| title | shortTitle | category | tag | description | author | head | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
详解Java NIO的Buffer缓冲区和Channel通道 |
Buffer和Channel |
|
|
Java NIO 中的 Buffer 和 Channel 是 NIO 系统的核心组件。Buffer 负责存储数据,提供了对数据的读写操作。Channel 代表了与 I/O 设备(如文件或套接字)之间的连接。它提供了从源设备到 Buffer 的数据读取能力和从 Buffer 到目标设备的数据写入能力。 |
沉默王二 |
|
首先我们再来回顾一下 IO 和 NIO 的区别:
- 可简单认为:IO 是面向流的处理,NIO 是面向块(缓冲区)的处理
- 面向流的 I/O 系统一次一个字节地处理数据。
- 一个面向块(缓冲区)的 I/O 系统以块的形式处理数据。
NIO 主要有两个核心部分组成:
- Buffer 缓冲区
- Channel 通道
在 NIO 中,并不是以流的方式来处理数据的,而是以 buffer 缓冲区和 Channel 通道配合使用来处理数据的。
简单理解一下:
可以把 Channel 通道比作铁路,buffer 缓冲区比作成火车(运载着货物)
而我们的 NIO 就是通过 Channel 通道运输着存储数据的 Buffer 缓冲区的来实现数据的处理!
要时刻记住:Channel 不与数据打交道,它只负责运输数据。与数据打交道的是 Buffer 缓冲区
- Channel-->运输
- Buffer-->数据
相对于传统 IO 而言,流是单向的。对于 NIO 而言,有了 Channel 通道这个概念,我们的读写都是双向的(铁路上的火车能从广州去北京、自然就能从北京返还到广州)!
我们来看看 Buffer 缓冲区有什么值得我们注意的地方。
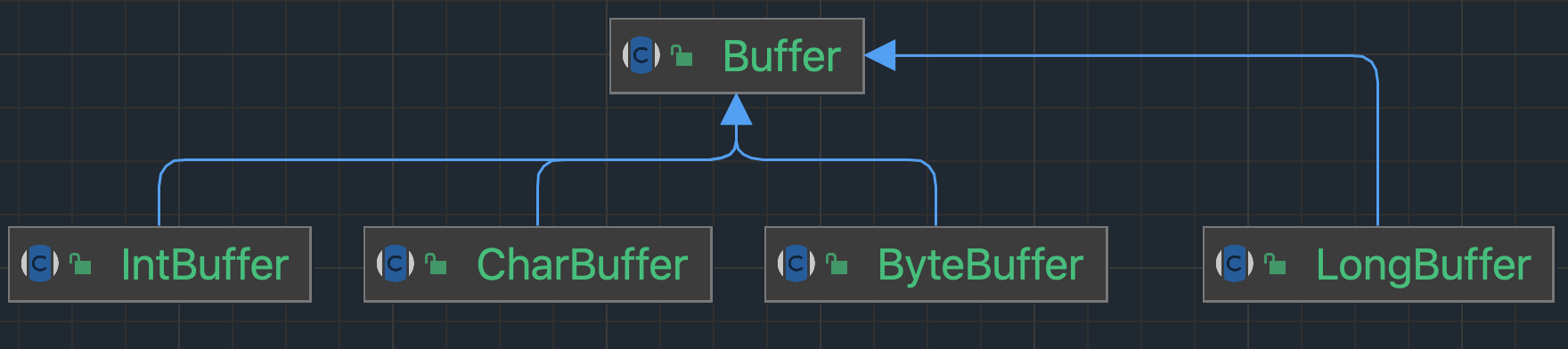
Buffer 是缓冲区的抽象类:

其中 ByteBuffer 是用得最多的实现类(在通道中读写字节数据)。
拿到一个缓冲区我们往往会做什么?很简单,就是读取缓冲区的数据/写数据到缓冲区中。所以,缓冲区的核心方法就是 put 和 get:

Buffer 类维护了 4 个核心变量来提供关于其所包含的数组信息。它们是:
- 容量 Capacity 缓冲区能够容纳的数据元素的最大数量。容量在缓冲区创建时被设定,并且永远不能被改变。(不能被改变的原因也很简单,底层是数组嘛)
- 上界 Limit 缓冲区里的数据的总数,代表了当前缓冲区中一共有多少数据。
- 位置 Position 下一个要被读或写的元素的位置。Position 会自动由相应的
get()和put()函数更新。 - 标记 Mark 一个备忘位置。用于记录上一次读写的位置。
首先展示一下是如何创建缓冲区的,核心变量的值是怎么变化的。
// 创建一个缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// 看一下初始时4个核心变量的值
System.out.println("初始时-->limit--->"+byteBuffer.limit());
System.out.println("初始时-->position--->"+byteBuffer.position());
System.out.println("初始时-->capacity--->"+byteBuffer.capacity());
System.out.println("初始时-->mark--->" + byteBuffer.mark());
System.out.println("--------------------------------------");
// 添加一些数据到缓冲区中
String s = "沉默王二";
byteBuffer.put(s.getBytes());
// 看一下初始时4个核心变量的值
System.out.println("put完之后-->limit--->"+byteBuffer.limit());
System.out.println("put完之后-->position--->"+byteBuffer.position());
System.out.println("put完之后-->capacity--->"+byteBuffer.capacity());
System.out.println("put完之后-->mark--->" + byteBuffer.mark());运行结果:
初始时-->limit--->1024
初始时-->position--->0
初始时-->capacity--->1024
初始时-->mark--->java.nio.HeapByteBuffer[pos=0 lim=1024 cap=1024]
--------------------------------------
put完之后-->limit--->1024
put完之后-->position--->12
put完之后-->capacity--->1024
put完之后-->mark--->java.nio.HeapByteBuffer[pos=12 lim=1024 cap=1024]
现在我想要从缓存区拿数据,怎么拿呀??NIO 给了我们一个flip()方法。这个方法可以改动 position 和 limit 的位置!
在之前代码的基础上,我们flip()一下。
// flip()方法
byteBuffer.flip();
System.out.println("flip()方法之后-->limit--->"+byteBuffer.limit());
System.out.println("flip()方法之后-->position--->"+byteBuffer.position());
System.out.println("flip()方法之后-->capacity--->"+byteBuffer.capacity());
System.out.println("flip()方法之后-->mark--->" + byteBuffer.mark());再看看 4 个核心属性的值会发生什么变化:

在调用 flip() 之后,limit 变为当前 position 的值(12),position 重置为 0。这意味着你可以从缓冲区的开始位置读取刚刚写入的数据,直到 limit 指定的位置。capacity 保持不变(1024)。
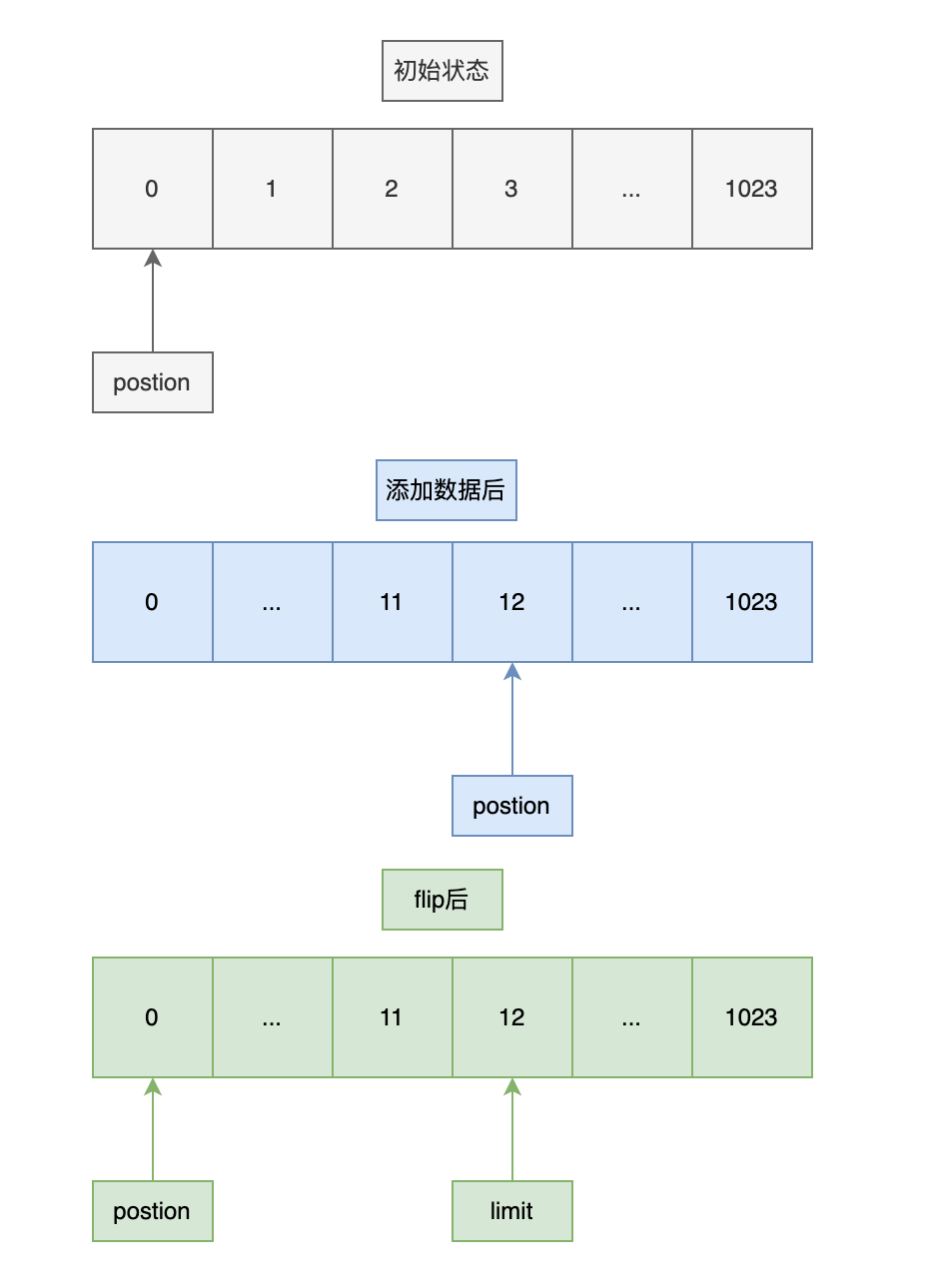
假设我们有一个初始容量为 1024 的 ByteBuffer。
初始状态:
position = 0
limit = 1024
capacity = 1024
添加数据 "沉默王二" 后:
由于 "沉默王二" 为 UTF-8 编码,一个汉字占 3 个字节,共有 4 个汉字,所以占用 12 个字节。
position = 12
limit = 1024
capacity = 1024
调用 flip() 方法后:
position = 0
limit = 12
capacity = 1024
用一幅图来表示就是。
当切换成读模式之后,我们就可以读取缓冲区的数据了:
// 创建一个limit()大小的字节数组(因为就只有limit这么多个数据可读)
byte[] bytes = new byte[byteBuffer.limit()];
// 将读取的数据装进我们的字节数组中
byteBuffer.get(bytes);
// 输出数据
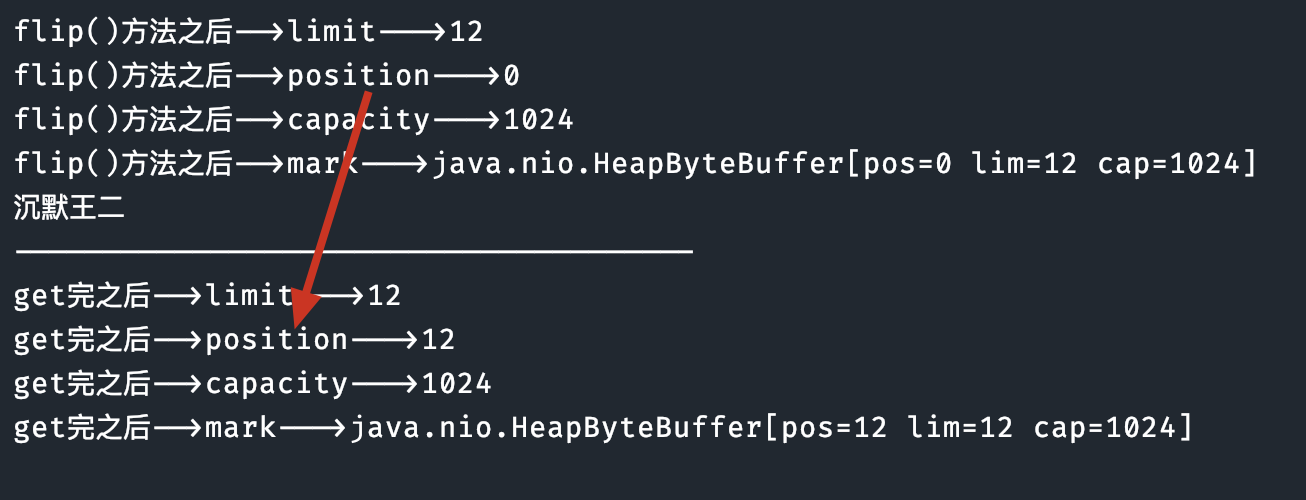
System.out.println(new String(bytes, 0, bytes.length));输出后的结果:
沉默王二
随后输出一下核心变量的值看看:
读完如何还想写数据到缓冲区,那就使用clear() 方法,这个方法会“清空”缓冲区,数据没有真正被清空,只是被遗忘掉了

Channel 通道只负责传输数据、不直接操作数据。操作数据都是通过 Buffer 缓冲区来进行操作!通常,通道可以分为两大类:文件通道和套接字通道。
FileChannel:用于文件 I/O 的通道,支持文件的读、写和追加操作。FileChannel 允许在文件的任意位置进行数据传输,支持文件锁定以及内存映射文件等高级功能。FileChannel 无法设置为非阻塞模式,因此它只适用于阻塞式文件操作。
SocketChannel:用于 TCP 套接字 I/O 的通道。SocketChannel 支持非阻塞模式,可以与 Selector(下文会讲)一起使用,实现高效的网络通信。SocketChannel 允许连接到远程主机,进行数据传输。
与之匹配的有ServerSocketChannel:用于监听 TCP 套接字连接的通道。与 SocketChannel 类似,ServerSocketChannel 也支持非阻塞模式,并可以与 Selector 一起使用。ServerSocketChannel 负责监听新的连接请求,接收到连接请求后,可以创建一个新的 SocketChannel 以处理数据传输。
DatagramChannel:用于 UDP 套接字 I/O 的通道。DatagramChannel 支持非阻塞模式,可以发送和接收数据报包,适用于无连接的、不可靠的网络通信。
这篇我们主要来讲 FileChannel,SocketChannel、ServerSocketChannel 和 DatagramChannel 会放到后面的章节中讲解。
可以通过下面的方式打开一个通道。
FileChannel.open(Paths.get("docs/配套教程.md"), StandardOpenOption.WRITE);这里我们用到了 Paths,这个后面也会讲到。
①、使用FileChannel 配合 ByteBuffer 缓冲区实现文件复制的功能:
try (FileChannel sourceChannel = FileChannel.open(Paths.get("logs/javabetter/itwanger.txt"), StandardOpenOption.READ);
FileChannel destinationChannel = FileChannel.open(Paths.get("logs/javabetter/itwanger1.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE)) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (sourceChannel.read(buffer) != -1) {
buffer.flip();
destinationChannel.write(buffer);
buffer.clear();
}
}我们创建一个容量为 1024 的 ByteBuffer 作为缓冲区。在循环中,我们从源文件的 FileChannel 读取数据到缓冲区。当 read() 方法返回 -1 时,表示已经到达文件末尾。
读取数据后,我们调用 flip() 方法,以便在缓冲区中准备好要写入的数据。然后,我们将缓冲区的内容写入目标文件的 FileChannel(write() 方法)。在写入完成后,我们调用 clear() 方法重置缓冲区,以便在下一次迭代中重用它。
②、使用内存映射文件(MappedByteBuffer)的方式实现文件复制的功能(直接操作缓冲区):
try (FileChannel sourceChannel = FileChannel.open(Paths.get("logs/javabetter/itwanger.txt"), StandardOpenOption.READ);
FileChannel destinationChannel = FileChannel.open(Paths.get("logs/javabetter/itwanger2.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.READ)) {
long fileSize = sourceChannel.size();
MappedByteBuffer sourceMappedBuffer = sourceChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileSize);
MappedByteBuffer destinationMappedBuffer = destinationChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileSize);
for (int i = 0; i < fileSize; i++) {
byte b = sourceMappedBuffer.get(i);
destinationMappedBuffer.put(i, b);
}
}MappedByteBuffer 是 Java NIO 中的一个类,它继承自 java.nio.ByteBuffer。MappedByteBuffer 用于表示一个内存映射文件,即将文件的一部分或全部映射到内存中,以便通过直接操作内存来实现对文件的读写。这种方式可以提高文件 I/O 的性能,因为操作系统可以直接在内存和磁盘之间传输数据,无需通过 Java 应用程序进行额外的数据拷贝。
通常与 FileChannel 一起使用,可以通过调用 FileChannel 的 map() 方法创建 MappedByteBuffer 对象。map() 方法接受三个参数:映射模式(FileChannel.MapMode)映射起始位置和映射的长度。
映射模式包括只读模式(READ_ONLY)、读写模式(READ_WRITE)和专用模式(PRIVATE)。
我们设置源文件的 MappedByteBuffer 为只读模式(READ_ONLY),目标文件的 MappedByteBuffer 为读写模式(READ_WRITE)。
在循环中,我们逐字节地从源文件的 MappedByteBuffer 读取数据并将其写入目标文件的 MappedByteBuffer。这样就实现了文件复制功能。利用内存映射文件(MappedByteBuffer)实现的文件复制,可能会比使用 ByteBuffer 的方法更快。
需要注意的是,使用 MappedByteBuffer 进行文件操作时,数据的修改可能不会立即写入磁盘。可以通过调用 MappedByteBuffer 的 force() 方法将数据立即写回磁盘。
③、通道之间通过transfer()实现数据的传输(直接操作缓冲区):
try (FileChannel sourceChannel = FileChannel.open(Paths.get("logs/javabetter/itwanger.txt"), StandardOpenOption.READ);
FileChannel destinationChannel = FileChannel.open(Paths.get("logs/javabetter/itwanger3.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.READ)) {
sourceChannel.transferTo(0, sourceChannel.size(), destinationChannel);
} catch (IOException e) {
throw new RuntimeException(e);
}FileChannel 的 transferTo() 方法是一个高效的文件传输方法,它允许将文件的一部分或全部内容直接从源文件通道传输到目标通道(通常是另一个文件通道或网络通道)。这种传输方式可以避免将文件数据在用户空间和内核空间之间进行多次拷贝,提高了文件传输的性能。
transferTo() 方法接受以下三个参数:
- position:源文件中开始传输的位置。
- count:要传输的字节数。
- target:接收数据的目标通道。
需要注意的是,transferTo() 方法可能无法一次传输所有请求的字节。在实际应用中,你可能需要使用循环来确保所有字节都被传输。
public class FileChannelTransferToLoopExampleWithPaths {
public static void main(String[] args) {
Path sourcePath = Paths.get("logs/itwanger/paicoding.txt");
Path destinationPath = Paths.get("logs/itwanger/paicoding_copy.txt");
// 使用 try-with-resources 语句确保通道资源被正确关闭
try (FileChannel sourceChannel = FileChannel.open(sourcePath, StandardOpenOption.READ);
FileChannel destinationChannel = FileChannel.open(destinationPath, StandardOpenOption.CREATE, StandardOpenOption.WRITE)) {
long position = 0;
long count = sourceChannel.size();
// 循环传输,直到所有字节都被传输
while (position < count) {
long transferred = sourceChannel.transferTo(position, count - position, destinationChannel);
position += transferred;
}
} catch (IOException e) {
e.printStackTrace();
}
}
}此外,transferTo() 方法在底层使用了操作系统提供的零拷贝功能(如 Linux 的 sendfile() 系统调用),可以大幅提高文件传输性能。但是,不同操作系统和 JVM 实现可能会影响零拷贝的可用性和性能,因此实际性能可能因环境而异。
零拷贝(Zero-Copy)是一种优化数据传输性能的技术,它最大限度地减少了在数据传输过程中的 CPU 和内存开销。在传统的数据传输过程中,数据通常需要在用户空间和内核空间之间进行多次拷贝,这会导致额外的 CPU 和内存开销。零拷贝技术通过避免这些多余的拷贝操作,实现了更高效的数据传输。
在 Java 中,零拷贝技术主要应用于文件和网络 I/O。FileChannel 类的 transferTo() 和 transferFrom() 方法就利用了零拷贝技术,可以在文件和网络通道之间高效地传输数据。详细参考:深入剖析Linux IO原理和几种零拷贝机制的实现
直接缓冲区和非直接缓冲区的差别主要在于它们在内存中的存储方式。这里给出了直接缓冲区和非直接缓冲区的简要概述和区别:
非直接缓冲区:
- 分配在 JVM 堆内存中
- 受到垃圾回收的管理
- 在读写操作时,需要将数据从堆内存复制到操作系统的本地内存,再进行 I/O 操作
- 创建:
ByteBuffer.allocate(int capacity)
直接缓冲区:
- 分配在操作系统的本地内存中
- 不受垃圾回收的管理
- 在读写操作时,直接在本地内存中进行,避免了数据复制,提高了性能
- 创建:
ByteBuffer.allocateDirect(int capacity) - 还有前面提到的
FileChannel.map()方法,会返回一个类型为 MappedByteBuffer 的直接缓冲区。
ByteBuffer.allocate和ByteBuffer.allocateDirect直接的差异。

直接缓冲区和非直接缓冲区之间的差异。
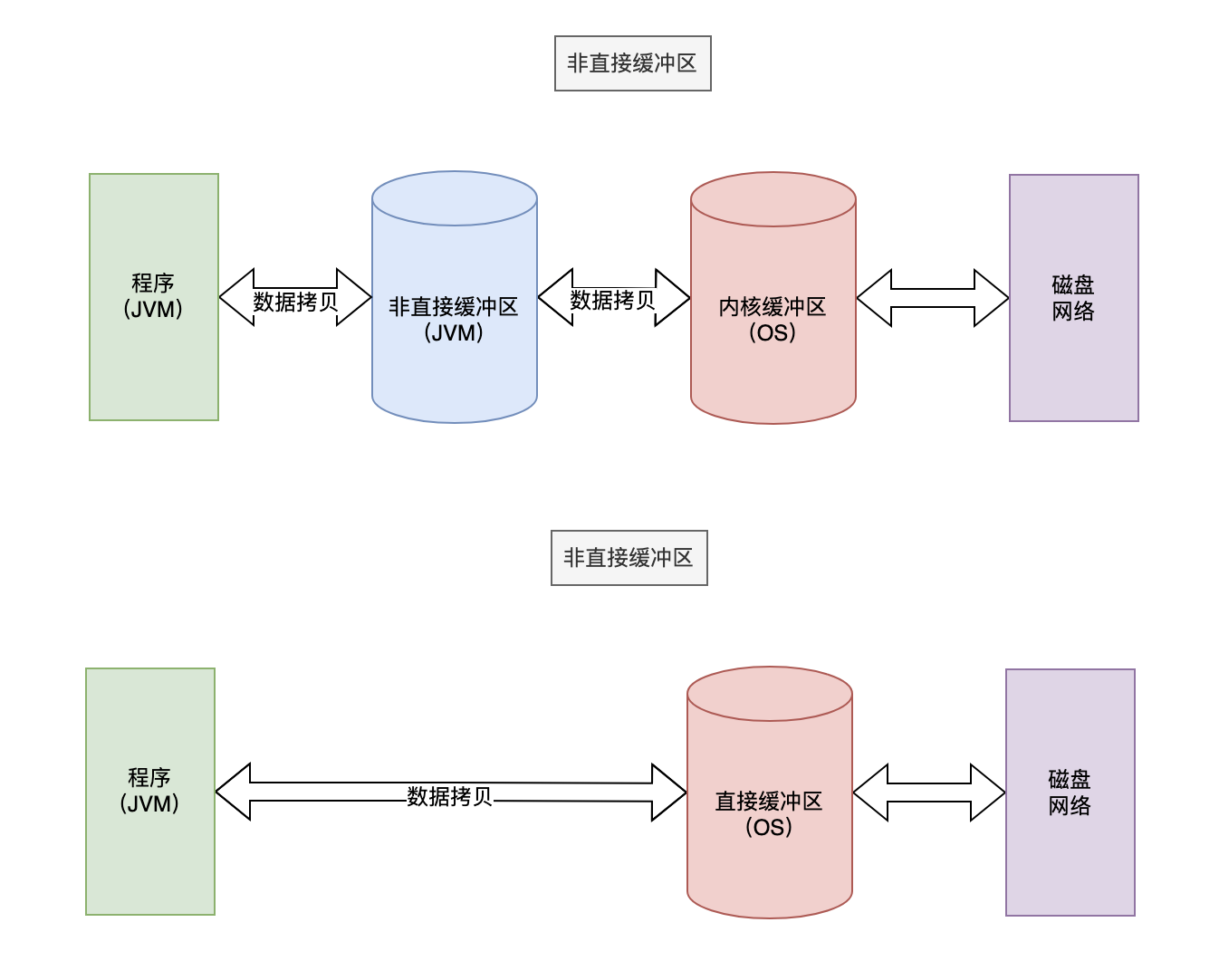
非直接缓冲区存储在JVM内部,数据需要从应用程序(Java)复制到非直接缓冲区,再复制到内核缓冲区,最后发送到设备(磁盘/网络)。而对于直接缓冲区,数据可以直接从应用程序(Java)复制到内核缓冲区,无需经过JVM的非直接缓冲区。
AsynchronousFileChannel 是 Java 7 引入的一个异步文件通道类,提供了对文件的异步读、写、打开和关闭等操作。
可以通过 AsynchronousFileChannel.open() 方法打开一个异步文件通道,该方法接受一个 Path 对象和一组打开选项(如 StandardOpenOption.READ、StandardOpenOption.WRITE 等)作为参数。
Path file = Paths.get("example.txt");
AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(file, StandardOpenOption.READ, StandardOpenOption.WRITE);AsynchronousFileChannel 提供了两种异步操作的方式:
①、Future 方式:使用 Future 对象来跟踪异步操作的完成情况。当我们调用一个异步操作(如 read() 或 write())时,它会立即返回一个 Future 对象。可以使用这个对象来检查操作是否完成,以及获取操作的结果。这种方式适用于不需要在操作完成时立即执行其他操作的场景。
举个例子:
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
Future<Integer> result = fileChannel.read(buffer, position);
while (!result.isDone()) {
// 执行其他操作
}
int bytesRead = result.get();
System.out.println("Bytes read: " + bytesRead);②、CompletionHandler 方式,使用一个实现了 CompletionHandler 接口的对象来处理异步操作的完成。我们需要提供一个 CompletionHandler 实现类,重写 completed() 和 failed() 方法,分别处理操作成功和操作失败的情况。当异步操作完成时,系统会自动调用相应的方法。这种方式适用于需要在操作完成时立即执行其他操作的场景。
举个例子:
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
fileChannel.read(buffer, position, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
System.out.println("Bytes read: " + result);
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
System.err.println("Read failed");
exc.printStackTrace();
}
});来看完整的示例,采用 Future 的形式。
Path path = Paths.get("docs/配套教程.md");
try (AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(path, StandardOpenOption.READ)) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
long position = 0;
while (true) {
Future<Integer> result = fileChannel.read(buffer, position);
while (!result.isDone()) {
// 在这里可以执行其他任务,例如处理其他 I/O 操作
}
int bytesRead = result.get();
if (bytesRead <= 0) {
break;
}
position += bytesRead;
buffer.flip();
byte[] data = new byte[buffer.limit()];
buffer.get(data);
System.out.println(new String(data));
buffer.clear();
}
}在这个示例中,我们使用 AsynchronousFileChannel.read() 方法发起异步读取操作。这个方法会返回一个 Future<Integer> 对象,表示读取操作的结果。我们可以通过调用 isDone() 方法来检查异步操作是否完成。完成后,我们可以通过调用 get() 方法获取实际读取的字节数。
然后我们来看 CompletionHandler 接口的形式:
public static void readAllBytes(Path path) throws IOException, InterruptedException {
AsynchronousFileChannel fileChannel = AsynchronousFileChannel.open(path, StandardOpenOption.READ);
ByteBuffer buffer = ByteBuffer.allocate(1024);
AtomicLong position = new AtomicLong(0);
CountDownLatch latch = new CountDownLatch(1);
fileChannel.read(buffer, position.get(), null, new CompletionHandler<Integer, Object>() {
@Override
public void completed(Integer bytesRead, Object attachment) {
if (bytesRead > 0) {
position.addAndGet(bytesRead);
buffer.flip();
byte[] data = new byte[buffer.limit()];
buffer.get(data);
System.out.print(new String(data));
buffer.clear();
fileChannel.read(buffer, position.get(), attachment, this);
} else {
latch.countDown();
try {
fileChannel.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void failed(Throwable exc, Object attachment) {
System.out.println("Error: " + exc.getMessage());
latch.countDown();
}
});
latch.await();
}1、在 readAllBytes 方法中,我们使用 AsynchronousFileChannel.open() 方法以读取模式打开异步文件通道。
2、创建一个大小为 1024 的 ByteBuffer 来存储从文件中读取的数据。
3、使用 AtomicLong 类型的 position 变量来记录当前读取的文件位置。初始值为 0。
4、创建一个 CountDownLatch 对象,用于在异步操作完成时通知主线程。初始值为 1。
5、使用 fileChannel.read() 方法启动异步读取操作。这个方法的参数包括:用于存储数据的缓冲区、当前读取位置、附加对象(在这个例子中不需要,所以传递 null)以及一个实现了 CompletionHandler 接口的对象,用于在读取操作完成时回调。
6、CompletionHandler 接口有两个方法:completed() 和 failed()。在读取操作成功完成时调用 completed() 方法;如果读取操作失败,调用 failed() 方法。
7、在 completed() 方法中,我们首先检查 bytesRead(本次读取的字节数)是否大于 0。如果大于 0,说明还有数据需要读取。
- 更新 position 变量,将其增加 bytesRead。
- 将缓冲区翻转(
flip()),以便我们可以从中读取数据。 - 创建一个新的字节数组,其大小等于缓冲区的限制(
limit())。 - 从缓冲区中获取数据并将其存储在新创建的字节数组中。
- 将字节数组转换为字符串并输出。
- 清除缓冲区,以便我们可以继续读取更多数据。
- 再次调用 fileChannel.read() 方法,以继续从文件中读取数据。
8、如果 bytesRead 等于或小于 0,说明我们已经读取完文件中的所有数据。此时,我们需要:调用 latch.countDown() 方法,以通知主线程异步操作已完成。关闭 fileChannel。
9、如果读取操作失败,我们将在 failed() 方法中输出错误信息并调用 latch.countDown() 方法通知主线程。
10、最后,我们调用 latch.await() 方法来等待异步操作完成。主线程将在此处阻塞,直到 latch 的计数变为 0。
Java NIO 中的 Buffer 和 Channel 是 NIO 系统的核心组件。Buffer 负责存储数据,提供了对数据的读写操作。它有多种类型,如 ByteBuffer、CharBuffer、IntBuffer 等,以支持不同的数据类型。
Channel 代表了与 I/O 设备(如文件或套接字)之间的连接。它提供了从源设备到 Buffer 的数据读取能力和从 Buffer 到目标设备的数据写入能力。Channel 可以是可读、可写或同时可读写的,我们详细介绍了文件通道 FileChannel 和异步文件通道 AsynchronousFileChannel。
总之,NIO 使用 Buffer 和 Channel 这两个组件来进行高效的数据传输,以提高 I/O 操作的性能。
参考链接:https://www.zhihu.com/question/29005375/answer/667616386,整理:沉默王二
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
