Vulkan support #614
Comments
|
Hi @danilw do you know what could be causing this ? |

|
you not first who report this problem in the AMD GPU, and sadly I have no idea what causes it I tested this code on AMG Vega8 and it works perfectly fine there as you can see on the screenshot as I write on code page:
sorry if you want to fix it then do it yourself, I can not fix it (it may be driver bug, but I don't know, maybe its my code bug) |
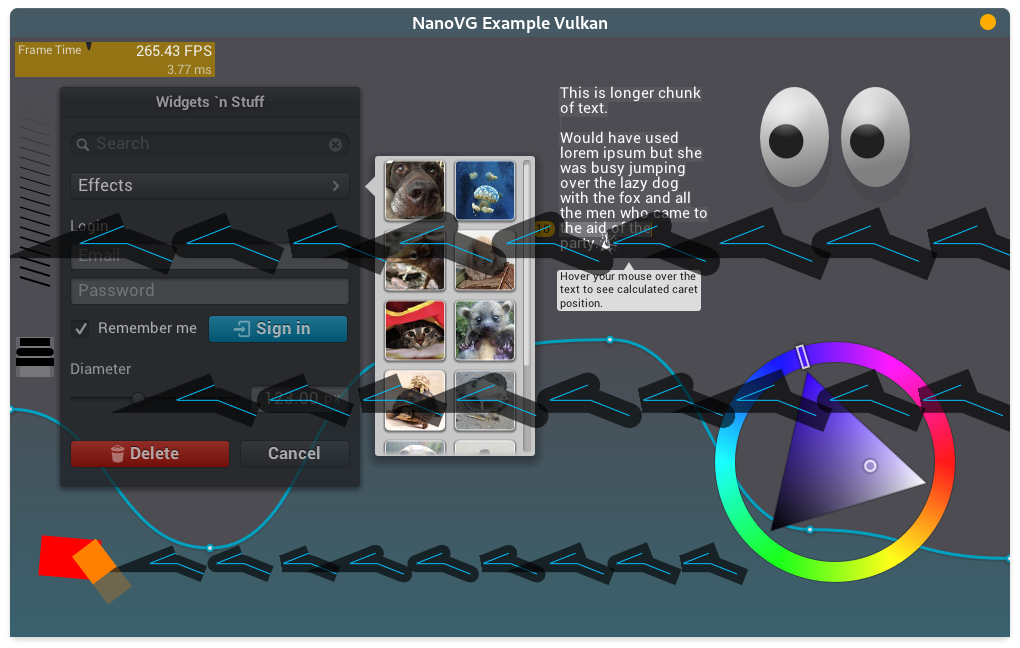
|
ok thanks for answering |
|
Hi @danilw |
|
@leranger thank you I added this as a fix |
|
@danilw I built your nanovg demo project with -DCMAKE_BUILD_TYPE=Release which produces I noticed that the Vulkan demo runs with 1200 FPS where as the OpenGL demo runs with 2000 FPS. Now that's a bigger difference than I expected, and in the wrong direction. But may this is to be expected ? I have no experience with Vulkan. Something else I noticed is, that resizing of the OpenGL window is smooth with hardly any FPS drop. But the Vulkan window redraw gets really choppy. |
Yes this is "problem" of this Vulkan port, and I have no idea where to look and how to fix it (I sure it can be fixed), yes there is something "wrong" this is for sure. My result on screenshot: in OpenGL it shows 62% GPU Utilization and 800fps, when in Vulkan 360fps and 42% GPU Utilization. My screen has 60 refresh rate. Maybe this is "fine" for real case usage because for real case FPS capped to refresh rate, and GPU usage almost same on my 60FPS refresh rate for Vk and Ogl this demo apps. I have no "solution" for this, I can say - you can make own "port" where it work better than in this Vulkan port, I do not need to rewrite it (I have not any real usage of this Vulkan port) so I keep it as it is for now.
Resize in Vulkan is "hard to make it look good" basically to have correct resize without "any flashes and smooth performance" you have to make own swapchain implementation (to avoid annoying flashes on resize in native Vulkan swapchain implementation), and render everything in framebuffer with multithreading for everything and recreate framebuffers on resize also in multithreading using old framebuffer while slowly (using multiple frames to compensate lag and slow memory allocation on GPU) recreating new for resize. This is way too large task for this "demo", and "correct resize" should be implemented in "your application", when this nanovg-vulkan implementation should be used just as "library to render UI" sharing vulkan device and just render on top of your "framebuffer" something like this. |

|
I sampled both demos using "hotspot" and it didn't make much sense to me in terms of what might be the slowdown. One idea I had is, that maybe Vulkan is going through Wayland and that slows it down, whereas OpenGL seems to run on X11. I don't know how to verify this though.
The resize flashes I can also observe in OpenGL programs, where the redraw exceeds the frame time. It's something I am trying to solve in a way similiar or identical to what you wrote. Your port is very interesting to me, because I don't know about the longevity of OpenGL. Having Vulkan as a backend is very nice for me. |
in this demo app Vulkan surface depends on GLFW3 setting that you set on building this app. This demo app does not control surface creation. (as I say this app use basic Vulkan surface because GLFW3 make it)
this depends on GPU and GPU driver when everything default used. I think you use Nvidia because OpenGL and Vulkan flashes only on Nvidia in Linux, in Windows it does not. AMD Mesa driver does not flash swapchain on resize. (I did not test this demo-app behavior, but others apps I saw work like this) |
I think (can be wrong) it happens because of one of these cases:
@mulle-nat for better "real time communication" if you have more questions better join discord (link in description on my github page with nanovg port) |
|
I have no further questions :) Thanks for all the tips. |
|
The stencil strokes are bugged on the vulkan fork. Here is a fix nidefawl@67f3a25 |
|
@nidefawl can you make it as pull request to my fork so il add it, if you want ofc. |
|
@mulle-nat about "low Vulkan FPS" - I added 3 more examples, and one of examples use multiple frames in flight. Look at this example nanovg-vulkan-glfw-integration-demo In this example FPS with 1 frame in flight ~200, with 2 frames in flight ~600 (look screenshot in description of example). (I am not going to do any logic change for now, maybe latter if there will be some requests/interest to this library/port, for now I just added more examples) Screenshot of OpenGL and Vulkan at same time: Two OpenGL at same time (~500 fps) - image 2 OpenGL Two Vulkan at same time (~300 fps) - image 2 Vulkan |

|
@danilw Nice work. |
May be a dud, but I suspect the memory of all three buffers ( fillVertShader, fillFragShader, fillFragShaderAA ) being on HOST could be a reason for the relatively poor performance. Looking at both CPU and GPU utilization, there is a bottleneck somewhere, and it may be Memory/PCIE bandwidth. For reference: https://www.youtube.com/watch?v=bUUZ1iD9_e4 |
@SubiyaCryolite I thought I mention it somewhere here, but look like I have not: Better optimization - somehow "update only part of pipeline that related to changed state element" - but it seems way too complex for me to do, or I have no idea how to do it simple.
il check it now, thanks
great video xD |
Yes, Vulkan is incredibly complex XD. Truth be told your work is a great foundation. I've made my own fork and I'm currently focused on getting performance to exceed GL. It might not be possible XD, but so far I'm enjoying the challenge. I may or may not initiate a PR in a few days time but so far I've don't the following. 1: Change mapping to coherent 2: Added support for more than One or more Command Buffers 3: Migrating from UNIFORM_BUFFER to STORAGE_BUFFER This may all be pointless in the end, but it's worth a shot XD. Thank's again for all the work you've done thus far. |
I did small investigation of PCIE usage by this nanovg vulkan-port:
I see nanovg_vk.h#L1517 And base on this logic - PCIE usage must be "bottleneck" so it always must be very high especially when FPS drop low. Look more detailed - PCIE usage in nanovg_vulkanBelow on this page is short version. Vulkan test:I use Vulkan example with single frame in flight, this why FPS is low in Vulkan.For example - you can press hotkey Space: So this mean - right example must show some crazy high PCIE usage: Result:
Comparing to OpenGL PCIE usage:
There still possibility that my tools to measure performance are broken or my method is incorrect. I can not use those modern-Nvidia tools to debug - because my Nvidia GPU is way too old, so it is not supported by those tools, but this Nvidia GPU still support Vulkan. |



{kind=link}
{kind=link}
Better you do PR request when its ready, so I can/will give you proper "thanks" and you will be listed in contributors in Github source code pages.
Do not rush, any time when/if it will be ready.
Your changes look "very needed" to improve this project, will be nice if it also improve performance. |
when I was making "multiple frames in flight" example - it becomes obvious that "rebuilding every single triangle on CPU every frame" - take alot of time, this why FPS drop so much compare to OpenGL. With "multiple frames in flight" - CPU build triangles and render-pass in parallel while GPU render, so fps almost double from original. This is only optimization I did in this project, everything else done by other people. P.S. I see nanovg_vulkan bottleneck in CPU-side, maybe its some "bad-cache-pattern" maybe it related to building vulkan pipeline, maybe some PCIE timing synchronization pattern broke because Vulkan does upload data to GPU when "you allocate it" not like OpenGL can do some "magic" optimizations so maybe too many "small allocations and PCIE timer is slow", or some more complex stuff. Ofc I can be completely wrong, better do your tests |
|
I archived my https://github.com/danilw/nanovg_vulkan Im not goting to close this Issue-thread, since this my nanovg_vulkan is still "only" working nanovg Vulkan port on github. so someone may need it. |
|
I don't need it at the moment, but I appreciate that it exists. 👍 |
|
@SubiyaCryolite il add link to your repo https://github.com/SubiyaCryolite/nanovg_vulkan in my "archived"(il unarchive and edit). But do not feel obligated to do anything on that project, do whatever or nothing - no one care its "free job/code". Im will add link to your repo - just because you may update something - to point to one active fork. Edit - link added, if you dont want it then say il remove. |
Thank you so much @danilw , I really appreciate it. I've been able to make several tweaks based on your initial work. Thanks for laying a good foundation. |
If someone looks for a working Vulkan port of this nanovg lib
src https://github.com/danilw/nanovg_vulkan
The text was updated successfully, but these errors were encountered: