Detect objects in images without training!
Welcome to the CLIP Zero-Shot Object Detection project! This repository demonstrates how to perform zero-shot object detection by integrating OpenAI's CLIP (Contrastive Language-Image Pretraining) model with a Faster R-CNN for region proposal generation.
| Source Code | Website |
|---|---|
| github.com/deepmancer/clip-object-detection | deepmancer.github.io/clip-object-detection |
Set up and run the pipeline in three simple steps:
-
Clone the Repository:
git clone https://github.com/deepmancer/clip-object-detection.git cd clip-object-detection -
Install Dependencies:
pip install -r requirements.txt
-
Run the Notebook:
jupyter notebook clip_object_detection.ipynb
CLIP (Contrastive Language–Image Pretraining) is trained on 400 million image-text pairs. It embeds images and text into a shared space where the cosine similarity between embeddings reflects their semantic relationship.
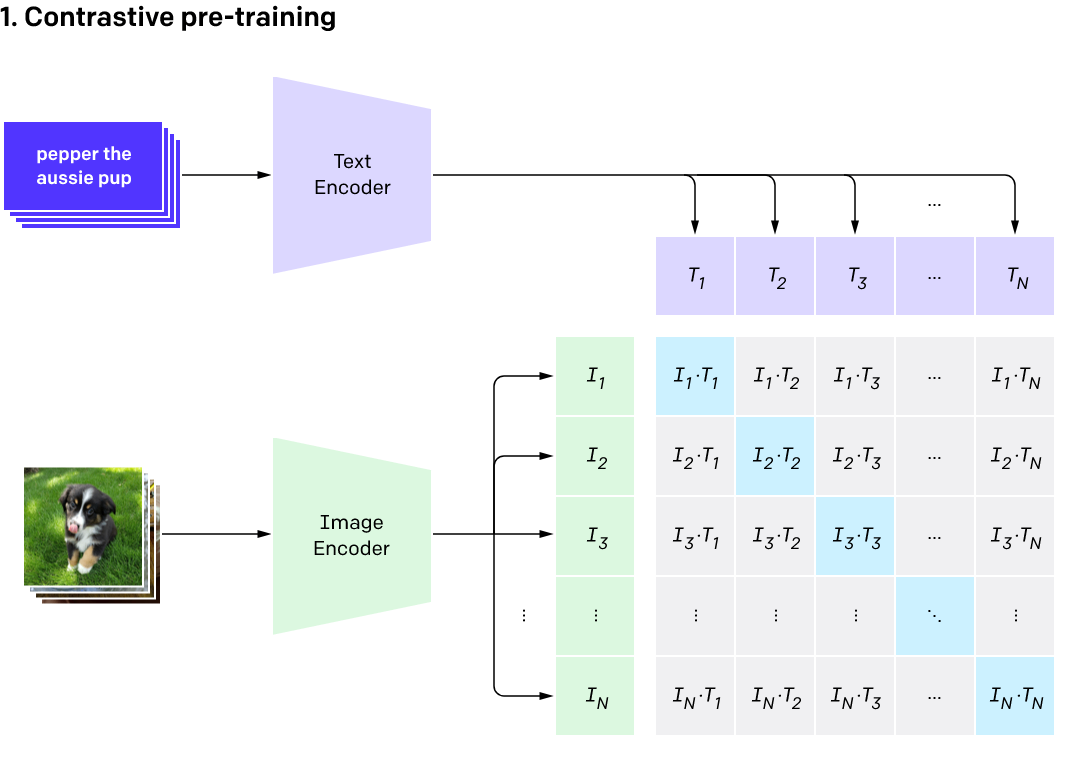 CLIP Model Architecture - Paper
CLIP Model Architecture - Paper
Our approach combines CLIP and Faster R-CNN for zero-shot object detection:
- 📦 Region Proposal: Use Faster R-CNN to identify potential object locations.
- 🎯 CLIP Embeddings: Encode image regions and text descriptions into a shared embedding space.
- 🔍 Similarity Matching: Compute cosine similarity between text and image embeddings to identify matches.
- ✨ Results: Highlight detected objects with their confidence scores.

Regions proposed by Faster R-CNN's RPN:

Objects detected by CLIP based on textual queries:

Ensure the following are installed:
- PyTorch: Deep learning framework.
- Torchvision: Pre-trained Faster R-CNN.
- OpenAI CLIP: GitHub Repository.
- Additional dependencies are listed in requirements.txt.
This project is licensed under the MIT License. Feel free to use, modify, and distribute the code.
If this project inspires or assists your work, please consider giving it a ⭐ on GitHub! Your support motivates us to continue improving and expanding this repository.