diff --git a/.ci/spellcheck/.pyspelling.wordlist.txt b/.ci/spellcheck/.pyspelling.wordlist.txt
index c4c9cf9fa6a..663802768da 100644
--- a/.ci/spellcheck/.pyspelling.wordlist.txt
+++ b/.ci/spellcheck/.pyspelling.wordlist.txt
@@ -427,6 +427,7 @@ LibriSpeech
librispeech
Lim
LinearCameraEmbedder
+Lippipeline
Liu
LLama
LLaMa
diff --git a/notebooks/wav2lip/README.md b/notebooks/wav2lip/README.md
new file mode 100644
index 00000000000..274a8660fdc
--- /dev/null
+++ b/notebooks/wav2lip/README.md
@@ -0,0 +1,27 @@
+# Wav2Lip: Accurately Lip-syncing Videos and OpenVINO
+
+Lip sync technologies are widely used for digital human use cases, which enhance the user experience in dialog scenarios.
+
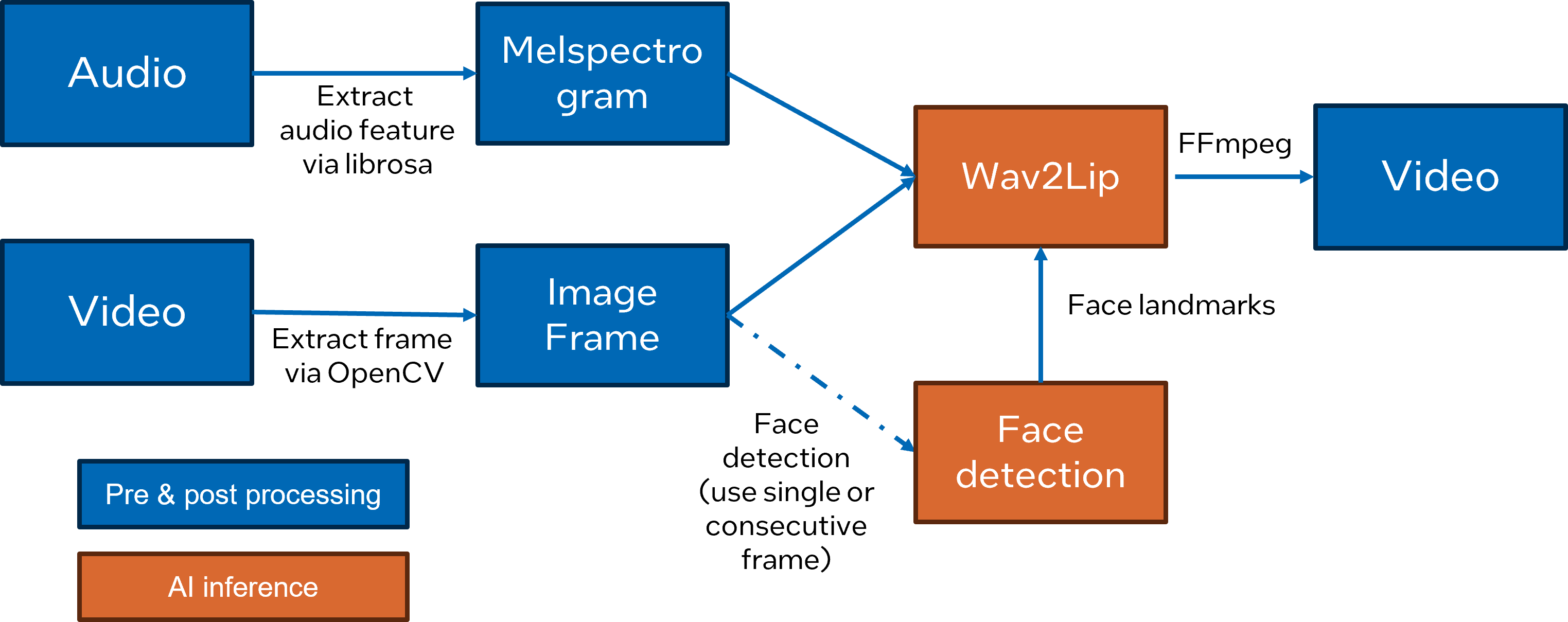
+[Wav2Lip](https://github.com/Rudrabha/Wav2Lip) is a novel approach to generate accurate 2D lip-synced videos in the wild with only one video and an audio clip. Wav2Lip leverages an accurate lip-sync “expert" model and consecutive face frames for accurate, natural lip motion generation.
+
+
+
+In this notebook, we introduce how to enable and optimize Wav2Lippipeline with OpenVINO. This is adaptation of the blog article [Enable 2D Lip Sync Wav2Lip Pipeline with OpenVINO Runtime](https://blog.openvino.ai/blog-posts/enable-2d-lip-sync-wav2lip-pipeline-with-openvino-runtime).
+
+Here is Wav2Lip pipeline overview:
+
+
+
+## Notebook contents
+The tutorial consists from following steps:
+
+- Prerequisites
+- Convert the original model to OpenVINO Intermediate Representation (IR) format
+- Compiling models and prepare pipeline
+- Interactive inference
+
+## Installation instructions
+This is a self-contained example that relies solely on its own code.
+We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
+For details, please refer to [Installation Guide](../../README.md).
+ diff --git a/notebooks/wav2lip/gradio_helper.py b/notebooks/wav2lip/gradio_helper.py
new file mode 100644
index 00000000000..e158fae5bba
--- /dev/null
+++ b/notebooks/wav2lip/gradio_helper.py
@@ -0,0 +1,25 @@
+from typing import Callable
+import gradio as gr
+import numpy as np
+
+
+examples = [
+ [
+ "data_video_sun_5s.mp4",
+ "data_audio_sun_5s.wav",
+ ],
+]
+
+
+def make_demo(fn: Callable):
+ demo = gr.Interface(
+ fn=fn,
+ inputs=[
+ gr.Video(label="Face video"),
+ gr.Audio(label="Audio", type="filepath"),
+ ],
+ outputs="video",
+ examples=examples,
+ allow_flagging="never",
+ )
+ return demo
diff --git a/notebooks/wav2lip/ov_inference.py b/notebooks/wav2lip/ov_inference.py
new file mode 100644
index 00000000000..c089a503d0b
--- /dev/null
+++ b/notebooks/wav2lip/ov_inference.py
@@ -0,0 +1,637 @@
+from glob import glob
+from enum import Enum
+import math
+import subprocess
+
+import cv2
+import numpy as np
+from tqdm import tqdm
+import torch
+import torch.nn.functional as F
+
+from Wav2Lip import audio
+import openvino as ov
+
+
+device = "cpu"
+
+
+def bboxlog(x1, y1, x2, y2, axc, ayc, aww, ahh):
+ xc, yc, ww, hh = (x2 + x1) / 2, (y2 + y1) / 2, x2 - x1, y2 - y1
+ dx, dy = (xc - axc) / aww, (yc - ayc) / ahh
+ dw, dh = math.log(ww / aww), math.log(hh / ahh)
+ return dx, dy, dw, dh
+
+
+def bboxloginv(dx, dy, dw, dh, axc, ayc, aww, ahh):
+ xc, yc = dx * aww + axc, dy * ahh + ayc
+ ww, hh = math.exp(dw) * aww, math.exp(dh) * ahh
+ x1, x2, y1, y2 = xc - ww / 2, xc + ww / 2, yc - hh / 2, yc + hh / 2
+ return x1, y1, x2, y2
+
+
+def nms(dets, thresh):
+ if 0 == len(dets):
+ return []
+ x1, y1, x2, y2, scores = dets[:, 0], dets[:, 1], dets[:, 2], dets[:, 3], dets[:, 4]
+ areas = (x2 - x1 + 1) * (y2 - y1 + 1)
+ order = scores.argsort()[::-1]
+
+ keep = []
+ while order.size > 0:
+ i = order[0]
+ keep.append(i)
+ xx1, yy1 = np.maximum(x1[i], x1[order[1:]]), np.maximum(y1[i], y1[order[1:]])
+ xx2, yy2 = np.minimum(x2[i], x2[order[1:]]), np.minimum(y2[i], y2[order[1:]])
+
+ w, h = np.maximum(0.0, xx2 - xx1 + 1), np.maximum(0.0, yy2 - yy1 + 1)
+ ovr = w * h / (areas[i] + areas[order[1:]] - w * h)
+
+ inds = np.where(ovr <= thresh)[0]
+ order = order[inds + 1]
+
+ return keep
+
+
+def encode(matched, priors, variances):
+ """Encode the variances from the priorbox layers into the ground truth boxes
+ we have matched (based on jaccard overlap) with the prior boxes.
+ Args:
+ matched: (tensor) Coords of ground truth for each prior in point-form
+ Shape: [num_priors, 4].
+ priors: (tensor) Prior boxes in center-offset form
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ encoded boxes (tensor), Shape: [num_priors, 4]
+ """
+
+ # dist b/t match center and prior's center
+ g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - priors[:, :2]
+ # encode variance
+ g_cxcy /= variances[0] * priors[:, 2:]
+ # match wh / prior wh
+ g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
+ g_wh = torch.log(g_wh) / variances[1]
+ # return target for smooth_l1_loss
+ return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
+
+
+def decode(loc, priors, variances):
+ """Decode locations from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ loc (tensor): location predictions for loc layers,
+ Shape: [num_priors,4]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded bounding box predictions
+ """
+
+ boxes = torch.cat((priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:], priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
+ boxes[:, :2] -= boxes[:, 2:] / 2
+ boxes[:, 2:] += boxes[:, :2]
+ return boxes
+
+
+def batch_decode(loc, priors, variances):
+ """Decode locations from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ loc (tensor): location predictions for loc layers,
+ Shape: [num_priors,4]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded bounding box predictions
+ """
+
+ boxes = torch.cat((priors[:, :, :2] + loc[:, :, :2] * variances[0] * priors[:, :, 2:], priors[:, :, 2:] * torch.exp(loc[:, :, 2:] * variances[1])), 2)
+ boxes[:, :, :2] -= boxes[:, :, 2:] / 2
+ boxes[:, :, 2:] += boxes[:, :, :2]
+ return boxes
+
+
+def get_smoothened_boxes(boxes, T):
+ for i in range(len(boxes)):
+ if i + T > len(boxes):
+ window = boxes[len(boxes) - T :]
+ else:
+ window = boxes[i : i + T]
+ boxes[i] = np.mean(window, axis=0)
+ return boxes
+
+
+def detect(net, img, device):
+ img = img - np.array([104, 117, 123])
+ img = img.transpose(2, 0, 1)
+ img = img.reshape((1,) + img.shape)
+
+ img = torch.from_numpy(img).float().to(device)
+ BB, CC, HH, WW = img.size()
+
+ results = net({"x": img})
+ olist = [torch.Tensor(results[i]) for i in range(12)]
+
+ bboxlist = []
+ for i in range(len(olist) // 2):
+ olist[i * 2] = F.softmax(olist[i * 2], dim=1)
+ olist = [oelem.data.cpu() for oelem in olist]
+ for i in range(len(olist) // 2):
+ ocls, oreg = olist[i * 2], olist[i * 2 + 1]
+ FB, FC, FH, FW = ocls.size() # feature map size
+ stride = 2 ** (i + 2) # 4,8,16,32,64,128
+ anchor = stride * 4
+ poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
+ for Iindex, hindex, windex in poss:
+ axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
+ score = ocls[0, 1, hindex, windex]
+ loc = oreg[0, :, hindex, windex].contiguous().view(1, 4)
+ priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]])
+ variances = [0.1, 0.2]
+ box = decode(loc, priors, variances)
+ x1, y1, x2, y2 = box[0] * 1.0
+ # cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
+ bboxlist.append([x1, y1, x2, y2, score])
+ bboxlist = np.array(bboxlist)
+ if 0 == len(bboxlist):
+ bboxlist = np.zeros((1, 5))
+
+ return bboxlist
+
+
+def batch_detect(net, imgs, device):
+ imgs = imgs - np.array([104, 117, 123])
+ imgs = imgs.transpose(0, 3, 1, 2)
+
+ imgs = torch.from_numpy(imgs).float().to(device)
+ BB, CC, HH, WW = imgs.size()
+
+ results = net({"x": imgs.numpy()})
+ olist = [torch.Tensor(results[i]) for i in range(12)]
+
+ bboxlist = []
+ for i in range(len(olist) // 2):
+ olist[i * 2] = F.softmax(olist[i * 2], dim=1)
+ # olist[i * 2] = (olist[i * 2], dim=1)
+ olist = [oelem.data.cpu() for oelem in olist]
+ for i in range(len(olist) // 2):
+ ocls, oreg = olist[i * 2], olist[i * 2 + 1]
+ FB, FC, FH, FW = ocls.size() # feature map size
+ stride = 2 ** (i + 2) # 4,8,16,32,64,128
+ anchor = stride * 4
+ poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
+ for Iindex, hindex, windex in poss:
+ axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
+ score = ocls[:, 1, hindex, windex]
+ loc = oreg[:, :, hindex, windex].contiguous().view(BB, 1, 4)
+ priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]]).view(1, 1, 4)
+ variances = [0.1, 0.2]
+ box = batch_decode(loc, priors, variances)
+ box = box[:, 0] * 1.0
+ # cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
+ bboxlist.append(torch.cat([box, score.unsqueeze(1)], 1).cpu().numpy())
+ bboxlist = np.array(bboxlist)
+ if 0 == len(bboxlist):
+ bboxlist = np.zeros((1, BB, 5))
+
+ return bboxlist
+
+
+def flip_detect(net, img, device):
+ img = cv2.flip(img, 1)
+ b = detect(net, img, device)
+
+ bboxlist = np.zeros(b.shape)
+ bboxlist[:, 0] = img.shape[1] - b[:, 2]
+ bboxlist[:, 1] = b[:, 1]
+ bboxlist[:, 2] = img.shape[1] - b[:, 0]
+ bboxlist[:, 3] = b[:, 3]
+ bboxlist[:, 4] = b[:, 4]
+ return bboxlist
+
+
+def pts_to_bb(pts):
+ min_x, min_y = np.min(pts, axis=0)
+ max_x, max_y = np.max(pts, axis=0)
+ return np.array([min_x, min_y, max_x, max_y])
+
+
+class OVFaceDetector(object):
+ """An abstract class representing a face detector.
+
+ Any other face detection implementation must subclass it. All subclasses
+ must implement ``detect_from_image``, that return a list of detected
+ bounding boxes. Optionally, for speed considerations detect from path is
+ recommended.
+ """
+
+ def __init__(self, device, verbose):
+ self.device = device
+ self.verbose = verbose
+
+ def detect_from_image(self, tensor_or_path):
+ """Detects faces in a given image.
+
+ This function detects the faces present in a provided BGR(usually)
+ image. The input can be either the image itself or the path to it.
+
+ Arguments:
+ tensor_or_path {numpy.ndarray, torch.tensor or string} -- the path
+ to an image or the image itself.
+
+ Example::
+
+ >>> path_to_image = 'data/image_01.jpg'
+ ... detected_faces = detect_from_image(path_to_image)
+ [A list of bounding boxes (x1, y1, x2, y2)]
+ >>> image = cv2.imread(path_to_image)
+ ... detected_faces = detect_from_image(image)
+ [A list of bounding boxes (x1, y1, x2, y2)]
+
+ """
+ raise NotImplementedError
+
+ def detect_from_directory(self, path, extensions=[".jpg", ".png"], recursive=False, show_progress_bar=True):
+ """Detects faces from all the images present in a given directory.
+
+ Arguments:
+ path {string} -- a string containing a path that points to the folder containing the images
+
+ Keyword Arguments:
+ extensions {list} -- list of string containing the extensions to be
+ consider in the following format: ``.extension_name`` (default:
+ {['.jpg', '.png']}) recursive {bool} -- option wherever to scan the
+ folder recursively (default: {False}) show_progress_bar {bool} --
+ display a progressbar (default: {True})
+
+ Example:
+ >>> directory = 'data'
+ ... detected_faces = detect_from_directory(directory)
+ {A dictionary of [lists containing bounding boxes(x1, y1, x2, y2)]}
+
+ """
+ if self.verbose:
+ logger = logging.getLogger(__name__)
+
+ if len(extensions) == 0:
+ if self.verbose:
+ logger.error("Expected at list one extension, but none was received.")
+ raise ValueError
+
+ if self.verbose:
+ logger.info("Constructing the list of images.")
+ additional_pattern = "/**/*" if recursive else "/*"
+ files = []
+ for extension in extensions:
+ files.extend(glob.glob(path + additional_pattern + extension, recursive=recursive))
+
+ if self.verbose:
+ logger.info("Finished searching for images. %s images found", len(files))
+ logger.info("Preparing to run the detection.")
+
+ predictions = {}
+ for image_path in tqdm(files, disable=not show_progress_bar):
+ if self.verbose:
+ logger.info("Running the face detector on image: %s", image_path)
+ predictions[image_path] = self.detect_from_image(image_path)
+
+ if self.verbose:
+ logger.info("The detector was successfully run on all %s images", len(files))
+
+ return predictions
+
+ @property
+ def reference_scale(self):
+ raise NotImplementedError
+
+ @property
+ def reference_x_shift(self):
+ raise NotImplementedError
+
+ @property
+ def reference_y_shift(self):
+ raise NotImplementedError
+
+ @staticmethod
+ def tensor_or_path_to_ndarray(tensor_or_path, rgb=True):
+ """Convert path (represented as a string) or torch.tensor to a numpy.ndarray
+
+ Arguments:
+ tensor_or_path {numpy.ndarray, torch.tensor or string} -- path to the image, or the image itself
+ """
+ if isinstance(tensor_or_path, str):
+ return cv2.imread(tensor_or_path) if not rgb else cv2.imread(tensor_or_path)[..., ::-1]
+ elif torch.is_tensor(tensor_or_path):
+ # Call cpu in case its coming from cuda
+ return tensor_or_path.cpu().numpy()[..., ::-1].copy() if not rgb else tensor_or_path.cpu().numpy()
+ elif isinstance(tensor_or_path, np.ndarray):
+ return tensor_or_path[..., ::-1].copy() if not rgb else tensor_or_path
+ else:
+ raise TypeError
+
+
+class OVSFDDetector(OVFaceDetector):
+ def __init__(self, device, path_to_detector="models/face_detection.xml", verbose=False):
+ super(OVSFDDetector, self).__init__(device, verbose)
+
+ core = ov.Core()
+ self.face_detector = core.compile_model(path_to_detector, self.device)
+
+ def detect_from_image(self, tensor_or_path):
+ image = self.tensor_or_path_to_ndarray(tensor_or_path)
+
+ bboxlist = detect(self.face_detector, image, device="cpu")
+ keep = nms(bboxlist, 0.3)
+ bboxlist = bboxlist[keep, :]
+ bboxlist = [x for x in bboxlist if x[-1] > 0.5]
+
+ return bboxlist
+
+ def detect_from_batch(self, images):
+ bboxlists = batch_detect(self.face_detector, images, device="cpu")
+ keeps = [nms(bboxlists[:, i, :], 0.3) for i in range(bboxlists.shape[1])]
+ bboxlists = [bboxlists[keep, i, :] for i, keep in enumerate(keeps)]
+ bboxlists = [[x for x in bboxlist if x[-1] > 0.5] for bboxlist in bboxlists]
+
+ return bboxlists
+
+ @property
+ def reference_scale(self):
+ return 195
+
+ @property
+ def reference_x_shift(self):
+ return 0
+
+ @property
+ def reference_y_shift(self):
+ return 0
+
+
+class LandmarksType(Enum):
+ """Enum class defining the type of landmarks to detect.
+
+ ``_2D`` - the detected points ``(x,y)`` are detected in a 2D space and follow the visible contour of the face
+ ``_2halfD`` - this points represent the projection of the 3D points into 3D
+ ``_3D`` - detect the points ``(x,y,z)``` in a 3D space
+
+ """
+
+ _2D = 1
+ _2halfD = 2
+ _3D = 3
+
+
+class NetworkSize(Enum):
+ # TINY = 1
+ # SMALL = 2
+ # MEDIUM = 3
+ LARGE = 4
+
+ def __new__(cls, value):
+ member = object.__new__(cls)
+ member._value_ = value
+ return member
+
+ def __int__(self):
+ return self.value
+
+
+class OVFaceAlignment:
+ def __init__(
+ self, landmarks_type, network_size=NetworkSize.LARGE, device="CPU", flip_input=False, verbose=False, path_to_detector="models/face_detection.xml"
+ ):
+ self.device = device
+ self.flip_input = flip_input
+ self.landmarks_type = landmarks_type
+ self.verbose = verbose
+
+ network_size = int(network_size)
+
+ self.face_detector = OVSFDDetector(device=device, path_to_detector=path_to_detector, verbose=verbose)
+
+ def get_detections_for_batch(self, images):
+ images = images[..., ::-1]
+ detected_faces = self.face_detector.detect_from_batch(images.copy())
+ results = []
+
+ for i, d in enumerate(detected_faces):
+ if len(d) == 0:
+ results.append(None)
+ continue
+ d = d[0]
+ d = np.clip(d, 0, None)
+
+ x1, y1, x2, y2 = map(int, d[:-1])
+ results.append((x1, y1, x2, y2))
+
+ return results
+
+
+def face_detect_ov(images, device, face_det_batch_size, pads, nosmooth, path_to_detector):
+ detector = OVFaceAlignment(LandmarksType._2D, flip_input=False, device=device, path_to_detector=path_to_detector)
+
+ batch_size = face_det_batch_size
+
+ print("face_detect_ov images[0].shape: ", images[0].shape)
+ while 1:
+ predictions = []
+ try:
+ for i in tqdm(range(0, len(images), batch_size)):
+ predictions.extend(detector.get_detections_for_batch(np.array(images[i : i + batch_size])))
+ except RuntimeError:
+ if batch_size == 1:
+ raise RuntimeError("Image too big to run face detection on GPU. Please use the --resize_factor argument")
+ batch_size //= 2
+ print("Recovering from OOM error; New batch size: {}".format(batch_size))
+ continue
+ break
+
+ results = []
+ pady1, pady2, padx1, padx2 = pads
+ for rect, image in zip(predictions, images):
+ if rect is None:
+ # check this frame where the face was not detected.
+ cv2.imwrite("temp/faulty_frame.jpg", image)
+ raise ValueError("Face not detected! Ensure the video contains a face in all the frames.")
+
+ y1 = max(0, rect[1] - pady1)
+ y2 = min(image.shape[0], rect[3] + pady2)
+ x1 = max(0, rect[0] - padx1)
+ x2 = min(image.shape[1], rect[2] + padx2)
+
+ results.append([x1, y1, x2, y2])
+
+ boxes = np.array(results)
+ if not nosmooth:
+ boxes = get_smoothened_boxes(boxes, T=5)
+ results = [[image[y1:y2, x1:x2], (y1, y2, x1, x2)] for image, (x1, y1, x2, y2) in zip(images, boxes)]
+
+ del detector
+ return results
+
+
+def datagen(frames, mels, box, static, face_det_batch_size, pads, nosmooth, img_size, wav2lip_batch_size, path_to_detector):
+ img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
+
+ if box[0] == -1:
+ if not static:
+ # BGR2RGB for CNN face detection
+ face_det_results = face_detect_ov(frames, "CPU", face_det_batch_size, pads, nosmooth, path_to_detector)
+ else:
+ face_det_results = face_detect_ov([frames[0]], "CPU", face_det_batch_size, pads, nosmooth, path_to_detector)
+ else:
+ print("Using the specified bounding box instead of face detection...")
+ y1, y2, x1, x2 = box
+ face_det_results = [[f[y1:y2, x1:x2], (y1, y2, x1, x2)] for f in frames]
+
+ for i, m in enumerate(mels):
+ idx = 0 if static else i % len(frames)
+ frame_to_save = frames[idx].copy()
+ face, coords = face_det_results[idx].copy()
+
+ face = cv2.resize(face, (img_size, img_size))
+
+ img_batch.append(face)
+ mel_batch.append(m)
+ frame_batch.append(frame_to_save)
+ coords_batch.append(coords)
+
+ if len(img_batch) >= wav2lip_batch_size:
+ img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
+
+ img_masked = img_batch.copy()
+ img_masked[:, img_size // 2 :] = 0
+
+ img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.0
+ mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
+
+ yield img_batch, mel_batch, frame_batch, coords_batch
+ img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
+
+ if len(img_batch) > 0:
+ img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
+
+ img_masked = img_batch.copy()
+ img_masked[:, img_size // 2 :] = 0
+
+ img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.0
+ mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
+
+ yield img_batch, mel_batch, frame_batch, coords_batch
+
+
+def ov_inference(
+ face_path,
+ audio_path,
+ face_detection_path="models/face_detection.xml",
+ wav2lip_path="models/wav2lip.xml",
+ inference_device="CPU",
+ wav2lip_batch_size=128,
+ outfile="results/result_voice.mp4",
+ resize_factor=1,
+ rotate=False,
+ crop=[0, -1, 0, -1],
+ mel_step_size=16,
+ box=[-1, -1, -1, -1],
+ static=False,
+ img_size=96,
+ face_det_batch_size=16,
+ pads=[0, 10, 0, 0],
+ nosmooth=False,
+):
+ print("Reading video frames...")
+
+ video_stream = cv2.VideoCapture(face_path)
+ fps = video_stream.get(cv2.CAP_PROP_FPS)
+
+ full_frames = []
+ while 1:
+ still_reading, frame = video_stream.read()
+ if not still_reading:
+ video_stream.release()
+ break
+ if resize_factor > 1:
+ frame = cv2.resize(frame, (frame.shape[1] // resize_factor, frame.shape[0] // resize_factor))
+
+ if rotate:
+ frame = cv2.rotate(frame, cv2.cv2.ROTATE_90_CLOCKWISE)
+
+ y1, y2, x1, x2 = crop
+ if x2 == -1:
+ x2 = frame.shape[1]
+ if y2 == -1:
+ y2 = frame.shape[0]
+
+ frame = frame[y1:y2, x1:x2]
+
+ full_frames.append(frame)
+
+ print("Number of frames available for inference: " + str(len(full_frames)))
+
+ core = ov.Core()
+
+ if not audio_path.endswith(".wav"):
+ print("Extracting raw audio...")
+ command = "ffmpeg -y -i {} -strict -2 {}".format(audio_path, "temp/temp.wav")
+
+ subprocess.call(command, shell=True)
+ audio_path = "temp/temp.wav"
+
+ wav = audio.load_wav(audio_path, 16000)
+ mel = audio.melspectrogram(wav)
+ print(mel.shape)
+
+ if np.isnan(mel.reshape(-1)).sum() > 0:
+ raise ValueError("Mel contains nan! Using a TTS voice? Add a small epsilon noise to the wav file and try again")
+
+ mel_chunks = []
+ mel_idx_multiplier = 80.0 / fps
+ i = 0
+ while 1:
+ start_idx = int(i * mel_idx_multiplier)
+ if start_idx + mel_step_size > len(mel[0]):
+ mel_chunks.append(mel[:, len(mel[0]) - mel_step_size :])
+ break
+ mel_chunks.append(mel[:, start_idx : start_idx + mel_step_size])
+ i += 1
+
+ print("Length of mel chunks: {}".format(len(mel_chunks)))
+
+ full_frames = full_frames[: len(mel_chunks)]
+ batch_size = wav2lip_batch_size
+ gen = datagen(full_frames.copy(), mel_chunks, box, static, face_det_batch_size, pads, nosmooth, img_size, wav2lip_batch_size, face_detection_path)
+ for i, (img_batch, mel_batch, frames, coords) in enumerate(tqdm(gen, total=int(np.ceil(float(len(mel_chunks)) / batch_size)))):
+ if i == 0:
+ img_batch = torch.FloatTensor(np.transpose(img_batch, (0, 3, 1, 2))).to(device)
+ mel_batch = torch.FloatTensor(np.transpose(mel_batch, (0, 3, 1, 2))).to(device)
+ compiled_wav2lip_model = core.compile_model(wav2lip_path, inference_device)
+ print("Model loaded")
+
+ frame_h, frame_w = full_frames[0].shape[:-1]
+ out = cv2.VideoWriter("Wav2Lip/temp/result.avi", cv2.VideoWriter_fourcc(*"DIVX"), fps, (frame_w, frame_h))
+ pred_ov = compiled_wav2lip_model({"audio_sequences": mel_batch.numpy(), "face_sequences": img_batch.numpy()})[0]
+ else:
+ img_batch = np.transpose(img_batch, (0, 3, 1, 2))
+ mel_batch = np.transpose(mel_batch, (0, 3, 1, 2))
+ pred_ov = compiled_wav2lip_model({"audio_sequences": mel_batch, "face_sequences": img_batch})[0]
+
+ pred_ov = compiled_wav2lip_model({"audio_sequences": mel_batch, "face_sequences": img_batch})[0]
+ pred_ov = pred_ov.transpose(0, 2, 3, 1) * 255.0
+ for p, f, c in zip(pred_ov, frames, coords):
+ y1, y2, x1, x2 = c
+ p = cv2.resize(p.astype(np.uint8), (x2 - x1, y2 - y1))
+
+ f[y1:y2, x1:x2] = p
+ out.write(f)
+
+ out.release()
+
+ command = "ffmpeg -y -i {} -i {} -strict -2 -q:v 1 {}".format(audio_path, "Wav2Lip/temp/result.avi", outfile)
+ subprocess.call(command, shell=True)
+
+ return outfile
diff --git a/notebooks/wav2lip/ov_wav2lip_helper.py b/notebooks/wav2lip/ov_wav2lip_helper.py
new file mode 100644
index 00000000000..18811f409cf
--- /dev/null
+++ b/notebooks/wav2lip/ov_wav2lip_helper.py
@@ -0,0 +1,64 @@
+import numpy as np
+import os
+from pathlib import Path
+
+from huggingface_hub import hf_hub_download
+import torch
+
+import openvino as ov
+
+from notebook_utils import download_file
+from Wav2Lip.face_detection.detection.sfd.net_s3fd import s3fd
+from Wav2Lip.models import Wav2Lip
+
+
+def _load(checkpoint_path):
+ checkpoint = torch.load(checkpoint_path, map_location=lambda storage, loc: storage)
+ return checkpoint
+
+
+def load_model(path):
+ model = Wav2Lip()
+ print("Load checkpoint from: {}".format(path))
+ checkpoint = _load(path)
+ s = checkpoint["state_dict"]
+ new_s = {}
+ for k, v in s.items():
+ new_s[k.replace("module.", "")] = v
+ model.load_state_dict(new_s)
+
+ return model.eval()
+
+
+def download_and_convert_models(ov_face_detection_model_path, ov_wav2lip_model_path):
+ models_urls = {"s3fd": "https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth"}
+ path_to_detector = "checkpoints/face_detection.pth"
+ # Convert Face Detection Model
+ print("Convert Face Detection Model ...")
+ if not os.path.isfile(path_to_detector):
+ download_file(models_urls["s3fd"])
+ if not os.path.exists("checkpoints"):
+ os.mkdir("checkpoints")
+ os.replace("s3fd-619a316812.pth", path_to_detector)
+ model_weights = torch.load(path_to_detector)
+
+ face_detector = s3fd()
+ face_detector.load_state_dict(model_weights)
+
+ if not ov_face_detection_model_path.exists():
+ face_detection_dummy_inputs = torch.FloatTensor(np.random.rand(1, 3, 768, 576))
+ face_detection_ov_model = ov.convert_model(face_detector, example_input=face_detection_dummy_inputs)
+ ov.save_model(face_detection_ov_model, ov_face_detection_model_path)
+ print("Converted face detection OpenVINO model: ", ov_face_detection_model_path)
+
+ print("Convert Wav2Lip Model ...")
+ path_to_wav2lip = hf_hub_download(repo_id="numz/wav2lip_studio", filename="Wav2lip/wav2lip.pth", local_dir="checkpoints")
+ wav2lip = load_model(path_to_wav2lip)
+ img_batch = torch.FloatTensor(np.random.rand(123, 6, 96, 96))
+ mel_batch = torch.FloatTensor(np.random.rand(123, 1, 80, 16))
+
+ if not ov_wav2lip_model_path.exists():
+ example_inputs = {"audio_sequences": mel_batch, "face_sequences": img_batch}
+ wav2lip_ov_model = ov.convert_model(wav2lip, example_input=example_inputs)
+ ov.save_model(wav2lip_ov_model, ov_wav2lip_model_path)
+ print("Converted face detection OpenVINO model: ", ov_wav2lip_model_path)
diff --git a/notebooks/wav2lip/wav2lip.ipynb b/notebooks/wav2lip/wav2lip.ipynb
new file mode 100644
index 00000000000..8be1de1f6a3
--- /dev/null
+++ b/notebooks/wav2lip/wav2lip.ipynb
@@ -0,0 +1,411 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "36104004-1d8e-4890-ab87-990ade94dcc5",
+ "metadata": {},
+ "source": [
+ "# Wav2Lip: Accurately Lip-syncing Videos and OpenVINO\n",
+ "\n",
+ "Lip sync technologies are widely used for digital human use cases, which enhance the user experience in dialog scenarios.\n",
+ "\n",
+ "[Wav2Lip](https://github.com/Rudrabha/Wav2Lip) is an approach to generate accurate 2D lip-synced videos in the wild with only one video and an audio clip. Wav2Lip leverages an accurate lip-sync “expert\" model and consecutive face frames for accurate, natural lip motion generation.\n",
+ "\n",
+ "\n",
+ "\n",
+ "In this notebook, we introduce how to enable and optimize Wav2Lippipeline with OpenVINO. This is adaptation of the blog article [Enable 2D Lip Sync Wav2Lip Pipeline with OpenVINO Runtime](https://blog.openvino.ai/blog-posts/enable-2d-lip-sync-wav2lip-pipeline-with-openvino-runtime).\n",
+ "\n",
+ "Here is Wav2Lip pipeline overview:\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Table of contents:\n",
+ "\n",
+ "- [Prerequisites](#Prerequisites)\n",
+ "- [Convert the model to OpenVINO IR](#Convert-the-model-to-OpenVINO-IR)\n",
+ "- [Compiling models and prepare pipeline](#Compiling-models-and-prepare-pipeline)\n",
+ "- [Interactive inference](#Interactive-inference)\n",
+ "\n",
+ "### Installation Instructions\n",
+ "\n",
+ "This is a self-contained example that relies solely on its own code.\n",
+ "\n",
+ "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
+ "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
+ "\n",
+ "
diff --git a/notebooks/wav2lip/gradio_helper.py b/notebooks/wav2lip/gradio_helper.py
new file mode 100644
index 00000000000..e158fae5bba
--- /dev/null
+++ b/notebooks/wav2lip/gradio_helper.py
@@ -0,0 +1,25 @@
+from typing import Callable
+import gradio as gr
+import numpy as np
+
+
+examples = [
+ [
+ "data_video_sun_5s.mp4",
+ "data_audio_sun_5s.wav",
+ ],
+]
+
+
+def make_demo(fn: Callable):
+ demo = gr.Interface(
+ fn=fn,
+ inputs=[
+ gr.Video(label="Face video"),
+ gr.Audio(label="Audio", type="filepath"),
+ ],
+ outputs="video",
+ examples=examples,
+ allow_flagging="never",
+ )
+ return demo
diff --git a/notebooks/wav2lip/ov_inference.py b/notebooks/wav2lip/ov_inference.py
new file mode 100644
index 00000000000..c089a503d0b
--- /dev/null
+++ b/notebooks/wav2lip/ov_inference.py
@@ -0,0 +1,637 @@
+from glob import glob
+from enum import Enum
+import math
+import subprocess
+
+import cv2
+import numpy as np
+from tqdm import tqdm
+import torch
+import torch.nn.functional as F
+
+from Wav2Lip import audio
+import openvino as ov
+
+
+device = "cpu"
+
+
+def bboxlog(x1, y1, x2, y2, axc, ayc, aww, ahh):
+ xc, yc, ww, hh = (x2 + x1) / 2, (y2 + y1) / 2, x2 - x1, y2 - y1
+ dx, dy = (xc - axc) / aww, (yc - ayc) / ahh
+ dw, dh = math.log(ww / aww), math.log(hh / ahh)
+ return dx, dy, dw, dh
+
+
+def bboxloginv(dx, dy, dw, dh, axc, ayc, aww, ahh):
+ xc, yc = dx * aww + axc, dy * ahh + ayc
+ ww, hh = math.exp(dw) * aww, math.exp(dh) * ahh
+ x1, x2, y1, y2 = xc - ww / 2, xc + ww / 2, yc - hh / 2, yc + hh / 2
+ return x1, y1, x2, y2
+
+
+def nms(dets, thresh):
+ if 0 == len(dets):
+ return []
+ x1, y1, x2, y2, scores = dets[:, 0], dets[:, 1], dets[:, 2], dets[:, 3], dets[:, 4]
+ areas = (x2 - x1 + 1) * (y2 - y1 + 1)
+ order = scores.argsort()[::-1]
+
+ keep = []
+ while order.size > 0:
+ i = order[0]
+ keep.append(i)
+ xx1, yy1 = np.maximum(x1[i], x1[order[1:]]), np.maximum(y1[i], y1[order[1:]])
+ xx2, yy2 = np.minimum(x2[i], x2[order[1:]]), np.minimum(y2[i], y2[order[1:]])
+
+ w, h = np.maximum(0.0, xx2 - xx1 + 1), np.maximum(0.0, yy2 - yy1 + 1)
+ ovr = w * h / (areas[i] + areas[order[1:]] - w * h)
+
+ inds = np.where(ovr <= thresh)[0]
+ order = order[inds + 1]
+
+ return keep
+
+
+def encode(matched, priors, variances):
+ """Encode the variances from the priorbox layers into the ground truth boxes
+ we have matched (based on jaccard overlap) with the prior boxes.
+ Args:
+ matched: (tensor) Coords of ground truth for each prior in point-form
+ Shape: [num_priors, 4].
+ priors: (tensor) Prior boxes in center-offset form
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ encoded boxes (tensor), Shape: [num_priors, 4]
+ """
+
+ # dist b/t match center and prior's center
+ g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - priors[:, :2]
+ # encode variance
+ g_cxcy /= variances[0] * priors[:, 2:]
+ # match wh / prior wh
+ g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
+ g_wh = torch.log(g_wh) / variances[1]
+ # return target for smooth_l1_loss
+ return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
+
+
+def decode(loc, priors, variances):
+ """Decode locations from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ loc (tensor): location predictions for loc layers,
+ Shape: [num_priors,4]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded bounding box predictions
+ """
+
+ boxes = torch.cat((priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:], priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
+ boxes[:, :2] -= boxes[:, 2:] / 2
+ boxes[:, 2:] += boxes[:, :2]
+ return boxes
+
+
+def batch_decode(loc, priors, variances):
+ """Decode locations from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ loc (tensor): location predictions for loc layers,
+ Shape: [num_priors,4]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded bounding box predictions
+ """
+
+ boxes = torch.cat((priors[:, :, :2] + loc[:, :, :2] * variances[0] * priors[:, :, 2:], priors[:, :, 2:] * torch.exp(loc[:, :, 2:] * variances[1])), 2)
+ boxes[:, :, :2] -= boxes[:, :, 2:] / 2
+ boxes[:, :, 2:] += boxes[:, :, :2]
+ return boxes
+
+
+def get_smoothened_boxes(boxes, T):
+ for i in range(len(boxes)):
+ if i + T > len(boxes):
+ window = boxes[len(boxes) - T :]
+ else:
+ window = boxes[i : i + T]
+ boxes[i] = np.mean(window, axis=0)
+ return boxes
+
+
+def detect(net, img, device):
+ img = img - np.array([104, 117, 123])
+ img = img.transpose(2, 0, 1)
+ img = img.reshape((1,) + img.shape)
+
+ img = torch.from_numpy(img).float().to(device)
+ BB, CC, HH, WW = img.size()
+
+ results = net({"x": img})
+ olist = [torch.Tensor(results[i]) for i in range(12)]
+
+ bboxlist = []
+ for i in range(len(olist) // 2):
+ olist[i * 2] = F.softmax(olist[i * 2], dim=1)
+ olist = [oelem.data.cpu() for oelem in olist]
+ for i in range(len(olist) // 2):
+ ocls, oreg = olist[i * 2], olist[i * 2 + 1]
+ FB, FC, FH, FW = ocls.size() # feature map size
+ stride = 2 ** (i + 2) # 4,8,16,32,64,128
+ anchor = stride * 4
+ poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
+ for Iindex, hindex, windex in poss:
+ axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
+ score = ocls[0, 1, hindex, windex]
+ loc = oreg[0, :, hindex, windex].contiguous().view(1, 4)
+ priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]])
+ variances = [0.1, 0.2]
+ box = decode(loc, priors, variances)
+ x1, y1, x2, y2 = box[0] * 1.0
+ # cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
+ bboxlist.append([x1, y1, x2, y2, score])
+ bboxlist = np.array(bboxlist)
+ if 0 == len(bboxlist):
+ bboxlist = np.zeros((1, 5))
+
+ return bboxlist
+
+
+def batch_detect(net, imgs, device):
+ imgs = imgs - np.array([104, 117, 123])
+ imgs = imgs.transpose(0, 3, 1, 2)
+
+ imgs = torch.from_numpy(imgs).float().to(device)
+ BB, CC, HH, WW = imgs.size()
+
+ results = net({"x": imgs.numpy()})
+ olist = [torch.Tensor(results[i]) for i in range(12)]
+
+ bboxlist = []
+ for i in range(len(olist) // 2):
+ olist[i * 2] = F.softmax(olist[i * 2], dim=1)
+ # olist[i * 2] = (olist[i * 2], dim=1)
+ olist = [oelem.data.cpu() for oelem in olist]
+ for i in range(len(olist) // 2):
+ ocls, oreg = olist[i * 2], olist[i * 2 + 1]
+ FB, FC, FH, FW = ocls.size() # feature map size
+ stride = 2 ** (i + 2) # 4,8,16,32,64,128
+ anchor = stride * 4
+ poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
+ for Iindex, hindex, windex in poss:
+ axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
+ score = ocls[:, 1, hindex, windex]
+ loc = oreg[:, :, hindex, windex].contiguous().view(BB, 1, 4)
+ priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]]).view(1, 1, 4)
+ variances = [0.1, 0.2]
+ box = batch_decode(loc, priors, variances)
+ box = box[:, 0] * 1.0
+ # cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
+ bboxlist.append(torch.cat([box, score.unsqueeze(1)], 1).cpu().numpy())
+ bboxlist = np.array(bboxlist)
+ if 0 == len(bboxlist):
+ bboxlist = np.zeros((1, BB, 5))
+
+ return bboxlist
+
+
+def flip_detect(net, img, device):
+ img = cv2.flip(img, 1)
+ b = detect(net, img, device)
+
+ bboxlist = np.zeros(b.shape)
+ bboxlist[:, 0] = img.shape[1] - b[:, 2]
+ bboxlist[:, 1] = b[:, 1]
+ bboxlist[:, 2] = img.shape[1] - b[:, 0]
+ bboxlist[:, 3] = b[:, 3]
+ bboxlist[:, 4] = b[:, 4]
+ return bboxlist
+
+
+def pts_to_bb(pts):
+ min_x, min_y = np.min(pts, axis=0)
+ max_x, max_y = np.max(pts, axis=0)
+ return np.array([min_x, min_y, max_x, max_y])
+
+
+class OVFaceDetector(object):
+ """An abstract class representing a face detector.
+
+ Any other face detection implementation must subclass it. All subclasses
+ must implement ``detect_from_image``, that return a list of detected
+ bounding boxes. Optionally, for speed considerations detect from path is
+ recommended.
+ """
+
+ def __init__(self, device, verbose):
+ self.device = device
+ self.verbose = verbose
+
+ def detect_from_image(self, tensor_or_path):
+ """Detects faces in a given image.
+
+ This function detects the faces present in a provided BGR(usually)
+ image. The input can be either the image itself or the path to it.
+
+ Arguments:
+ tensor_or_path {numpy.ndarray, torch.tensor or string} -- the path
+ to an image or the image itself.
+
+ Example::
+
+ >>> path_to_image = 'data/image_01.jpg'
+ ... detected_faces = detect_from_image(path_to_image)
+ [A list of bounding boxes (x1, y1, x2, y2)]
+ >>> image = cv2.imread(path_to_image)
+ ... detected_faces = detect_from_image(image)
+ [A list of bounding boxes (x1, y1, x2, y2)]
+
+ """
+ raise NotImplementedError
+
+ def detect_from_directory(self, path, extensions=[".jpg", ".png"], recursive=False, show_progress_bar=True):
+ """Detects faces from all the images present in a given directory.
+
+ Arguments:
+ path {string} -- a string containing a path that points to the folder containing the images
+
+ Keyword Arguments:
+ extensions {list} -- list of string containing the extensions to be
+ consider in the following format: ``.extension_name`` (default:
+ {['.jpg', '.png']}) recursive {bool} -- option wherever to scan the
+ folder recursively (default: {False}) show_progress_bar {bool} --
+ display a progressbar (default: {True})
+
+ Example:
+ >>> directory = 'data'
+ ... detected_faces = detect_from_directory(directory)
+ {A dictionary of [lists containing bounding boxes(x1, y1, x2, y2)]}
+
+ """
+ if self.verbose:
+ logger = logging.getLogger(__name__)
+
+ if len(extensions) == 0:
+ if self.verbose:
+ logger.error("Expected at list one extension, but none was received.")
+ raise ValueError
+
+ if self.verbose:
+ logger.info("Constructing the list of images.")
+ additional_pattern = "/**/*" if recursive else "/*"
+ files = []
+ for extension in extensions:
+ files.extend(glob.glob(path + additional_pattern + extension, recursive=recursive))
+
+ if self.verbose:
+ logger.info("Finished searching for images. %s images found", len(files))
+ logger.info("Preparing to run the detection.")
+
+ predictions = {}
+ for image_path in tqdm(files, disable=not show_progress_bar):
+ if self.verbose:
+ logger.info("Running the face detector on image: %s", image_path)
+ predictions[image_path] = self.detect_from_image(image_path)
+
+ if self.verbose:
+ logger.info("The detector was successfully run on all %s images", len(files))
+
+ return predictions
+
+ @property
+ def reference_scale(self):
+ raise NotImplementedError
+
+ @property
+ def reference_x_shift(self):
+ raise NotImplementedError
+
+ @property
+ def reference_y_shift(self):
+ raise NotImplementedError
+
+ @staticmethod
+ def tensor_or_path_to_ndarray(tensor_or_path, rgb=True):
+ """Convert path (represented as a string) or torch.tensor to a numpy.ndarray
+
+ Arguments:
+ tensor_or_path {numpy.ndarray, torch.tensor or string} -- path to the image, or the image itself
+ """
+ if isinstance(tensor_or_path, str):
+ return cv2.imread(tensor_or_path) if not rgb else cv2.imread(tensor_or_path)[..., ::-1]
+ elif torch.is_tensor(tensor_or_path):
+ # Call cpu in case its coming from cuda
+ return tensor_or_path.cpu().numpy()[..., ::-1].copy() if not rgb else tensor_or_path.cpu().numpy()
+ elif isinstance(tensor_or_path, np.ndarray):
+ return tensor_or_path[..., ::-1].copy() if not rgb else tensor_or_path
+ else:
+ raise TypeError
+
+
+class OVSFDDetector(OVFaceDetector):
+ def __init__(self, device, path_to_detector="models/face_detection.xml", verbose=False):
+ super(OVSFDDetector, self).__init__(device, verbose)
+
+ core = ov.Core()
+ self.face_detector = core.compile_model(path_to_detector, self.device)
+
+ def detect_from_image(self, tensor_or_path):
+ image = self.tensor_or_path_to_ndarray(tensor_or_path)
+
+ bboxlist = detect(self.face_detector, image, device="cpu")
+ keep = nms(bboxlist, 0.3)
+ bboxlist = bboxlist[keep, :]
+ bboxlist = [x for x in bboxlist if x[-1] > 0.5]
+
+ return bboxlist
+
+ def detect_from_batch(self, images):
+ bboxlists = batch_detect(self.face_detector, images, device="cpu")
+ keeps = [nms(bboxlists[:, i, :], 0.3) for i in range(bboxlists.shape[1])]
+ bboxlists = [bboxlists[keep, i, :] for i, keep in enumerate(keeps)]
+ bboxlists = [[x for x in bboxlist if x[-1] > 0.5] for bboxlist in bboxlists]
+
+ return bboxlists
+
+ @property
+ def reference_scale(self):
+ return 195
+
+ @property
+ def reference_x_shift(self):
+ return 0
+
+ @property
+ def reference_y_shift(self):
+ return 0
+
+
+class LandmarksType(Enum):
+ """Enum class defining the type of landmarks to detect.
+
+ ``_2D`` - the detected points ``(x,y)`` are detected in a 2D space and follow the visible contour of the face
+ ``_2halfD`` - this points represent the projection of the 3D points into 3D
+ ``_3D`` - detect the points ``(x,y,z)``` in a 3D space
+
+ """
+
+ _2D = 1
+ _2halfD = 2
+ _3D = 3
+
+
+class NetworkSize(Enum):
+ # TINY = 1
+ # SMALL = 2
+ # MEDIUM = 3
+ LARGE = 4
+
+ def __new__(cls, value):
+ member = object.__new__(cls)
+ member._value_ = value
+ return member
+
+ def __int__(self):
+ return self.value
+
+
+class OVFaceAlignment:
+ def __init__(
+ self, landmarks_type, network_size=NetworkSize.LARGE, device="CPU", flip_input=False, verbose=False, path_to_detector="models/face_detection.xml"
+ ):
+ self.device = device
+ self.flip_input = flip_input
+ self.landmarks_type = landmarks_type
+ self.verbose = verbose
+
+ network_size = int(network_size)
+
+ self.face_detector = OVSFDDetector(device=device, path_to_detector=path_to_detector, verbose=verbose)
+
+ def get_detections_for_batch(self, images):
+ images = images[..., ::-1]
+ detected_faces = self.face_detector.detect_from_batch(images.copy())
+ results = []
+
+ for i, d in enumerate(detected_faces):
+ if len(d) == 0:
+ results.append(None)
+ continue
+ d = d[0]
+ d = np.clip(d, 0, None)
+
+ x1, y1, x2, y2 = map(int, d[:-1])
+ results.append((x1, y1, x2, y2))
+
+ return results
+
+
+def face_detect_ov(images, device, face_det_batch_size, pads, nosmooth, path_to_detector):
+ detector = OVFaceAlignment(LandmarksType._2D, flip_input=False, device=device, path_to_detector=path_to_detector)
+
+ batch_size = face_det_batch_size
+
+ print("face_detect_ov images[0].shape: ", images[0].shape)
+ while 1:
+ predictions = []
+ try:
+ for i in tqdm(range(0, len(images), batch_size)):
+ predictions.extend(detector.get_detections_for_batch(np.array(images[i : i + batch_size])))
+ except RuntimeError:
+ if batch_size == 1:
+ raise RuntimeError("Image too big to run face detection on GPU. Please use the --resize_factor argument")
+ batch_size //= 2
+ print("Recovering from OOM error; New batch size: {}".format(batch_size))
+ continue
+ break
+
+ results = []
+ pady1, pady2, padx1, padx2 = pads
+ for rect, image in zip(predictions, images):
+ if rect is None:
+ # check this frame where the face was not detected.
+ cv2.imwrite("temp/faulty_frame.jpg", image)
+ raise ValueError("Face not detected! Ensure the video contains a face in all the frames.")
+
+ y1 = max(0, rect[1] - pady1)
+ y2 = min(image.shape[0], rect[3] + pady2)
+ x1 = max(0, rect[0] - padx1)
+ x2 = min(image.shape[1], rect[2] + padx2)
+
+ results.append([x1, y1, x2, y2])
+
+ boxes = np.array(results)
+ if not nosmooth:
+ boxes = get_smoothened_boxes(boxes, T=5)
+ results = [[image[y1:y2, x1:x2], (y1, y2, x1, x2)] for image, (x1, y1, x2, y2) in zip(images, boxes)]
+
+ del detector
+ return results
+
+
+def datagen(frames, mels, box, static, face_det_batch_size, pads, nosmooth, img_size, wav2lip_batch_size, path_to_detector):
+ img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
+
+ if box[0] == -1:
+ if not static:
+ # BGR2RGB for CNN face detection
+ face_det_results = face_detect_ov(frames, "CPU", face_det_batch_size, pads, nosmooth, path_to_detector)
+ else:
+ face_det_results = face_detect_ov([frames[0]], "CPU", face_det_batch_size, pads, nosmooth, path_to_detector)
+ else:
+ print("Using the specified bounding box instead of face detection...")
+ y1, y2, x1, x2 = box
+ face_det_results = [[f[y1:y2, x1:x2], (y1, y2, x1, x2)] for f in frames]
+
+ for i, m in enumerate(mels):
+ idx = 0 if static else i % len(frames)
+ frame_to_save = frames[idx].copy()
+ face, coords = face_det_results[idx].copy()
+
+ face = cv2.resize(face, (img_size, img_size))
+
+ img_batch.append(face)
+ mel_batch.append(m)
+ frame_batch.append(frame_to_save)
+ coords_batch.append(coords)
+
+ if len(img_batch) >= wav2lip_batch_size:
+ img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
+
+ img_masked = img_batch.copy()
+ img_masked[:, img_size // 2 :] = 0
+
+ img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.0
+ mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
+
+ yield img_batch, mel_batch, frame_batch, coords_batch
+ img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
+
+ if len(img_batch) > 0:
+ img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
+
+ img_masked = img_batch.copy()
+ img_masked[:, img_size // 2 :] = 0
+
+ img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.0
+ mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
+
+ yield img_batch, mel_batch, frame_batch, coords_batch
+
+
+def ov_inference(
+ face_path,
+ audio_path,
+ face_detection_path="models/face_detection.xml",
+ wav2lip_path="models/wav2lip.xml",
+ inference_device="CPU",
+ wav2lip_batch_size=128,
+ outfile="results/result_voice.mp4",
+ resize_factor=1,
+ rotate=False,
+ crop=[0, -1, 0, -1],
+ mel_step_size=16,
+ box=[-1, -1, -1, -1],
+ static=False,
+ img_size=96,
+ face_det_batch_size=16,
+ pads=[0, 10, 0, 0],
+ nosmooth=False,
+):
+ print("Reading video frames...")
+
+ video_stream = cv2.VideoCapture(face_path)
+ fps = video_stream.get(cv2.CAP_PROP_FPS)
+
+ full_frames = []
+ while 1:
+ still_reading, frame = video_stream.read()
+ if not still_reading:
+ video_stream.release()
+ break
+ if resize_factor > 1:
+ frame = cv2.resize(frame, (frame.shape[1] // resize_factor, frame.shape[0] // resize_factor))
+
+ if rotate:
+ frame = cv2.rotate(frame, cv2.cv2.ROTATE_90_CLOCKWISE)
+
+ y1, y2, x1, x2 = crop
+ if x2 == -1:
+ x2 = frame.shape[1]
+ if y2 == -1:
+ y2 = frame.shape[0]
+
+ frame = frame[y1:y2, x1:x2]
+
+ full_frames.append(frame)
+
+ print("Number of frames available for inference: " + str(len(full_frames)))
+
+ core = ov.Core()
+
+ if not audio_path.endswith(".wav"):
+ print("Extracting raw audio...")
+ command = "ffmpeg -y -i {} -strict -2 {}".format(audio_path, "temp/temp.wav")
+
+ subprocess.call(command, shell=True)
+ audio_path = "temp/temp.wav"
+
+ wav = audio.load_wav(audio_path, 16000)
+ mel = audio.melspectrogram(wav)
+ print(mel.shape)
+
+ if np.isnan(mel.reshape(-1)).sum() > 0:
+ raise ValueError("Mel contains nan! Using a TTS voice? Add a small epsilon noise to the wav file and try again")
+
+ mel_chunks = []
+ mel_idx_multiplier = 80.0 / fps
+ i = 0
+ while 1:
+ start_idx = int(i * mel_idx_multiplier)
+ if start_idx + mel_step_size > len(mel[0]):
+ mel_chunks.append(mel[:, len(mel[0]) - mel_step_size :])
+ break
+ mel_chunks.append(mel[:, start_idx : start_idx + mel_step_size])
+ i += 1
+
+ print("Length of mel chunks: {}".format(len(mel_chunks)))
+
+ full_frames = full_frames[: len(mel_chunks)]
+ batch_size = wav2lip_batch_size
+ gen = datagen(full_frames.copy(), mel_chunks, box, static, face_det_batch_size, pads, nosmooth, img_size, wav2lip_batch_size, face_detection_path)
+ for i, (img_batch, mel_batch, frames, coords) in enumerate(tqdm(gen, total=int(np.ceil(float(len(mel_chunks)) / batch_size)))):
+ if i == 0:
+ img_batch = torch.FloatTensor(np.transpose(img_batch, (0, 3, 1, 2))).to(device)
+ mel_batch = torch.FloatTensor(np.transpose(mel_batch, (0, 3, 1, 2))).to(device)
+ compiled_wav2lip_model = core.compile_model(wav2lip_path, inference_device)
+ print("Model loaded")
+
+ frame_h, frame_w = full_frames[0].shape[:-1]
+ out = cv2.VideoWriter("Wav2Lip/temp/result.avi", cv2.VideoWriter_fourcc(*"DIVX"), fps, (frame_w, frame_h))
+ pred_ov = compiled_wav2lip_model({"audio_sequences": mel_batch.numpy(), "face_sequences": img_batch.numpy()})[0]
+ else:
+ img_batch = np.transpose(img_batch, (0, 3, 1, 2))
+ mel_batch = np.transpose(mel_batch, (0, 3, 1, 2))
+ pred_ov = compiled_wav2lip_model({"audio_sequences": mel_batch, "face_sequences": img_batch})[0]
+
+ pred_ov = compiled_wav2lip_model({"audio_sequences": mel_batch, "face_sequences": img_batch})[0]
+ pred_ov = pred_ov.transpose(0, 2, 3, 1) * 255.0
+ for p, f, c in zip(pred_ov, frames, coords):
+ y1, y2, x1, x2 = c
+ p = cv2.resize(p.astype(np.uint8), (x2 - x1, y2 - y1))
+
+ f[y1:y2, x1:x2] = p
+ out.write(f)
+
+ out.release()
+
+ command = "ffmpeg -y -i {} -i {} -strict -2 -q:v 1 {}".format(audio_path, "Wav2Lip/temp/result.avi", outfile)
+ subprocess.call(command, shell=True)
+
+ return outfile
diff --git a/notebooks/wav2lip/ov_wav2lip_helper.py b/notebooks/wav2lip/ov_wav2lip_helper.py
new file mode 100644
index 00000000000..18811f409cf
--- /dev/null
+++ b/notebooks/wav2lip/ov_wav2lip_helper.py
@@ -0,0 +1,64 @@
+import numpy as np
+import os
+from pathlib import Path
+
+from huggingface_hub import hf_hub_download
+import torch
+
+import openvino as ov
+
+from notebook_utils import download_file
+from Wav2Lip.face_detection.detection.sfd.net_s3fd import s3fd
+from Wav2Lip.models import Wav2Lip
+
+
+def _load(checkpoint_path):
+ checkpoint = torch.load(checkpoint_path, map_location=lambda storage, loc: storage)
+ return checkpoint
+
+
+def load_model(path):
+ model = Wav2Lip()
+ print("Load checkpoint from: {}".format(path))
+ checkpoint = _load(path)
+ s = checkpoint["state_dict"]
+ new_s = {}
+ for k, v in s.items():
+ new_s[k.replace("module.", "")] = v
+ model.load_state_dict(new_s)
+
+ return model.eval()
+
+
+def download_and_convert_models(ov_face_detection_model_path, ov_wav2lip_model_path):
+ models_urls = {"s3fd": "https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth"}
+ path_to_detector = "checkpoints/face_detection.pth"
+ # Convert Face Detection Model
+ print("Convert Face Detection Model ...")
+ if not os.path.isfile(path_to_detector):
+ download_file(models_urls["s3fd"])
+ if not os.path.exists("checkpoints"):
+ os.mkdir("checkpoints")
+ os.replace("s3fd-619a316812.pth", path_to_detector)
+ model_weights = torch.load(path_to_detector)
+
+ face_detector = s3fd()
+ face_detector.load_state_dict(model_weights)
+
+ if not ov_face_detection_model_path.exists():
+ face_detection_dummy_inputs = torch.FloatTensor(np.random.rand(1, 3, 768, 576))
+ face_detection_ov_model = ov.convert_model(face_detector, example_input=face_detection_dummy_inputs)
+ ov.save_model(face_detection_ov_model, ov_face_detection_model_path)
+ print("Converted face detection OpenVINO model: ", ov_face_detection_model_path)
+
+ print("Convert Wav2Lip Model ...")
+ path_to_wav2lip = hf_hub_download(repo_id="numz/wav2lip_studio", filename="Wav2lip/wav2lip.pth", local_dir="checkpoints")
+ wav2lip = load_model(path_to_wav2lip)
+ img_batch = torch.FloatTensor(np.random.rand(123, 6, 96, 96))
+ mel_batch = torch.FloatTensor(np.random.rand(123, 1, 80, 16))
+
+ if not ov_wav2lip_model_path.exists():
+ example_inputs = {"audio_sequences": mel_batch, "face_sequences": img_batch}
+ wav2lip_ov_model = ov.convert_model(wav2lip, example_input=example_inputs)
+ ov.save_model(wav2lip_ov_model, ov_wav2lip_model_path)
+ print("Converted face detection OpenVINO model: ", ov_wav2lip_model_path)
diff --git a/notebooks/wav2lip/wav2lip.ipynb b/notebooks/wav2lip/wav2lip.ipynb
new file mode 100644
index 00000000000..8be1de1f6a3
--- /dev/null
+++ b/notebooks/wav2lip/wav2lip.ipynb
@@ -0,0 +1,411 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "36104004-1d8e-4890-ab87-990ade94dcc5",
+ "metadata": {},
+ "source": [
+ "# Wav2Lip: Accurately Lip-syncing Videos and OpenVINO\n",
+ "\n",
+ "Lip sync technologies are widely used for digital human use cases, which enhance the user experience in dialog scenarios.\n",
+ "\n",
+ "[Wav2Lip](https://github.com/Rudrabha/Wav2Lip) is an approach to generate accurate 2D lip-synced videos in the wild with only one video and an audio clip. Wav2Lip leverages an accurate lip-sync “expert\" model and consecutive face frames for accurate, natural lip motion generation.\n",
+ "\n",
+ "\n",
+ "\n",
+ "In this notebook, we introduce how to enable and optimize Wav2Lippipeline with OpenVINO. This is adaptation of the blog article [Enable 2D Lip Sync Wav2Lip Pipeline with OpenVINO Runtime](https://blog.openvino.ai/blog-posts/enable-2d-lip-sync-wav2lip-pipeline-with-openvino-runtime).\n",
+ "\n",
+ "Here is Wav2Lip pipeline overview:\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Table of contents:\n",
+ "\n",
+ "- [Prerequisites](#Prerequisites)\n",
+ "- [Convert the model to OpenVINO IR](#Convert-the-model-to-OpenVINO-IR)\n",
+ "- [Compiling models and prepare pipeline](#Compiling-models-and-prepare-pipeline)\n",
+ "- [Interactive inference](#Interactive-inference)\n",
+ "\n",
+ "### Installation Instructions\n",
+ "\n",
+ "This is a self-contained example that relies solely on its own code.\n",
+ "\n",
+ "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
+ "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "62451f48-e48c-4d1a-b41d-d112b703939f",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "0aba4ed8-d668-4295-a1f3-d42a82cdbf44",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import requests\n",
+ "from pathlib import Path\n",
+ "\n",
+ "\n",
+ "r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\",\n",
+ ")\n",
+ "open(\"notebook_utils.py\", \"w\").write(r.text)\n",
+ "\n",
+ "r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/pip_helper.py\",\n",
+ ")\n",
+ "open(\"pip_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "from pip_helper import pip_install\n",
+ "\n",
+ "pip_install(\"-q\", \"openvino>=2024.4.0\")\n",
+ "pip_install(\n",
+ " \"-q\",\n",
+ " \"huggingface_hub\",\n",
+ " \"torch>=2.1\",\n",
+ " \"gradio>=4.19\",\n",
+ " \"librosa==0.9.2\",\n",
+ " \"opencv-contrib-python\",\n",
+ " \"opencv-python\",\n",
+ " \"tqdm\",\n",
+ " \"numba\",\n",
+ " \"numpy<2\",\n",
+ " \"--extra-index-url\",\n",
+ " \"https://download.pytorch.org/whl/cpu\",\n",
+ ")\n",
+ "\n",
+ "helpers = [\"gradio_helper.py\", \"ov_inference.py\", \"ov_wav2lip_helper.py\"]\n",
+ "for helper_file in helpers:\n",
+ " if not Path(helper_file).exists():\n",
+ " r = requests.get(url=f\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/wav2lip/{helper_file}\")\n",
+ " open(helper_file, \"w\").write(r.text)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "dc14eca8-15c7-4e61-9e26-9d1172562239",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import sys\n",
+ "\n",
+ "\n",
+ "wav2lip_path = Path(\"Wav2Lip\")\n",
+ "\n",
+ "if not wav2lip_path.exists():\n",
+ " exit_code = os.system(\"git clone https://github.com/Rudrabha/Wav2Lip\")\n",
+ " if exit_code != 0:\n",
+ " raise Exception(\"Failed to clone the repository!\")\n",
+ "\n",
+ "sys.path.insert(0, str(wav2lip_path))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0aedd043-5078-4685-a199-6c5d523122b3",
+ "metadata": {},
+ "source": [
+ "Download example files."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "06198a5a-6646-4bcc-abb3-8ed3e98be33d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from notebook_utils import download_file\n",
+ "\n",
+ "\n",
+ "download_file(\"https://github.com/sammysun0711/openvino_aigc_samples/blob/main/Wav2Lip/data_audio_sun_5s.wav?raw=true\")\n",
+ "download_file(\"https://github.com/sammysun0711/openvino_aigc_samples/blob/main/Wav2Lip/data_video_sun_5s.mp4?raw=true\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "58cfa3ef-ce99-455c-ae23-d3092c2b4905",
+ "metadata": {},
+ "source": [
+ "### Convert the model to OpenVINO IR\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "You don't need to download checkpoints and load models, just call the helper function `download_and_convert_models`. It takes care about it and will convert both model in OpenVINO format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "73728210-64dd-4791-b2db-59098a23ab7d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ov_wav2lip_helper import download_and_convert_models\n",
+ "\n",
+ "\n",
+ "OV_FACE_DETECTION_MODEL_PATH = Path(\"models/face_detection.xml\")\n",
+ "OV_WAV2LIP_MODEL_PATH = Path(\"models/wav2lip.xml\")\n",
+ "\n",
+ "download_and_convert_models(OV_FACE_DETECTION_MODEL_PATH, OV_WAV2LIP_MODEL_PATH)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8e645fe5-c1c5-4db3-8973-3d65864e00af",
+ "metadata": {},
+ "source": [
+ "## Compiling models and prepare pipeline\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3b6ad00a-d3c9-4de4-8d74-be98a193c1da",
+ "metadata": {},
+ "source": [
+ "Select device from dropdown list for running inference using OpenVINO."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "4257000c-83da-4ab2-81ef-0931992207b6",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "49c1f2d4355547eab4415dc919373540",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')"
+ ]
+ },
+ "execution_count": 5,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "from notebook_utils import device_widget\n",
+ "\n",
+ "device = device_widget()\n",
+ "\n",
+ "device"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d7f544dd-bdd0-42d7-81a0-4c38467e7531",
+ "metadata": {},
+ "source": [
+ "`ov_inference.py` is an adaptation of original pipeline that has only cli-interface. `ov_inference` allows running the inference using python API and converted OpenVINO models."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6032dd4f-8d80-4a63-aa01-466fb96c1e1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ov_inference import ov_inference\n",
+ "\n",
+ "\n",
+ "if not os.path.exists(\"results\"):\n",
+ " os.mkdir(\"results\")\n",
+ "\n",
+ "ov_inference(\n",
+ " \"data_video_sun_5s.mp4\",\n",
+ " \"data_audio_sun_5s.wav\",\n",
+ " face_detection_path=OV_FACE_DETECTION_MODEL_PATH,\n",
+ " wav2lip_path=OV_WAV2LIP_MODEL_PATH,\n",
+ " inference_device=device.value,\n",
+ " outfile=\"results/result_voice.mp4\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0933d0af-4934-4348-8f33-a989e7f2ae74",
+ "metadata": {},
+ "source": [
+ "Here is an example to compare the original video and the generated video after the Wav2Lip pipeline:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "5ceedf90-f4b5-4d6d-a7da-2a1487387c49",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ ""
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "from IPython.display import Video, Audio\n",
+ "\n",
+ "Video(\"data_video_sun_5s.mp4\", embed=True)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "7ed7fd06-0f0a-4530-b12a-f115fc3eaf08",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ " \n",
+ " "
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "Audio(\"data_audio_sun_5s.wav\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8364cd95",
+ "metadata": {},
+ "source": [
+ "The generated video:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "0bfa7d0a-5525-4a60-aea2-01808d30f767",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ ""
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "Video(\"results/result_voice.mp4\", embed=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41a4fefe",
+ "metadata": {},
+ "source": [
+ "## Interactive inference\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "063d1573",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from gradio_helper import make_demo\n",
+ "\n",
+ "\n",
+ "demo = make_demo(fn=ov_inference)\n",
+ "\n",
+ "try:\n",
+ " demo.queue().launch(debug=True)\n",
+ "except Exception:\n",
+ " demo.queue().launch(debug=True, share=True)\n",
+ "# if you are launching remotely, specify server_name and server_port\n",
+ "# demo.launch(server_name='your server name', server_port='server port in int')\n",
+ "# Read more in the docs: https://gradio.app/docs/\""
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.12"
+ },
+ "openvino_notebooks": {
+ "imageUrl": "https://github.com/user-attachments/assets/11d2fb00-4b5a-45f3-b13b-49636b0d48b1",
+ "tags": {
+ "categories": [
+ "Model Demos",
+ "AI Trends"
+ ],
+ "libraries": [],
+ "other": [],
+ "tasks": [
+ "Audio-to-Video",
+ "Lip-Sync"
+ ]
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/selector/src/shared/notebook-tags.js b/selector/src/shared/notebook-tags.js
index b831e8ed66b..5a2e9876086 100644
--- a/selector/src/shared/notebook-tags.js
+++ b/selector/src/shared/notebook-tags.js
@@ -19,6 +19,7 @@ export const TASKS = /** @type {const} */ ({
TEXT_TO_AUDIO: 'Text-to-Audio',
TEXT_TO_SPEECH: 'Text-to-Speech',
AUDIO_TO_TEXT: 'Audio-to-Text',
+ AUDIO_TO_VIDEO: 'Audio-to-Video',
VISUAL_QUESTION_ANSWERING: 'Visual Question Answering',
IMAGE_CAPTIONING: 'Image Captioning',
FEATURE_EXTRACTION: 'Feature Extraction',
@@ -27,6 +28,7 @@ export const TASKS = /** @type {const} */ ({
TEXT_TO_VIDEO_RETRIEVAL: 'Text-to-Video Retrieval',
IMAGE_TO_3D: 'Image-to-3D',
IMAGE_TO_VIDEO: 'Image-to-Video',
+ LIP_SYNC: 'Lip-Sync'
},
CV: {
IMAGE_CLASSIFICATION: 'Image Classification',
diff --git a/utils/pip_helper.py b/utils/pip_helper.py
index e284b4a5331..18116023b9e 100644
--- a/utils/pip_helper.py
+++ b/utils/pip_helper.py
@@ -1,5 +1,4 @@
import sys
-import platform
def pip_install(*args):
@@ -8,4 +7,4 @@ def pip_install(*args):
cli_args = []
for arg in args:
cli_args.extend(str(arg).split(" "))
- subprocess.run([sys.executable, "-m", "pip", "install", *cli_args], shell=(platform.system() == "Windows"), check=True)
+ subprocess.run([sys.executable, "-m", "pip", "install", *cli_args], check=True)
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "62451f48-e48c-4d1a-b41d-d112b703939f",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "0aba4ed8-d668-4295-a1f3-d42a82cdbf44",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import requests\n",
+ "from pathlib import Path\n",
+ "\n",
+ "\n",
+ "r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\",\n",
+ ")\n",
+ "open(\"notebook_utils.py\", \"w\").write(r.text)\n",
+ "\n",
+ "r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/pip_helper.py\",\n",
+ ")\n",
+ "open(\"pip_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "from pip_helper import pip_install\n",
+ "\n",
+ "pip_install(\"-q\", \"openvino>=2024.4.0\")\n",
+ "pip_install(\n",
+ " \"-q\",\n",
+ " \"huggingface_hub\",\n",
+ " \"torch>=2.1\",\n",
+ " \"gradio>=4.19\",\n",
+ " \"librosa==0.9.2\",\n",
+ " \"opencv-contrib-python\",\n",
+ " \"opencv-python\",\n",
+ " \"tqdm\",\n",
+ " \"numba\",\n",
+ " \"numpy<2\",\n",
+ " \"--extra-index-url\",\n",
+ " \"https://download.pytorch.org/whl/cpu\",\n",
+ ")\n",
+ "\n",
+ "helpers = [\"gradio_helper.py\", \"ov_inference.py\", \"ov_wav2lip_helper.py\"]\n",
+ "for helper_file in helpers:\n",
+ " if not Path(helper_file).exists():\n",
+ " r = requests.get(url=f\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/wav2lip/{helper_file}\")\n",
+ " open(helper_file, \"w\").write(r.text)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "dc14eca8-15c7-4e61-9e26-9d1172562239",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import sys\n",
+ "\n",
+ "\n",
+ "wav2lip_path = Path(\"Wav2Lip\")\n",
+ "\n",
+ "if not wav2lip_path.exists():\n",
+ " exit_code = os.system(\"git clone https://github.com/Rudrabha/Wav2Lip\")\n",
+ " if exit_code != 0:\n",
+ " raise Exception(\"Failed to clone the repository!\")\n",
+ "\n",
+ "sys.path.insert(0, str(wav2lip_path))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0aedd043-5078-4685-a199-6c5d523122b3",
+ "metadata": {},
+ "source": [
+ "Download example files."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "06198a5a-6646-4bcc-abb3-8ed3e98be33d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from notebook_utils import download_file\n",
+ "\n",
+ "\n",
+ "download_file(\"https://github.com/sammysun0711/openvino_aigc_samples/blob/main/Wav2Lip/data_audio_sun_5s.wav?raw=true\")\n",
+ "download_file(\"https://github.com/sammysun0711/openvino_aigc_samples/blob/main/Wav2Lip/data_video_sun_5s.mp4?raw=true\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "58cfa3ef-ce99-455c-ae23-d3092c2b4905",
+ "metadata": {},
+ "source": [
+ "### Convert the model to OpenVINO IR\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "You don't need to download checkpoints and load models, just call the helper function `download_and_convert_models`. It takes care about it and will convert both model in OpenVINO format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "73728210-64dd-4791-b2db-59098a23ab7d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ov_wav2lip_helper import download_and_convert_models\n",
+ "\n",
+ "\n",
+ "OV_FACE_DETECTION_MODEL_PATH = Path(\"models/face_detection.xml\")\n",
+ "OV_WAV2LIP_MODEL_PATH = Path(\"models/wav2lip.xml\")\n",
+ "\n",
+ "download_and_convert_models(OV_FACE_DETECTION_MODEL_PATH, OV_WAV2LIP_MODEL_PATH)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8e645fe5-c1c5-4db3-8973-3d65864e00af",
+ "metadata": {},
+ "source": [
+ "## Compiling models and prepare pipeline\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3b6ad00a-d3c9-4de4-8d74-be98a193c1da",
+ "metadata": {},
+ "source": [
+ "Select device from dropdown list for running inference using OpenVINO."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "4257000c-83da-4ab2-81ef-0931992207b6",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "49c1f2d4355547eab4415dc919373540",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')"
+ ]
+ },
+ "execution_count": 5,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "from notebook_utils import device_widget\n",
+ "\n",
+ "device = device_widget()\n",
+ "\n",
+ "device"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d7f544dd-bdd0-42d7-81a0-4c38467e7531",
+ "metadata": {},
+ "source": [
+ "`ov_inference.py` is an adaptation of original pipeline that has only cli-interface. `ov_inference` allows running the inference using python API and converted OpenVINO models."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6032dd4f-8d80-4a63-aa01-466fb96c1e1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ov_inference import ov_inference\n",
+ "\n",
+ "\n",
+ "if not os.path.exists(\"results\"):\n",
+ " os.mkdir(\"results\")\n",
+ "\n",
+ "ov_inference(\n",
+ " \"data_video_sun_5s.mp4\",\n",
+ " \"data_audio_sun_5s.wav\",\n",
+ " face_detection_path=OV_FACE_DETECTION_MODEL_PATH,\n",
+ " wav2lip_path=OV_WAV2LIP_MODEL_PATH,\n",
+ " inference_device=device.value,\n",
+ " outfile=\"results/result_voice.mp4\",\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0933d0af-4934-4348-8f33-a989e7f2ae74",
+ "metadata": {},
+ "source": [
+ "Here is an example to compare the original video and the generated video after the Wav2Lip pipeline:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "5ceedf90-f4b5-4d6d-a7da-2a1487387c49",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ ""
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "from IPython.display import Video, Audio\n",
+ "\n",
+ "Video(\"data_video_sun_5s.mp4\", embed=True)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "7ed7fd06-0f0a-4530-b12a-f115fc3eaf08",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ " \n",
+ " "
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "Audio(\"data_audio_sun_5s.wav\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8364cd95",
+ "metadata": {},
+ "source": [
+ "The generated video:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "0bfa7d0a-5525-4a60-aea2-01808d30f767",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ ""
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "Video(\"results/result_voice.mp4\", embed=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "41a4fefe",
+ "metadata": {},
+ "source": [
+ "## Interactive inference\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "063d1573",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from gradio_helper import make_demo\n",
+ "\n",
+ "\n",
+ "demo = make_demo(fn=ov_inference)\n",
+ "\n",
+ "try:\n",
+ " demo.queue().launch(debug=True)\n",
+ "except Exception:\n",
+ " demo.queue().launch(debug=True, share=True)\n",
+ "# if you are launching remotely, specify server_name and server_port\n",
+ "# demo.launch(server_name='your server name', server_port='server port in int')\n",
+ "# Read more in the docs: https://gradio.app/docs/\""
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.12"
+ },
+ "openvino_notebooks": {
+ "imageUrl": "https://github.com/user-attachments/assets/11d2fb00-4b5a-45f3-b13b-49636b0d48b1",
+ "tags": {
+ "categories": [
+ "Model Demos",
+ "AI Trends"
+ ],
+ "libraries": [],
+ "other": [],
+ "tasks": [
+ "Audio-to-Video",
+ "Lip-Sync"
+ ]
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/selector/src/shared/notebook-tags.js b/selector/src/shared/notebook-tags.js
index b831e8ed66b..5a2e9876086 100644
--- a/selector/src/shared/notebook-tags.js
+++ b/selector/src/shared/notebook-tags.js
@@ -19,6 +19,7 @@ export const TASKS = /** @type {const} */ ({
TEXT_TO_AUDIO: 'Text-to-Audio',
TEXT_TO_SPEECH: 'Text-to-Speech',
AUDIO_TO_TEXT: 'Audio-to-Text',
+ AUDIO_TO_VIDEO: 'Audio-to-Video',
VISUAL_QUESTION_ANSWERING: 'Visual Question Answering',
IMAGE_CAPTIONING: 'Image Captioning',
FEATURE_EXTRACTION: 'Feature Extraction',
@@ -27,6 +28,7 @@ export const TASKS = /** @type {const} */ ({
TEXT_TO_VIDEO_RETRIEVAL: 'Text-to-Video Retrieval',
IMAGE_TO_3D: 'Image-to-3D',
IMAGE_TO_VIDEO: 'Image-to-Video',
+ LIP_SYNC: 'Lip-Sync'
},
CV: {
IMAGE_CLASSIFICATION: 'Image Classification',
diff --git a/utils/pip_helper.py b/utils/pip_helper.py
index e284b4a5331..18116023b9e 100644
--- a/utils/pip_helper.py
+++ b/utils/pip_helper.py
@@ -1,5 +1,4 @@
import sys
-import platform
def pip_install(*args):
@@ -8,4 +7,4 @@ def pip_install(*args):
cli_args = []
for arg in args:
cli_args.extend(str(arg).split(" "))
- subprocess.run([sys.executable, "-m", "pip", "install", *cli_args], shell=(platform.system() == "Windows"), check=True)
+ subprocess.run([sys.executable, "-m", "pip", "install", *cli_args], check=True)