diff --git a/.dev_scripts/benchmark_regression/1-benchmark_valid.py b/.dev_scripts/benchmark_regression/1-benchmark_valid.py
index e3cb1ac0057..3fbf16e707d 100644
--- a/.dev_scripts/benchmark_regression/1-benchmark_valid.py
+++ b/.dev_scripts/benchmark_regression/1-benchmark_valid.py
@@ -128,18 +128,19 @@ def inference(config_file, checkpoint, classes, args):
if args.flops:
from mmcv.cnn.utils import get_model_complexity_info
- if hasattr(model, 'extract_feat'):
- model.forward = model.extract_feat
- flops, params = get_model_complexity_info(
- model,
- input_shape=(3, ) + resolution,
- print_per_layer_stat=False,
- as_strings=args.flops_str)
- result['flops'] = flops if args.flops_str else int(flops)
- result['params'] = params if args.flops_str else int(params)
- else:
- result['flops'] = ''
- result['params'] = ''
+ with torch.no_grad():
+ if hasattr(model, 'extract_feat'):
+ model.forward = model.extract_feat
+ flops, params = get_model_complexity_info(
+ model,
+ input_shape=(3, ) + resolution,
+ print_per_layer_stat=False,
+ as_strings=args.flops_str)
+ result['flops'] = flops if args.flops_str else int(flops)
+ result['params'] = params if args.flops_str else int(params)
+ else:
+ result['flops'] = ''
+ result['params'] = ''
return result
@@ -199,6 +200,9 @@ def main(args):
summary_data = {}
for model_name, model_info in models.items():
+ if model_info.config is None:
+ continue
+
config = Path(model_info.config)
assert config.exists(), f'{model_name}: {config} not found.'
diff --git a/.dev_scripts/benchmark_regression/2-benchmark_test.py b/.dev_scripts/benchmark_regression/2-benchmark_test.py
index bbf316153b0..9274a980711 100644
--- a/.dev_scripts/benchmark_regression/2-benchmark_test.py
+++ b/.dev_scripts/benchmark_regression/2-benchmark_test.py
@@ -163,6 +163,10 @@ def test(args):
preview_script = ''
for model_info in models.values():
+
+ if model_info.results is None:
+ continue
+
script_path = create_test_job_batch(commands, model_info, args, port,
script_name)
preview_script = script_path or preview_script
@@ -288,6 +292,9 @@ def summary(args):
summary_data = {}
for model_name, model_info in models.items():
+ if model_info.results is None:
+ continue
+
# Skip if not found result file.
result_file = work_dir / model_name / 'result.pkl'
if not result_file.exists():
diff --git a/.github/workflows/build.yml b/.github/workflows/build.yml
index 5ccceeac0ba..ff209335ee0 100644
--- a/.github/workflows/build.yml
+++ b/.github/workflows/build.yml
@@ -9,9 +9,8 @@ on:
- 'README.md'
- 'README_zh-CN.md'
- 'model-index.yml'
- - 'configs/**.md'
+ - 'configs/**'
- 'docs/**'
- - 'docs_zh-CN/**'
- 'demo/**'
- '.dev_scripts/**'
@@ -20,9 +19,8 @@ on:
- 'README.md'
- 'README_zh-CN.md'
- 'model-index.yml'
- - 'configs/**.md'
+ - 'configs/**'
- 'docs/**'
- - 'docs_zh-CN/**'
- 'demo/**'
- '.dev_scripts/**'
diff --git a/README.md b/README.md
index 50f2801f879..4c774b90870 100644
--- a/README.md
+++ b/README.md
@@ -59,6 +59,13 @@ The master branch works with **PyTorch 1.5+**.
## What's new
+v0.20.0 was released in 30/1/2022.
+
+Highlights of the new version:
+- Support **K-fold cross-validation**. The tutorial will be released later.
+- Support **HRNet**, **ConvNeXt**, **Twins** and **EfficientNet**.
+- Support model conversion from PyTorch to **Core ML** by a tool.
+
v0.19.0 was released in 31/12/2021.
Highlights of the new version:
@@ -68,12 +75,6 @@ Highlights of the new version:
- Support **DeiT** & **Conformer** backbone and checkpoints.
- Provide a **CAM visualization** tool based on [pytorch-grad-cam](https://github.com/jacobgil/pytorch-grad-cam), and detailed [user guide](https://mmclassification.readthedocs.io/en/latest/tools/visualization.html#class-activation-map-visualization)!
-v0.18.0 was released in 30/11/2021.
-
-Highlights of the new version:
-- Support **MLP-Mixer** backbone and provide pre-trained checkpoints.
-- Add a tool to **visualize the learning rate curve** of the training phase. Welcome to use with the [tutorial](https://mmclassification.readthedocs.io/en/latest/tools/visualization.html#learning-rate-schedule-visualization)!
-
Please refer to [changelog.md](docs/en/changelog.md) for more details and other release history.
## Installation
@@ -123,9 +124,10 @@ Results and models are available in the [model zoo](https://mmclassification.rea
- [x] [DeiT](https://github.com/open-mmlab/mmclassification/tree/master/configs/deit)
- [x] [Conformer](https://github.com/open-mmlab/mmclassification/tree/master/configs/conformer)
- [x] [T2T-ViT](https://github.com/open-mmlab/mmclassification/tree/master/configs/t2t_vit)
-- [ ] EfficientNet
-- [ ] Twins
-- [ ] HRNet
+- [x] [Twins](https://github.com/open-mmlab/mmclassification/tree/master/configs/twins)
+- [x] [EfficientNet](https://github.com/open-mmlab/mmclassification/tree/master/configs/efficientnet)
+- [x] [ConvNeXt](https://github.com/open-mmlab/mmclassification/tree/master/configs/convnext)
+- [x] [HRNet](https://github.com/open-mmlab/mmclassification/tree/master/configs/hrnet)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 8fb786c4b31..815ea07d070 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -57,6 +57,13 @@ MMClassification 是一款基于 PyTorch 的开源图像分类工具箱,是 [O
## 更新日志
+2022/1/30 发布了 v0.20.0 版本
+
+新版本亮点:
+- 支持 **K 折交叉验证** 工具。相应文档会在后续添加。
+- 支持了 **HRNet**,**ConvNeXt**,**Twins** 以及 **EfficientNet** 四个主干网络,欢迎使用!
+- 支持了从 PyTorch 模型到 Core-ML 模型的转换工具。
+
2021/12/31 发布了 v0.19.0 版本
新版本亮点:
@@ -66,12 +73,6 @@ MMClassification 是一款基于 PyTorch 的开源图像分类工具箱,是 [O
- 支持了 **DeiT** 和 **Conformer** 主干网络,并提供了预训练模型。
- 提供了一个 **CAM 可视化** 工具。该工具基于 [pytorch-grad-cam](https://github.com/jacobgil/pytorch-grad-cam),我们提供了详细的 [使用教程](https://mmclassification.readthedocs.io/en/latest/tools/visualization.html#class-activation-map-visualization)!
-2021/11/30 发布了 v0.18.0 版本
-
-新版本亮点:
-- 支持了 **MLP-Mixer** 主干网络,欢迎使用!
-- 添加了一个**可视化学习率曲线**的工具,可以参考[教程](https://mmclassification.readthedocs.io/zh_CN/latest/tools/visualization.html#id3)使用
-
发布历史和更新细节请参考 [更新日志](docs/en/changelog.md)
## 安装
@@ -121,9 +122,10 @@ MMClassification 是一款基于 PyTorch 的开源图像分类工具箱,是 [O
- [x] [DeiT](https://github.com/open-mmlab/mmclassification/tree/master/configs/deit)
- [x] [Conformer](https://github.com/open-mmlab/mmclassification/tree/master/configs/conformer)
- [x] [T2T-ViT](https://github.com/open-mmlab/mmclassification/tree/master/configs/t2t_vit)
-- [ ] EfficientNet
-- [ ] Twins
-- [ ] HRNet
+- [x] [Twins](https://github.com/open-mmlab/mmclassification/tree/master/configs/twins)
+- [x] [EfficientNet](https://github.com/open-mmlab/mmclassification/tree/master/configs/efficientnet)
+- [x] [ConvNeXt](https://github.com/open-mmlab/mmclassification/tree/master/configs/convnext)
+- [x] [HRNet](https://github.com/open-mmlab/mmclassification/tree/master/configs/hrnet)
diff --git a/configs/_base_/models/convnext/convnext-base.py b/configs/_base_/models/convnext/convnext-base.py
new file mode 100644
index 00000000000..7fc5ce71a74
--- /dev/null
+++ b/configs/_base_/models/convnext/convnext-base.py
@@ -0,0 +1,23 @@
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='ConvNeXt',
+ arch='base',
+ out_indices=(3, ),
+ drop_path_rate=0.5,
+ gap_before_final_norm=True,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['LayerNorm'], val=1., bias=0.),
+ ]),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1024,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
diff --git a/configs/_base_/models/convnext/convnext-large.py b/configs/_base_/models/convnext/convnext-large.py
new file mode 100644
index 00000000000..4d9e37c0df9
--- /dev/null
+++ b/configs/_base_/models/convnext/convnext-large.py
@@ -0,0 +1,23 @@
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='ConvNeXt',
+ arch='large',
+ out_indices=(3, ),
+ drop_path_rate=0.5,
+ gap_before_final_norm=True,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['LayerNorm'], val=1., bias=0.),
+ ]),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1536,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
diff --git a/configs/_base_/models/convnext/convnext-small.py b/configs/_base_/models/convnext/convnext-small.py
new file mode 100644
index 00000000000..989ad1d4e63
--- /dev/null
+++ b/configs/_base_/models/convnext/convnext-small.py
@@ -0,0 +1,23 @@
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='ConvNeXt',
+ arch='small',
+ out_indices=(3, ),
+ drop_path_rate=0.4,
+ gap_before_final_norm=True,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['LayerNorm'], val=1., bias=0.),
+ ]),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
diff --git a/configs/_base_/models/convnext/convnext-tiny.py b/configs/_base_/models/convnext/convnext-tiny.py
new file mode 100644
index 00000000000..0b692abb1cb
--- /dev/null
+++ b/configs/_base_/models/convnext/convnext-tiny.py
@@ -0,0 +1,23 @@
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='ConvNeXt',
+ arch='tiny',
+ out_indices=(3, ),
+ drop_path_rate=0.1,
+ gap_before_final_norm=True,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['LayerNorm'], val=1., bias=0.),
+ ]),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
diff --git a/configs/_base_/models/convnext/convnext-xlarge.py b/configs/_base_/models/convnext/convnext-xlarge.py
new file mode 100644
index 00000000000..0c75e32547b
--- /dev/null
+++ b/configs/_base_/models/convnext/convnext-xlarge.py
@@ -0,0 +1,23 @@
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='ConvNeXt',
+ arch='xlarge',
+ out_indices=(3, ),
+ drop_path_rate=0.5,
+ gap_before_final_norm=True,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['LayerNorm'], val=1., bias=0.),
+ ]),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=2048,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
diff --git a/configs/_base_/models/efficientnet_b0.py b/configs/_base_/models/efficientnet_b0.py
new file mode 100644
index 00000000000..d9ba685306c
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b0.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b0'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1280,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b1.py b/configs/_base_/models/efficientnet_b1.py
new file mode 100644
index 00000000000..63e15c88b2f
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b1.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b1'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1280,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b2.py b/configs/_base_/models/efficientnet_b2.py
new file mode 100644
index 00000000000..5edcfa5d5b6
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b2.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b2'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1408,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b3.py b/configs/_base_/models/efficientnet_b3.py
new file mode 100644
index 00000000000..c7c6d6d899e
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b3.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b3'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1536,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b4.py b/configs/_base_/models/efficientnet_b4.py
new file mode 100644
index 00000000000..06840ed559c
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b4.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b4'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1792,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b5.py b/configs/_base_/models/efficientnet_b5.py
new file mode 100644
index 00000000000..a86eebd1904
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b5.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b5'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=2048,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b6.py b/configs/_base_/models/efficientnet_b6.py
new file mode 100644
index 00000000000..4eada1d3251
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b6.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b6'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=2304,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b7.py b/configs/_base_/models/efficientnet_b7.py
new file mode 100644
index 00000000000..1d84ba427f4
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b7.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b7'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=2560,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_b8.py b/configs/_base_/models/efficientnet_b8.py
new file mode 100644
index 00000000000..c9500644dae
--- /dev/null
+++ b/configs/_base_/models/efficientnet_b8.py
@@ -0,0 +1,12 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='EfficientNet', arch='b8'),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=2816,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_em.py b/configs/_base_/models/efficientnet_em.py
new file mode 100644
index 00000000000..abecdbeef6c
--- /dev/null
+++ b/configs/_base_/models/efficientnet_em.py
@@ -0,0 +1,13 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ # `em` means EfficientNet-EdgeTPU-M arch
+ backbone=dict(type='EfficientNet', arch='em', act_cfg=dict(type='ReLU')),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1280,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/efficientnet_es.py b/configs/_base_/models/efficientnet_es.py
new file mode 100644
index 00000000000..911ba4a1826
--- /dev/null
+++ b/configs/_base_/models/efficientnet_es.py
@@ -0,0 +1,13 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ # `es` means EfficientNet-EdgeTPU-S arch
+ backbone=dict(type='EfficientNet', arch='es', act_cfg=dict(type='ReLU')),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1280,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/hrnet/hrnet-w18.py b/configs/_base_/models/hrnet/hrnet-w18.py
new file mode 100644
index 00000000000..f7fbf298d5b
--- /dev/null
+++ b/configs/_base_/models/hrnet/hrnet-w18.py
@@ -0,0 +1,15 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='HRNet', arch='w18'),
+ neck=[
+ dict(type='HRFuseScales', in_channels=(18, 36, 72, 144)),
+ dict(type='GlobalAveragePooling'),
+ ],
+ head=dict(
+ type='LinearClsHead',
+ in_channels=2048,
+ num_classes=1000,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/hrnet/hrnet-w30.py b/configs/_base_/models/hrnet/hrnet-w30.py
new file mode 100644
index 00000000000..babcacac59a
--- /dev/null
+++ b/configs/_base_/models/hrnet/hrnet-w30.py
@@ -0,0 +1,15 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='HRNet', arch='w30'),
+ neck=[
+ dict(type='HRFuseScales', in_channels=(30, 60, 120, 240)),
+ dict(type='GlobalAveragePooling'),
+ ],
+ head=dict(
+ type='LinearClsHead',
+ in_channels=2048,
+ num_classes=1000,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/hrnet/hrnet-w32.py b/configs/_base_/models/hrnet/hrnet-w32.py
new file mode 100644
index 00000000000..2c1e980048d
--- /dev/null
+++ b/configs/_base_/models/hrnet/hrnet-w32.py
@@ -0,0 +1,15 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='HRNet', arch='w32'),
+ neck=[
+ dict(type='HRFuseScales', in_channels=(32, 64, 128, 256)),
+ dict(type='GlobalAveragePooling'),
+ ],
+ head=dict(
+ type='LinearClsHead',
+ in_channels=2048,
+ num_classes=1000,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/hrnet/hrnet-w40.py b/configs/_base_/models/hrnet/hrnet-w40.py
new file mode 100644
index 00000000000..83f65d86467
--- /dev/null
+++ b/configs/_base_/models/hrnet/hrnet-w40.py
@@ -0,0 +1,15 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='HRNet', arch='w40'),
+ neck=[
+ dict(type='HRFuseScales', in_channels=(40, 80, 160, 320)),
+ dict(type='GlobalAveragePooling'),
+ ],
+ head=dict(
+ type='LinearClsHead',
+ in_channels=2048,
+ num_classes=1000,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/hrnet/hrnet-w44.py b/configs/_base_/models/hrnet/hrnet-w44.py
new file mode 100644
index 00000000000..e75dc0f891f
--- /dev/null
+++ b/configs/_base_/models/hrnet/hrnet-w44.py
@@ -0,0 +1,15 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='HRNet', arch='w44'),
+ neck=[
+ dict(type='HRFuseScales', in_channels=(44, 88, 176, 352)),
+ dict(type='GlobalAveragePooling'),
+ ],
+ head=dict(
+ type='LinearClsHead',
+ in_channels=2048,
+ num_classes=1000,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/hrnet/hrnet-w48.py b/configs/_base_/models/hrnet/hrnet-w48.py
new file mode 100644
index 00000000000..f0604958481
--- /dev/null
+++ b/configs/_base_/models/hrnet/hrnet-w48.py
@@ -0,0 +1,15 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='HRNet', arch='w48'),
+ neck=[
+ dict(type='HRFuseScales', in_channels=(48, 96, 192, 384)),
+ dict(type='GlobalAveragePooling'),
+ ],
+ head=dict(
+ type='LinearClsHead',
+ in_channels=2048,
+ num_classes=1000,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/hrnet/hrnet-w64.py b/configs/_base_/models/hrnet/hrnet-w64.py
new file mode 100644
index 00000000000..844c3fe9413
--- /dev/null
+++ b/configs/_base_/models/hrnet/hrnet-w64.py
@@ -0,0 +1,15 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(type='HRNet', arch='w64'),
+ neck=[
+ dict(type='HRFuseScales', in_channels=(64, 128, 256, 512)),
+ dict(type='GlobalAveragePooling'),
+ ],
+ head=dict(
+ type='LinearClsHead',
+ in_channels=2048,
+ num_classes=1000,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
diff --git a/configs/_base_/models/twins_pcpvt_base.py b/configs/_base_/models/twins_pcpvt_base.py
new file mode 100644
index 00000000000..473d7ee817f
--- /dev/null
+++ b/configs/_base_/models/twins_pcpvt_base.py
@@ -0,0 +1,30 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='PCPVT',
+ arch='base',
+ in_channels=3,
+ out_indices=(3, ),
+ qkv_bias=True,
+ norm_cfg=dict(type='LN', eps=1e-06),
+ norm_after_stage=[False, False, False, True],
+ drop_rate=0.0,
+ attn_drop_rate=0.,
+ drop_path_rate=0.3),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(
+ type='LabelSmoothLoss', label_smooth_val=0.1, mode='original'),
+ cal_acc=False),
+ init_cfg=[
+ dict(type='TruncNormal', layer='Linear', std=0.02, bias=0.),
+ dict(type='Constant', layer='LayerNorm', val=1., bias=0.)
+ ],
+ train_cfg=dict(augments=[
+ dict(type='BatchMixup', alpha=0.8, num_classes=1000, prob=0.5),
+ dict(type='BatchCutMix', alpha=1.0, num_classes=1000, prob=0.5)
+ ]))
diff --git a/configs/_base_/models/twins_svt_base.py b/configs/_base_/models/twins_svt_base.py
new file mode 100644
index 00000000000..cabd373961b
--- /dev/null
+++ b/configs/_base_/models/twins_svt_base.py
@@ -0,0 +1,30 @@
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='SVT',
+ arch='base',
+ in_channels=3,
+ out_indices=(3, ),
+ qkv_bias=True,
+ norm_cfg=dict(type='LN'),
+ norm_after_stage=[False, False, False, True],
+ drop_rate=0.0,
+ attn_drop_rate=0.,
+ drop_path_rate=0.3),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(
+ type='LabelSmoothLoss', label_smooth_val=0.1, mode='original'),
+ cal_acc=False),
+ init_cfg=[
+ dict(type='TruncNormal', layer='Linear', std=0.02, bias=0.),
+ dict(type='Constant', layer='LayerNorm', val=1., bias=0.)
+ ],
+ train_cfg=dict(augments=[
+ dict(type='BatchMixup', alpha=0.8, num_classes=1000, prob=0.5),
+ dict(type='BatchCutMix', alpha=1.0, num_classes=1000, prob=0.5)
+ ]))
diff --git a/configs/_base_/schedules/imagenet_bs1024_adamw_swin.py b/configs/_base_/schedules/imagenet_bs1024_adamw_swin.py
index 1a523e44ddd..8ae7042c02a 100644
--- a/configs/_base_/schedules/imagenet_bs1024_adamw_swin.py
+++ b/configs/_base_/schedules/imagenet_bs1024_adamw_swin.py
@@ -24,7 +24,7 @@
min_lr_ratio=1e-2,
warmup='linear',
warmup_ratio=1e-3,
- warmup_iters=20 * 1252,
- warmup_by_epoch=False)
+ warmup_iters=20,
+ warmup_by_epoch=True)
runner = dict(type='EpochBasedRunner', max_epochs=300)
diff --git a/configs/conformer/README.md b/configs/conformer/README.md
index 596911a0aed..ff91ed2081e 100644
--- a/configs/conformer/README.md
+++ b/configs/conformer/README.md
@@ -1,28 +1,16 @@
-# Conformer: Local Features Coupling Global Representations for Visual Recognition
-
+# Conformer
+
+> [Conformer: Local Features Coupling Global Representations for Visual Recognition](https://arxiv.org/abs/2105.03889)
## Abstract
-
Within Convolutional Neural Network (CNN), the convolution operations are good at extracting local features but experience difficulty to capture global representations. Within visual transformer, the cascaded self-attention modules can capture long-distance feature dependencies but unfortunately deteriorate local feature details. In this paper, we propose a hybrid network structure, termed Conformer, to take advantage of convolutional operations and self-attention mechanisms for enhanced representation learning. Conformer roots in the Feature Coupling Unit (FCU), which fuses local features and global representations under different resolutions in an interactive fashion. Conformer adopts a concurrent structure so that local features and global representations are retained to the maximum extent. Experiments show that Conformer, under the comparable parameter complexity, outperforms the visual transformer (DeiT-B) by 2.3% on ImageNet. On MSCOCO, it outperforms ResNet-101 by 3.7% and 3.6% mAPs for object detection and instance segmentation, respectively, demonstrating the great potential to be a general backbone network.
-
-## Citation
-
-```latex
-@article{peng2021conformer,
- title={Conformer: Local Features Coupling Global Representations for Visual Recognition},
- author={Zhiliang Peng and Wei Huang and Shanzhi Gu and Lingxi Xie and Yaowei Wang and Jianbin Jiao and Qixiang Ye},
- journal={arXiv preprint arXiv:2105.03889},
- year={2021},
-}
-```
-
## Results and models
### ImageNet-1k
@@ -35,3 +23,14 @@ Within Convolutional Neural Network (CNN), the convolution operations are good a
| Conformer-base-p16\* | 83.29 | 22.89 | 83.82 | 96.59 | [config](https://github.com/open-mmlab/mmclassification/blob/master/configs/conformer/conformer-base-p16_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/conformer/conformer-base-p16_3rdparty_8xb128_in1k_20211206-bfdf8637.pth) |
*Models with \* are converted from the [official repo](https://github.com/pengzhiliang/Conformer). The config files of these models are only for validation. We don't ensure these config files' training accuracy and welcome you to contribute your reproduction results.*
+
+## Citation
+
+```
+@article{peng2021conformer,
+ title={Conformer: Local Features Coupling Global Representations for Visual Recognition},
+ author={Zhiliang Peng and Wei Huang and Shanzhi Gu and Lingxi Xie and Yaowei Wang and Jianbin Jiao and Qixiang Ye},
+ journal={arXiv preprint arXiv:2105.03889},
+ year={2021},
+}
+```
diff --git a/configs/conformer/metafile.yml b/configs/conformer/metafile.yml
index 31d28740756..4efe05fb8fd 100644
--- a/configs/conformer/metafile.yml
+++ b/configs/conformer/metafile.yml
@@ -10,9 +10,9 @@ Collections:
URL: https://arxiv.org/abs/2105.03889
Title: "Conformer: Local Features Coupling Global Representations for Visual Recognition"
README: configs/conformer/README.md
-# Code:
-# URL: # todo
-# Version: # todo
+ Code:
+ URL: https://github.com/open-mmlab/mmclassification/blob/v0.19.0/mmcls/models/backbones/conformer.py
+ Version: v0.19.0
Models:
- Name: conformer-tiny-p16_3rdparty_8xb128_in1k
diff --git a/configs/convnext/README.md b/configs/convnext/README.md
new file mode 100644
index 00000000000..fee44db57cd
--- /dev/null
+++ b/configs/convnext/README.md
@@ -0,0 +1,53 @@
+# ConvNeXt
+
+> [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545v1)
+
+
+## Abstract
+
+
+The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
+
+
+
+
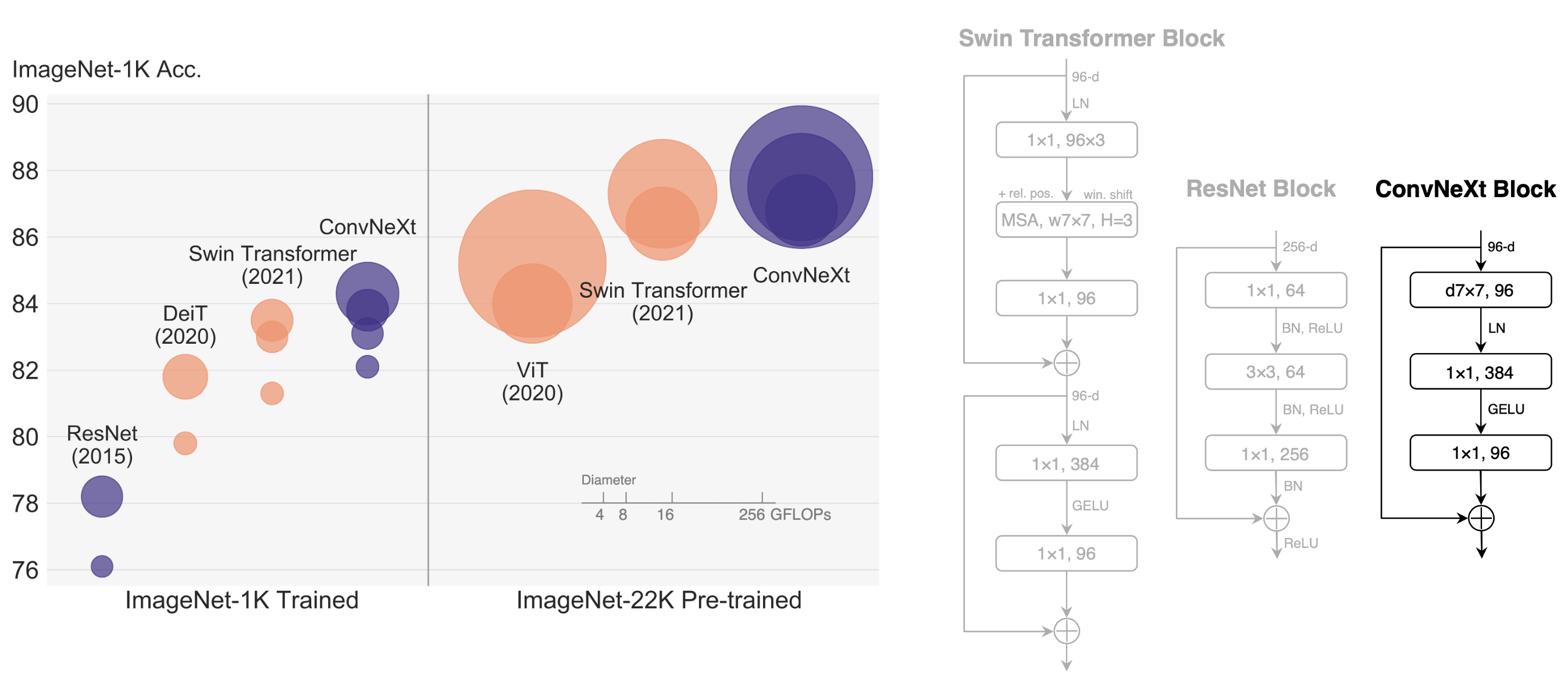
+
+

+
+

+
+
+