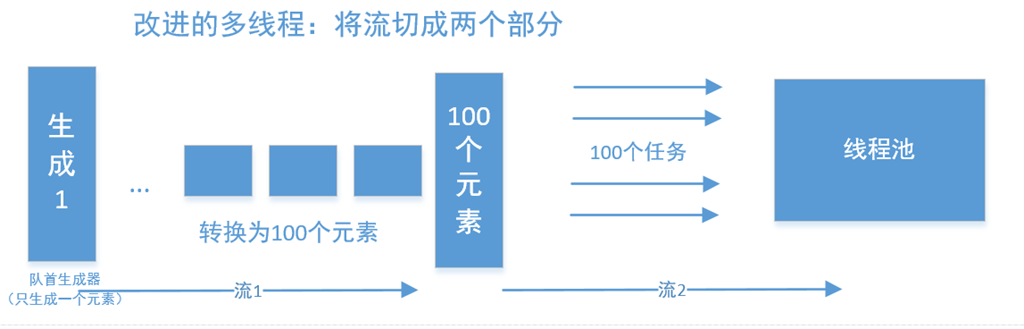
我们将其看成两个任务,第一个任务,负责产生出一堆种子任务出来,并加入到任务队列,之后再在这些种子的基础上,再分别调用第第二个任务。
如何切分任务?取决于你在任务中插入的并行的位置。这个位置就是切分为两个任务的“切割点”。
以大众点评为例, 北京有14个区县,有30种美食类型,如果直接在区县后插入并行,则只有14个子任务,任务数量太少:那么先通过任务1,获取420个元素,再以420个元素的基础上,插入并行,这样速度就快很多了。你也可以在14个区县之后插入并行化,那么就有14个子任务。
反过来,如果每个任务的工作量太少,比如只访问一次网站内容,则这样的种子创建并行就显得过分地成本高昂,因此可以填写分组并行数量,比如10,那么Hawk就会以10个元素为一组,创建任务。
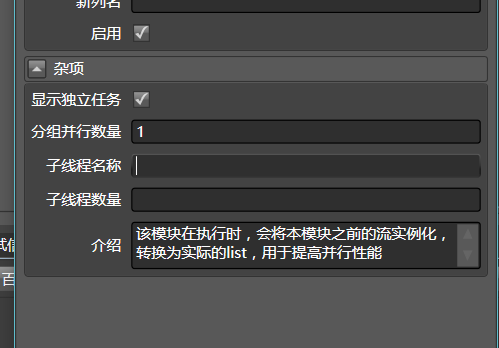
任务管理器中,可以显示任务的名称,以及进度。这样可以方便监控。
子线程名称和子线程数量,都支持直接写值,或使用方括号表达式来获取别的列的内容。例如,如果你确定每个子任务都会获取100条数据,就可以在子线程数量中填写100,之后当该任务获取了50个元素时,进度条正好处在50%的位置。如果有一列名为“小区名”, 则可以在子线程名称栏目中填写[小区名] ,Hawk就会把小区名列中的内容作为子任务的名称。
你可以随时在执行过程中,暂停或取消所有任务。
五个按钮依次为:全选,反选,暂停,启动,删除。