学习python时,爬虫是一种简单上手的方式,应该也是一个必经阶段。本项目用Scrapy框架实现了抓取豆瓣top250电影,并将图片及其它信息保存下来。爬取豆瓣top250电影不需要登录、没有JS解析、而且只有10页内容,用来练手,太合适不过了。
- WIN10 64位系统
- Python 3.6.1
- PyCharm、Sublime Text
- Mysql、MongoDB,可视化:DbVisualizer、Robomongo
- spiders/sp_douban.py:处理链接,解析item部分
- items.py:豆瓣top250电影字段
- middlewares.py、user_agents.py:从维护的UserAgent池中随机选取
- settings.py:配置文件
- main.py:免去在命令行输入运行指令
入口地址:https://movie.douban.com/top250


如图所示,抓取信息对应如下:
class DoubanTopMoviesItem(scrapy.Item):
title_ch = scrapy.Field() # 中文标题
# title_en = scrapy.Field() # 外文名字
# title_ht = scrapy.Field() # 港台名字
# detail = scrapy.Field() # 导演主演等信息
rating_num = scrapy.Field() # 分值
rating_count = scrapy.Field() # 评论人数
# quote = scrapy.Field() # 短评
image_urls = scrapy.Field() # 封面图片地址
topid = scrapy.Field() # 排名序号用xpath取出对应路径,进行必要的清洗,去除空格等多余内容:
item['title_ch'] = response.xpath('//div[@class="hd"]//span[@class="title"][1]/text()').extract()
en_list = response.xpath('//div[@class="hd"]//span[@class="title"][2]/text()').extract()
item['title_en'] = [en.replace('\xa0/\xa0','').replace(' ','') for en in en_list]
ht_list = response.xpath('//div[@class="hd"]//span[@class="other"]/text()').extract()
item['title_ht'] = [ht.replace('\xa0/\xa0','').replace(' ','') for ht in ht_list]
detail_list = response.xpath('//div[@class="bd"]/p[1]/text()').extract()
item['detail'] = [detail.replace(' ', '').replace('\xa0', '').replace('\n', '') for detail in detail_list]
# 注意:有的电影没有quote!!!!!!!!!!
item['quote'] = response.xpath('//span[@class="inq"]/text()').extract()
item['rating_num'] = response.xpath('//div[@class="star"]/span[2]/text()').extract()
# 评价数格式:“XXX人评价”。用正则表达式只需取出XXX数字
count_list = response.xpath('//div[@class="star"]/span[4]/text()').extract()
item['rating_count'] = [re.findall('\d+',count)[0] for count in count_list]
item['image_urls'] = response.xpath('//div[@class="pic"]/a/img/@src').extract()
item['topid'] = response.xpath('//div[@class="pic"]/em/text()').extract()第二页的链接格式是:https://movie.douban.com/top250?start=25&filter= ,每页25部电影,所以翻页就是依次加25
- 重写start_requests方法
base_url = "https://movie.douban.com/top250"
# 共有10页,格式固定。重写start_requests方法,等价于start_urls及翻页
def start_requests(self):
for i in range(0, 226, 25):
url = self.base_url + "?start=%d&filter=" % i
yield scrapy.Request(url, callback=self.parse)- 初始start_urls加当前页的下一页
base_url = "https://movie.douban.com/top250"
start_urls = [base_url]
# 取下一页链接,继续爬取
new_url = response.xpath('//link[@rel="next"]/@href').extract_first()
if new_url:
next_url = self.base_url+new_url
yield scrapy.Request(next_url, callback=self.parse)- 初始start_urls加LinkExtractor 链接提取器方法
# 这个方法需要较大调整(引入更多模块、类继承CrawlSpider、方法命名不能是parse)
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
base_url = "https://movie.douban.com/top250"
start_urls = [base_url]
rules = [Rule(LinkExtractor(allow=(r'https://movie.douban.com/top250\?start=\d+.*')),
callback='parse_item', follow=True)
]综合其他人的教程,本项目集成了多种保存方法,包括保存电影封面至本地、存入MYSQL、存入MONGODB。在settings里配置了ITEM_PIPELINES,用到那种方式,就把注释去掉即可。
-
自定义下载图片方法
# 自定义方法下载图片 class FirsttestPipeline(object): # 电影封面命名:序号加电影名 def _createmovieImageName(self, item): lengh = len(item['topid']) return [item['topid'][i] + "-" + item['title_ch'][i] + ".jpg" for i in range(lengh)] # 另一种命名法,取图片链接中名字 # def _createImagenameByURL(self, image_url): # file_name = image_url.split('/')[-1] # return file_name def process_item(self, item, spider): namelist = self._createmovieImageName(item) dir_path = '%s/%s' % (settings.IMAGES_STORE, spider.name) # print('dir_path', dir_path) if not os.path.exists(dir_path): os.makedirs(dir_path) for i in range(len(namelist)): image_url = item['image_urls'][i] file_name = namelist[i] file_path = '%s/%s' % (dir_path, file_name) if os.path.exists(file_path): print("重复,跳过:" + image_url) continue with open(file_path, 'wb') as file_writer: print("正在下载:"+image_url) conn = urllib.request.urlopen(image_url) file_writer.write(conn.read()) file_writer.close() return item
-
保存内容至MYSQL数据库
前提是装好mysql,这部分请自行解决。本项目建表语句:
CREATE TABLE DOUBANTOPMOVIE ( topid int(3) PRIMARY KEY , title_ch VARCHAR(50) , rating_num FLOAT(1), rating_count INT(9), quote VARCHAR(100), createdTime TIMESTAMP(6) not NULL DEFAULT CURRENT_TIMESTAMP(6), updatedTime TIMESTAMP(6) not NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
具体实现方法:
# 保存内容至MYSQL数据库 class DoubanmoviePipeline(object): def __init__(self, dbpool): self.dbpool = dbpool @classmethod def from_settings(cls, settings): dbparams = dict( host=settings['MYSQL_HOST'], port=settings['MYSQL_PORT'], db=settings['MYSQL_DBNAME'], user=settings['MYSQL_USER'], passwd=settings['MYSQL_PASSWD'], charset=settings['MYSQL_CHARSET'], cursorclass=MySQLdb.cursors.DictCursor, use_unicode=False, ) dbpool = adbapi.ConnectionPool('MySQLdb', **dbparams) # **表示将字典扩展为关键字参数 return cls(dbpool) # pipeline默认调用 def process_item(self, item, spider): # 调用插入的方法 query=self.dbpool.runInteraction(self._conditional_insert,item) # 调用异常处理方法 query.addErrback(self._handle_error,item,spider) return item def _conditional_insert(self, tx, item): sql = "insert into doubantopmovie(topid,title_ch,rating_num,rating_count) values(%s,%s,%s,%s)" lengh = len(item['topid']) for i in range(lengh): params = (item["topid"][i], item["title_ch"][i], item["rating_num"][i], item["rating_count"][i]) tx.execute(sql, params) def _handle_error(self, e): print(e)
-
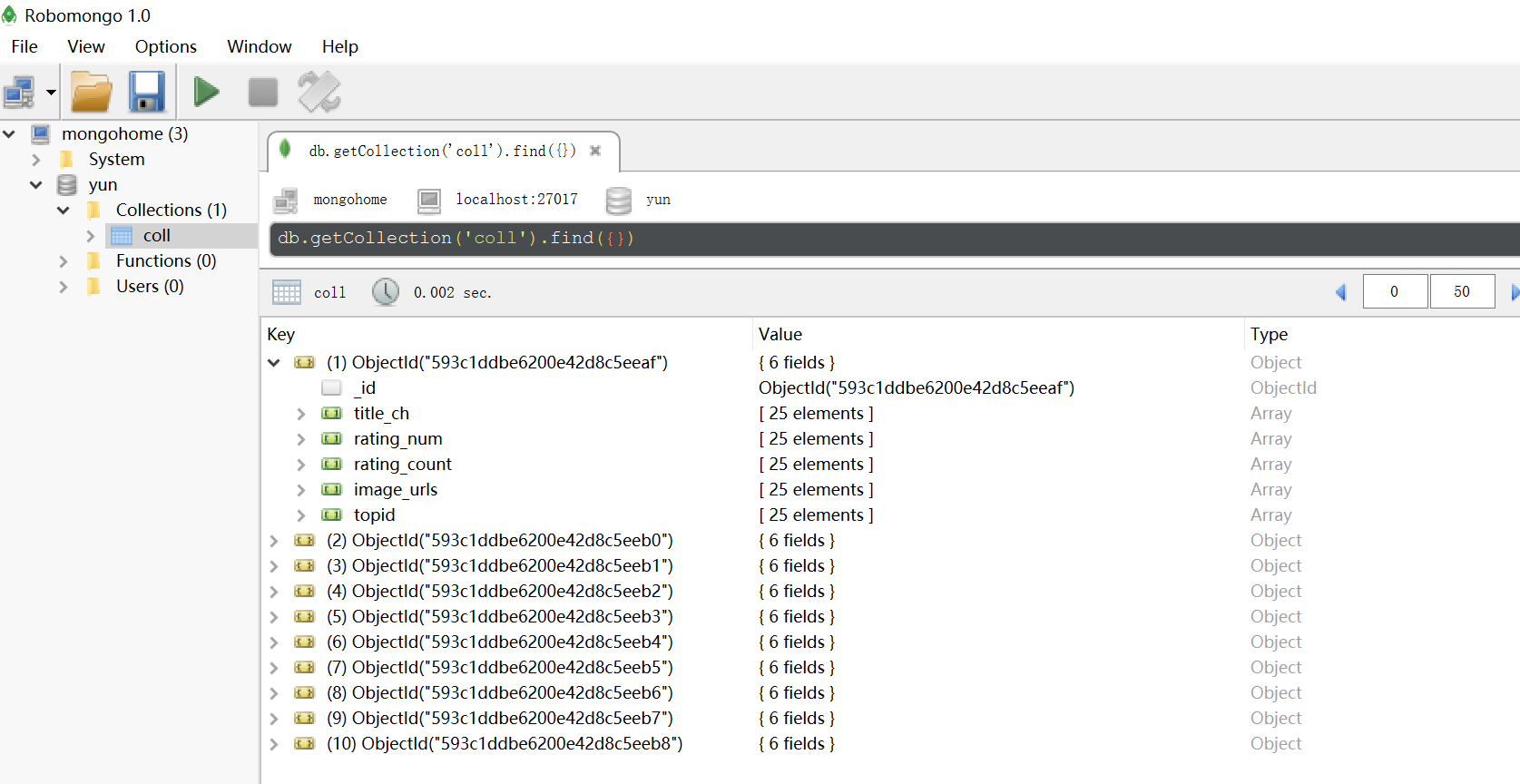
保存内容至MONGODB数据库
前提是装好mongodb,这部分请自行解决。可视化工具推荐Robomongo,本项目保存结果及实现方法:
# 保存内容至MONGODB数据库 class MongoDBPipeline( object): mongo_uri_no_auth = 'mongodb://localhost:27017/' # 没有账号密码验证 database_name = 'yun' table_name = 'coll' client = MongoClient(mongo_uri_no_auth) # 创建了与mongodb的连接 db = client[database_name] table = db[table_name] # 获取数据库中表的游标 def process_item(self, item, spider): valid = True for data in item: if not data: valid = False raise DropItem("Missing {0}!".format(data)) if valid: self.table.insert(dict(item)) return item
-
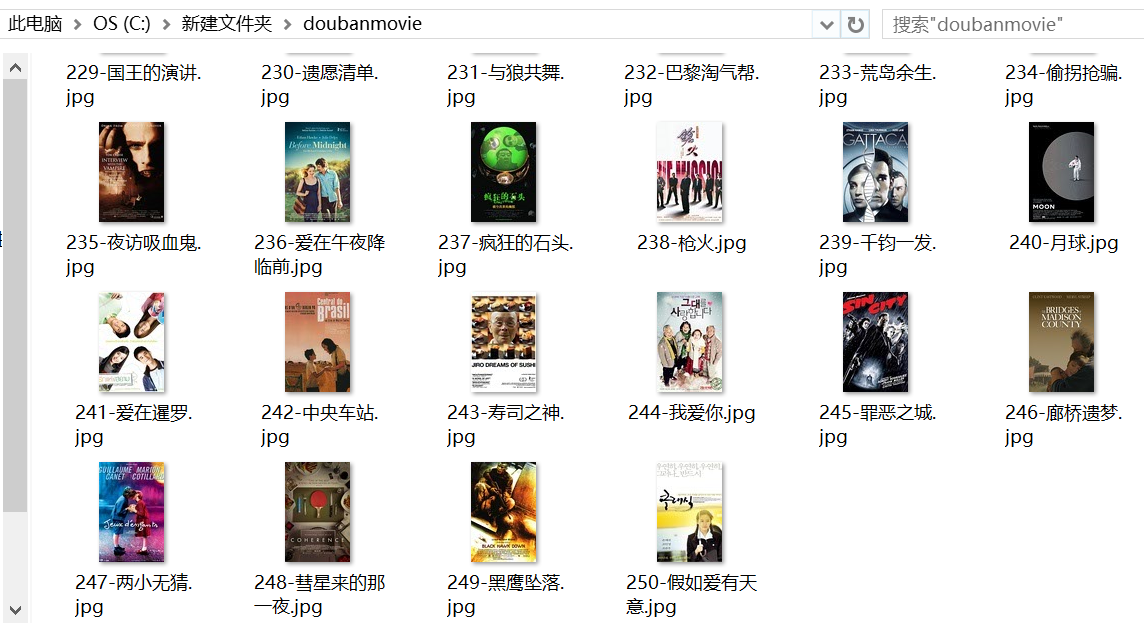
用内置的ImagesPipeline类下载图片
Scrapy自带的ImagesPipeline 实现起来也很简单。不过,比较下来,速度不及自定义的方法,不知是否哪里写的不对。若有高手发现,欢迎指出原因。
from scrapy.contrib.pipeline.images import ImagesPipeline from scrapy.http import Request from scrapy.exceptions import DropItem # 用Scrapy内置的ImagesPipeline类下载图片 class MyImagesPipeline(ImagesPipeline): def file_path(self, request, response=None, info=None): image_name = request.url.split('/')[-1] return 'doubanmovie2/%s' % (image_name) # 从item获取url,返回request对象给pipeline处理 def get_media_requests(self, item, info): for image_url in item['image_urls']: yield Request(image_url) # pipeline处理request对象,完成下载后,将results传给item_completed def item_completed(self, results, item, info): image_paths = [x['path'] for ok, x in results if ok] # print(image_paths) if not image_paths: raise DropItem("Item contains no images") # item['image_paths'] = image_paths return item
from scrapy.selector import Selector
Selector(response).xpath('//span/text()').extract()
# 等价于下面写法:
response.selector.xpath('//span/text()').extract() # .selector 是response对象的属性
# 也等价于下面写法(进一步简化):
response.xpath('//span/text()').extract()完整项目代码见Github
觉得对你有所帮助的话,给个star :eight_pointed_black_star: 吧