Conventions for NQuads? #2
Comments
|
Very cool. As you say having defined taxonomies is necessary. That brings up some stuff I've worked on before which is related so I'm creating a new issue #4. Regarding the use of quads, just wanted to refer where I picked this idea from. What we're really doing is reification (thanks @ldodds and Ian Davis), i.e. saying something about triples (or annotating triples with provenance) and one of the ways to do that is Named Graph or Quads (which are logically equivalent I think, but might be implemented differently in a triple store with named graph or a quad store). In any case I think Quads are basically a way that we can deal with the "saying something about triples" problem. If we want to be RDF compatible, I don't think there's another way and graphs, as I understand it, are the less ugly and practically workable way to do it (with some reasonable support in a lot of triple stores). Then we need to annotate graphs to include Provenance. And the problem becomes, what the most useable Provenance model for our purpose. Which I think is linked to the discussion in #4. Wonder if James @lisp can tell us what he thinks. Does this moves the ball forward at all? |
|
I think it does move us forward a lot. Given that we do need to record provenance at such a granular (per-statement) level, RDF seems an appropriate way of transferring the data (I'm not sure if it's a great way to store and process it, but that's a secondary discussion). In terms of the actual provenance information required, I think that we could be 80% covered by DC Terms (source, date, author, etc.); but we might need to add the trust facets laid out in #4 (I also find the relevant discussion in the WikiData community interesting). We probably need to model publishers correctly, then we can also do the assignment of trust levels in an application-specific way (i.e. you need to be able to communicate to me that some statement comes from the Government of South Africa, I'll then do my own local ranking of how much I trust them and what that means). Perhaps a taxonomy of sources and processing levels would be useful, though (i.e. "government", "ngo", "journalists/media" for source types, processing levels such as "from official bulk data", "manually collected", "scraped", etc.). There's another taxonomy we might need, too: how to talk about the graph that is represented in our statements. Some of the statements might relate to nodes, some might relate to edges, and others would relate to the link between edges and nodes. I wonder if there is an existing ontology for this? (Edit: this is assuming we want to model a property graph inside RDF, which for some reason I'm inclined to do, even though it may be wrong and rub it the wrong way??) |
|
At first I thought this was algorith-generated text spam - a sign of how little I understand the terminology you're using! - but now I realise I'm just not the Ian Davies you perhaps intended to include in this discussion...? On 19 Aug 2014, at 14:18, Friedrich Lindenberg [email protected] wrote:
|
|
Oops, sorry! Yeah, this discussion is pretty far out there - but we're basically just trying to find out how to let journalists and NGO researchers collect information in a replicable way :) |
|
@pudo Really glad it helps.Let me get back to you soon. Sorry for the noise Ian. Indeed I had added the wrong Ian Davis (with the wrong spelling too). I was trying to CC the Ian Davis that co-wrote this http://patterns.dataincubator.org/book/. |
|
Just commenting to note that it was @iand who co-authored the patterns book with me. Using Named Graphs seems like a good solution for what you want to do. For capturing Provenance have you looked at PROV? It might have some terms you can use or build on: http://www.w3.org/TR/prov-overview/ But using Dublin Core and modelling publishers as resources (see the ORG ontology for describing organizations) would be a good start. |
|
On 2014-08-19, at 15:18, Friedrich Lindenberg [email protected] wrote:
|
|
Thanks for the advice and proper attribution/sourcing/provenance of the pattern book @ldodds! :) Hey @lisp, thanks for dropping by!
You mean that we need to either make sure that our current ways to store statements (triples) include a way to uniquely identify them (so that we can then link them to provenance statements)? A quad store would have that by definition right? And a few triple stores do named graphs which is functionally the same, right? Our was the emphasis on scale and the fact that when we're granular in that way then we have several more orders of statements to deal with? This is more linked to our conversation in #3 and #4 by the way. Hey @pudo. Looks like Provoviz is in Flask! Cool to look at the lower layer (and d3 integration). But miles away from what we would require as user interface for journalists and NGOs! TL;DR I only have (limited) book knowledge about all the below so I don't know how to start small and build iteratively and explain (myself) a lot.
We could use the schema.org approach:
Though I feel a bit uneasy about using subclasses for organisation types like that. It seems that the ORG Ontology approach is more flexible, then we can use something like purpose or classification which as said in the doc can point to a SKOS Vocabulary (basically a taxonomy) of our choosing, or anything really so we could also link back to schema.org if we wanted to, or find a better one.
I might not understand this correctly but here's how I think we can do what you say. In RDF, everything has a URI, subject object and predicates too. That means that each of these (and the statement itself if we use quads in the graph per resource pattern) can be used as the object of a statemet (including these meta statements). I think that the reason you're thinking that way is because you're still considering that your graph (nodes and edges) is stored in your SQL store, and that the rest (meta-graph) is in a triple store. Am I right? If that's the case then maybe what I just say should convince you (and me) to move to a triple store because then all of this quad business starts to make sense and is very flexible (we can be as meta as we want to be because of that quad structure). Re. RDF to transfer/store. AFAIU, RDF is just a representation of the data, a specific way to format triples (and potentially their schema). Stores don't "use" RDF, they just consume or produce it. But I guess you can say that triple stores are generally designed to store RDF (i.e. the problem of storing tons of small statements about stuff and the efficient retrieval and querying of those), and I'm glad you agree that it's the proper way to exchange or publish, because that means we're doing Linked Data then :) Re. Dublin Core. I think you're right, and taking into account @ldodds and @lisp's advice, in fact DC can be directly mapped to PROV. Re. Modeling publishers, @ldodds great! Indeed let's look into ORG (Updated our current preferred approaches) and maybe NACE for industry classifications, and FIBO for equity/control and contracts. Re. Trust. I think this is one which require more thinking and discussion about how to properly model this (and hopefully build/interface nicely with existing efforts). For a start I think we need to get our semantics in sync. In #4, there is "Verification" which I think is an activity (done by journalists and/or citizen and/or scientists...) that is used to establish "Trust". I think then that "Reputation" is something that as you said is subjective and any information consumer could have his own (application) logic to calculate and that can also be used to establish "Trust". I think "Trust" is also something that has some baggage in the Semantic Web world and means a slightly different (or maybe more narrow) thing: Re.Your "publisher" example, I think that Quads + Provenance (or even DC) would cover the "statement comes from" bit. But I think Provenance will be best if we want to be more expressive with regards to the type of "processing" or "publishing" i.e. Activity that took place. Did the government hire a private research company to do the data collection and internally did the statistical analysis? This is a good example of the application of the Prov ontology to Data Journalism which has various example of processing steps. I think that in Semantic Web parlance, following a Schema (or an Ontology) means your data set is "normalised" or "validates" (field is an integer instead of a string) which doesn't mean that it makes sense. "Rules" are meant to add more Application Logic, to also make sure it makes sense (age field is under 18 for "teenager" entities, brothers are male, you can't have multiple biological_ fathers). I think then that the Proof layer is supposed to allow verifying whether something that is said in a valid form, and with application meaning, is actually true (is that person actually my dad or not). And I guess that then "provenance" is part of this, but it's going to be very different for theoretical knowledge (2+2=4), or concrete knowledge (I have 4 children - __I do not really). I guess that what "proof" means in the concrete world is really the journalist's (and the scientists, and the intelligence agencies ...) job. This is a good (even if it's old) high level overview. Looking at the recommended document (PROV-PRIMER), it reminds me of that great rant (JSON-LD and why I hate the semantic web I can see a parallel between specification writers and open source software engineers. Neither think much about human centric... From the @openoil standpoint, provenance is mainly about making sure every statement is sourced so the problem is relatively simple and it's mostly about migrating to a quad-store. From the newsverify standpoint the problem is more complex as described in #4 and means modeling provenance, but also rules about establishing "verification" levels (and probably working towards agreeing with standards - while allowing for subtle differences in how each news outlet actually verify and decide to publish). Questions:
|
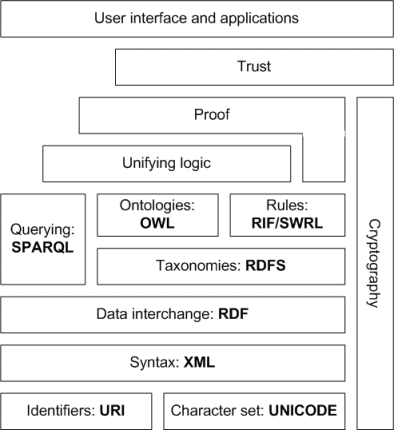
|
On 2014-08-20, at 18:41, Jun Matsushita [email protected] wrote:
if you reify by materializing the relations between each statement and its terms[http://patterns.dataincubator.org/book/reified-statement.html], a triple store would allow that by definition.
a named graph relates an identifier to a set of triples. the access paths implicit in your application will argue for one structure or the other. to take the example of provenance, the question is whether your inferences will follow from assertions in the provenance domain, or from the values of terms inherent in the statements themselves. |
|
@jindrichmynarz pointed me at this, as well: http://www.w3.org/TR/swbp-n-aryRelations/ - useful read, advocates for retaining relationships as bespoke entities, rather than modelling them as a triple in it's own named graph. |
|
I think the "n-ary and reification" paragraph on that link (and copied below), makes the case that n-ary is relevant when what you want to describe (aside from the provenance aspects) so for instance the relationships between organisations or individuals (an example that is relevant to Open Oil is contracts which have shares), in other words the real world stuff you're modelling, have multiple properties. In the para it recommends using reification (which in our case we can exchange for quads or named graphs) when we need to say something the Statement (i.e. for instance about who said that there was a contract with that particular percentage of shares). Also note that this document actually proposes how to model a n-ary relationship using nothing but triples. So it's basically helping to make sure that everyone having n-ary things to model will do it in the same way. In fact it reminds me of how in a n to n relationship in a database you actually need a third intermediary table (in this case the relationship blank node that is helping "contain" the multiple properties that exist on the relationship. Also worth noting that in Neo4j doing this is as simple as adding a property on a relationship. Hope that's not too far off... Jun N-ary relations and reification in RDF It may be natural to think of RDF reification when representing n-ary relations. We do not want to use the RDF reification vocabulary to represent n-ary relations in general for the following reasons. The RDF reification vocabulary is designed to talk about statements—individuals that are instances ofrdf:Statement. A statement is a object, predicate, subject triple and reification in RDF is used to put additional information about this triple. This information may include the source of the information in the triple, for example. In n-ary relations, however, additional arguments in the relation do not usually characterize the statement but rather provide additional information about the relation instance itself. Thus, it is more natural to talk about instances of a diagnosis relation or a purchase rather than about a statement. In the use cases that we discussed in the note, the intent is to talk about instances of a relation, not about statements about such instances. Sent from my phone
|
|
@jmatsushita that's a good summary of the different cases. In the patterns book I tried to draw this out by documenting separate patterns: Qualified Relation (describing properties of a relationship), N-Ary Relation (relationships between >2 resources), and Reified Statement (making statements about statements). |
I've been playing with RDF quads a bit following our conversation, and I wonder whether some derivative of those quads with a limited and defined set of taxonomies would be a doable route for data exchange between sites?
This is a converter for grano datasets to RDF: https://gist.github.com/9d43fa708bedc829f6ef
Here's a database/SPARQL for it: http://dydra.com/pudo/grano
This does seem like an appropriate mechanism for managing provenance, even though it's horribly complex.
The text was updated successfully, but these errors were encountered: