| title | shortTitle | category | tag | description | head | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
一次内存溢出的排查优化实战,彻底干掉臭名昭著的 OOM |
内存泄露排查优化实战 |
|
|
本文介绍了一次内存溢出的排查优化实战,彻底干掉臭名昭著的 OOM。 |
|
OutOfMemoryError,也就是臭名昭著的 OOM(内存溢出),相信很多球友都遇到过,相对于常见的业务异常,如数组越界、空指针等,OOM 问题更难难定位和解决。
这篇内容就以之前碰到的一次线上内存溢出的定位、解决问题的方式展开;希望能对碰到类似问题的球友带来思路和帮助。
主要从表现-->排查-->定位-->解决 四个步骤来分析和解决问题。
在 Java 中,和内存相关的问题主要有两种,内存溢出和内存泄漏。
- 内存溢出(Out Of Memory):就是申请内存时,JVM 没有足够的内存空间。通俗说法就是去蹲坑发现坑位满了。
- 内存泄露(Memory Leak):就是申请了内存,但是没有释放,导致内存空间浪费。通俗说法就是有人占着茅坑不拉屎。
在 JVM 的内存区域中,除了程序计数器,其他的内存区域都有可能发生内存溢出。
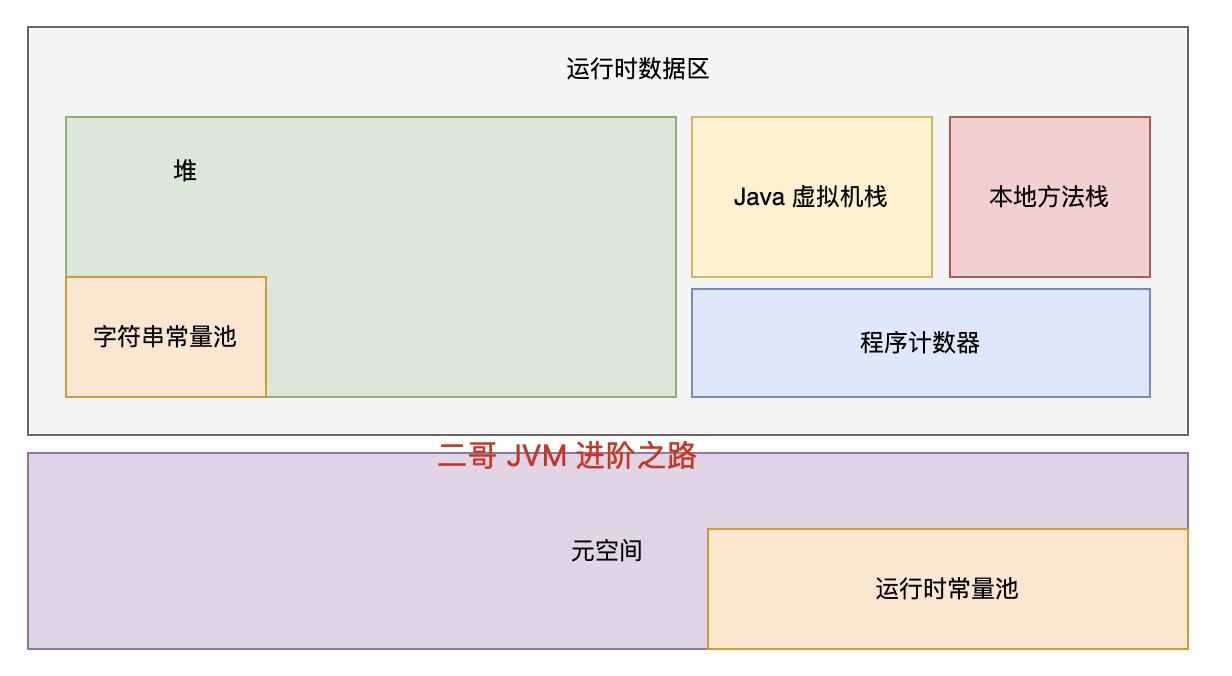
大家都知道,Java 堆中存储的都是对象,或者叫对象实例,那只要我们不断地创建对象,并且保证 GC Roots 到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么就一定会产生内存溢出。
比如说运行下面这段代码:
public class OOM {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
while (true) {
list.add(new Object());
}
}
}运行程序的时候记得设置一下 VM 参数:-Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError,限制堆内存大小为 20M,并且不允许扩展,并且当发生 OOM 时 dump 出当前内存的快照。
运行结果如下:
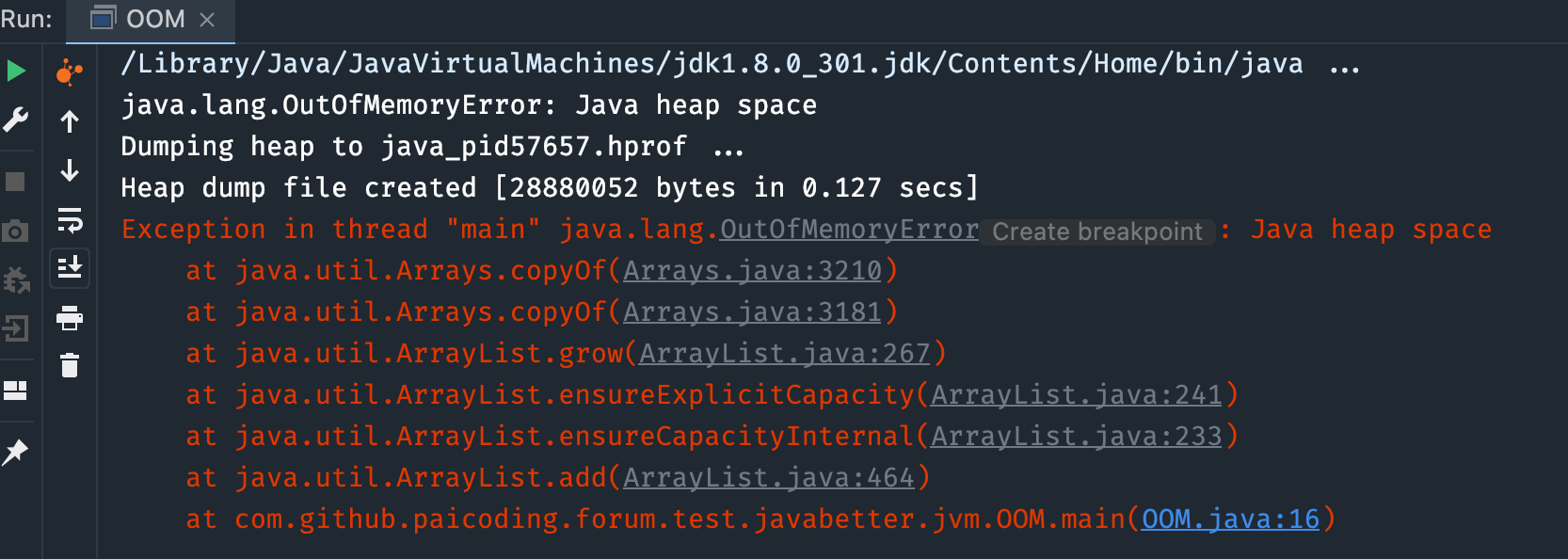
我们在讲运行时数据区的时候也曾讲过。
内存泄露是指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
简单来说,就是应该被垃圾回收的对象没有回收掉,导致占用的内存越来越多,最终导致内存溢出。
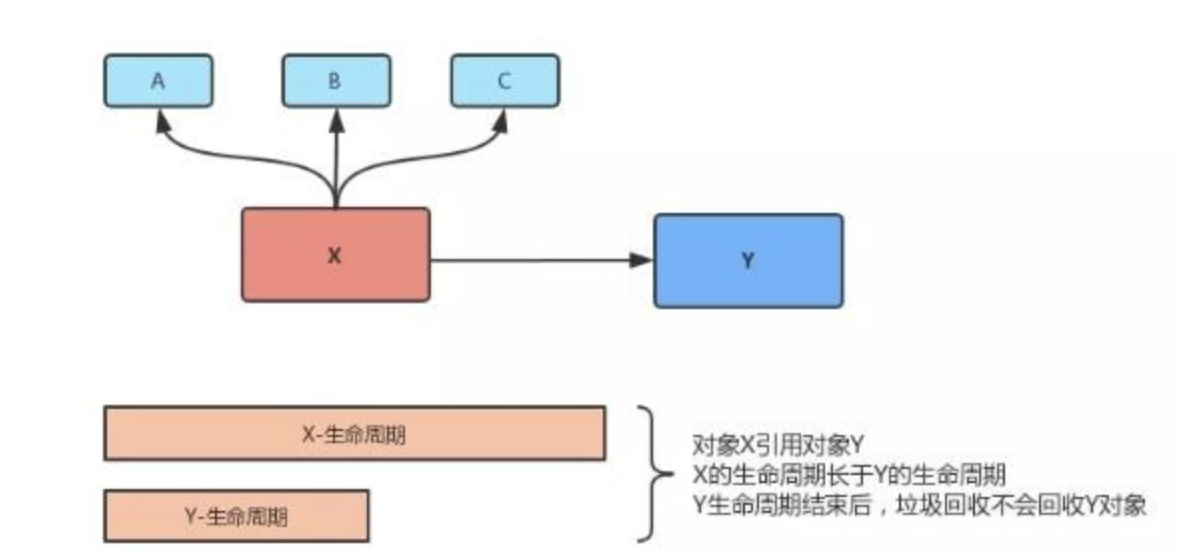
在上图中:对象 X 引用对象 Y,X 的生命周期比 Y 的生命周期长,Y 生命周期结束的时候,垃圾回收器不会回收对象 Y。
来看下面的例子:
public class MemoryLeak {
public static void main(String[] args) {
try{
Connection conn =null;
Class.forName("com.mysql.jdbc.Driver");
conn =DriverManager.getConnection("url","","");
Statement stmt =conn.createStatement();
ResultSet rs =stmt.executeQuery("....");
} catch(Exception e){//异常日志
} finally {
// 1.关闭结果集 Statement
// 2.关闭声明的对象 ResultSet
// 3.关闭连接 Connection
}
}
}创建的连接不再使用时,需要调用 close 方法关闭连接,只有连接被关闭后,GC 才会回收对应的对象(Connection,Statement,ResultSet,Session)。忘记关闭这些资源会导致持续占有内存,无法被 GC 回收。
这样就会导致内存泄露,最终导致内存溢出。
换句话说,内存泄露不是内存溢出,但会加快内存溢出的发生。
之前生产环境爆出的内存溢出问题会随着业务量的增长,出现的频次也越来越高。
应用程序的业务逻辑非常简单,就是从 Kafka 中将数据消费下来,然后批量的做持久化操作。
OOM 现象则是随着 Kafka 的消息越多,出现异常的频次就越快。由于当时还有其他工作所以只能让运维做重启,并且监控好堆内存以及 GC 情况。
不得不说,重启大法真的好,能解决大量的问题,但不是长久之计。
于是我们想根据运维之前收集到的内存数据、GC 日志尝试判断哪里出现了问题。
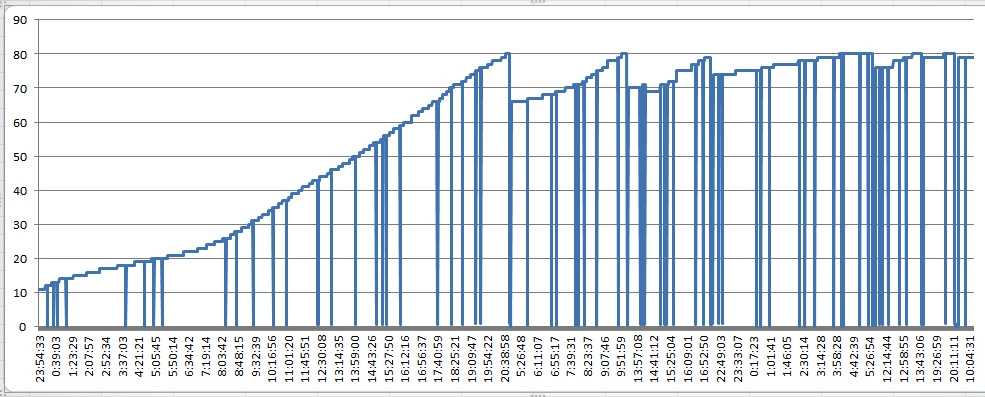
结果发现老年代的内存使用就算是发生 GC 也一直居高不下,而且随着时间推移也越来越高。
结合 jstat 的日志发现就算是发生了 FGC,老年代也回收不了,内存已经到顶。
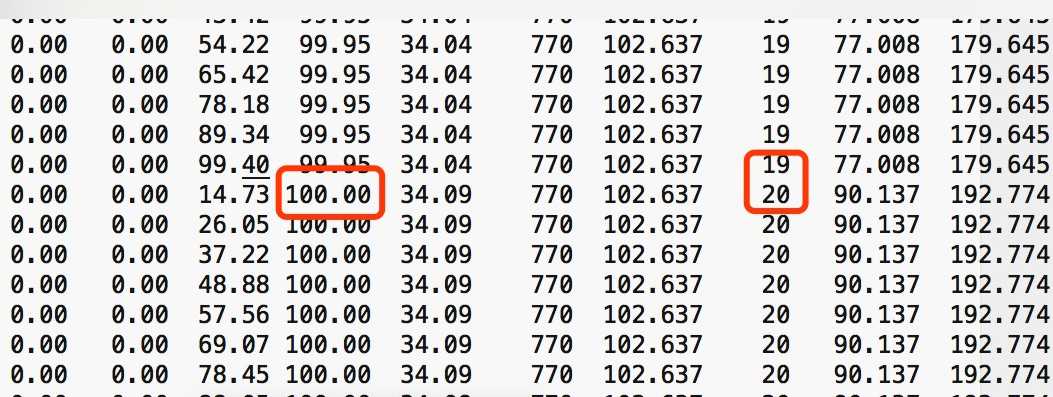
甚至有几台应用 FGC 达到了上百次,时间也高的可怕。
这说明应用的内存使用肯定是有问题的,有许多赖皮对象始终回收不掉。
由于生产上的内存 dump 文件非常大,达到了几十 G。也和我们生产环境配置的内存太大有关。
所以导致想使用 MAT 分析需要花费大量时间。
MAT 是 Eclipse 的一个插件,也可以单独使用,可以用来分析 Java 的堆内存,找出内存泄露的原因。
因此我们就想是否可以在本地复现,这样就好定位的多。
为了尽快的复现问题,我将本地应用最大堆内存设置为 150M。然后在消费 Kafka 那里 Mock 了一个 while 循环一直不断的生成数据。
同时当应用启动之后利用 VisualVM 连上应用实时监控内存、GC 的使用情况。
结果跑了 10 几分钟内存使用并没有什么问题。根据图中可以看出,每一次 GC 内存都能有效的回收,所以并没有复现问题。
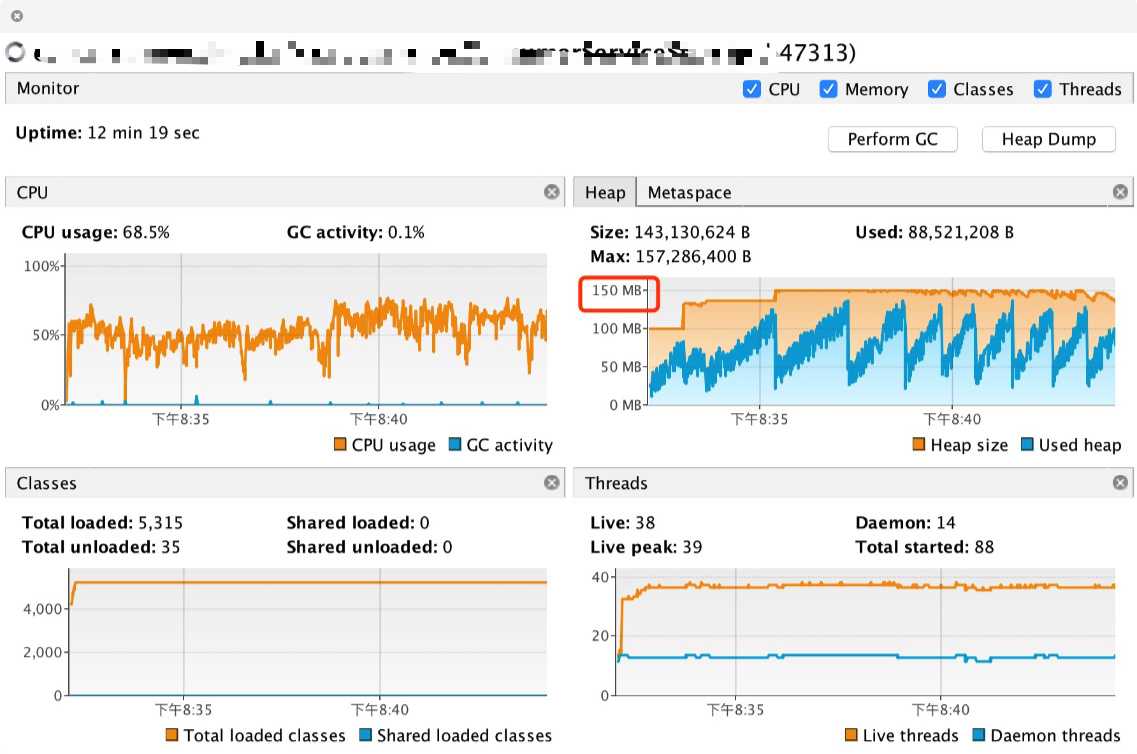
没法复现问题就很难定位。于是我们就采用了一种古老的方法——review 代码,发现生产的逻辑和我们用 while 循环 Mock 的数据还不太一样。
果然 review 代码是保障程序性能的第一道防线,诚不欺我。大家在写完代码的时候,尽量也要团队 review 一次。
后来查看生产日志发现每次从 Kafka 中取出的都是几百条数据,而我们 Mock 时每次只能产生一条。
为了尽可能的模拟生产情况便在服务器上跑了一个生产者程序,一直源源不断的向 Kafka 中发送数据。
果然不出意外只跑了一分多钟内存就顶不住了,观察下图发现 GC 的频次非常高,但是内存的回收却是相形见拙。
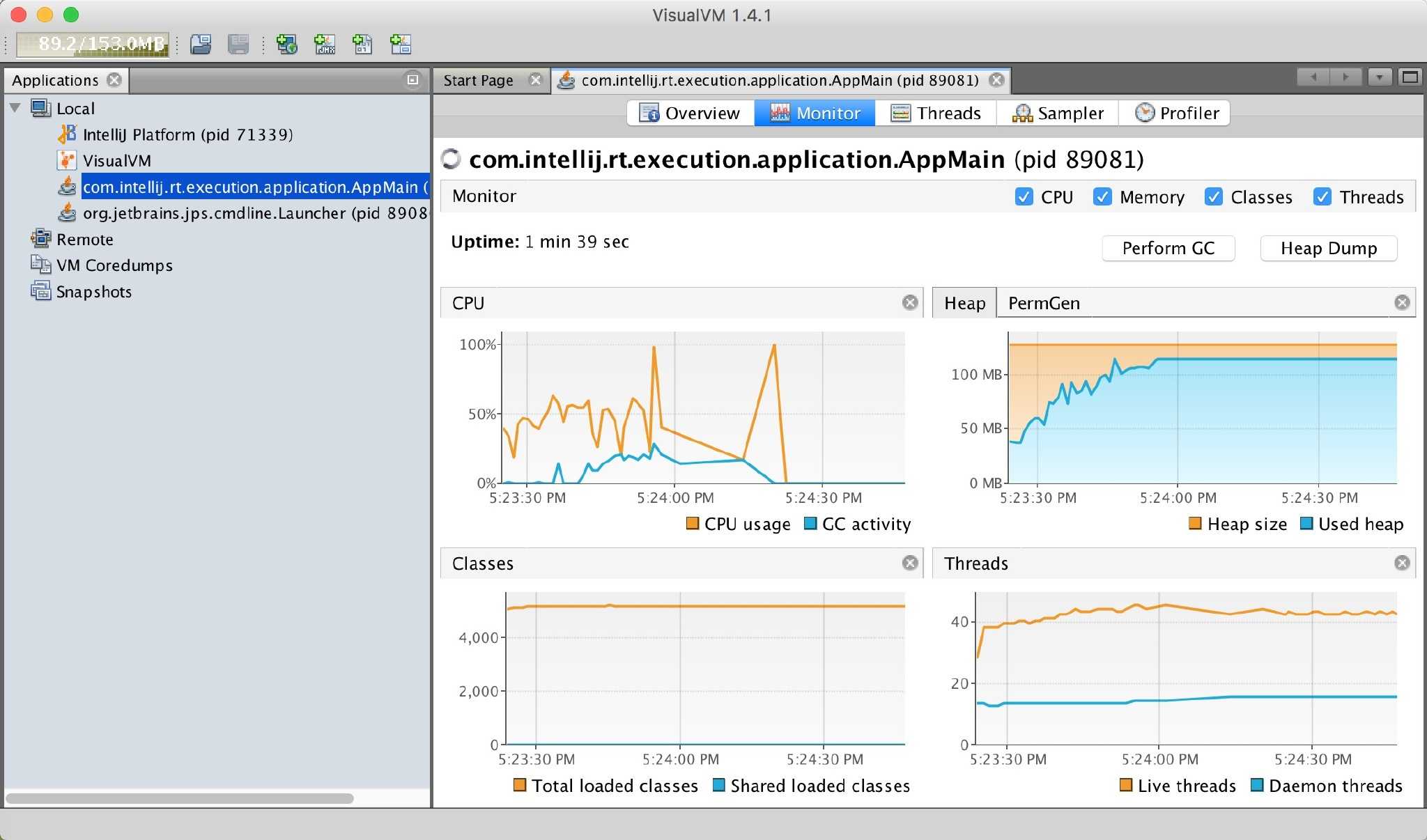
同时后台也开始打印内存溢出了,这样便复现出了问题。
从目前的表现来看,就是内存中有许多对象一直存在强引用关系导致得不到回收。
于是便想看看到底是什么对象占用了这么多的内存,利用 VisualVM 的 HeapDump 功能,就可以立即 dump 出当前应用的内存情况。
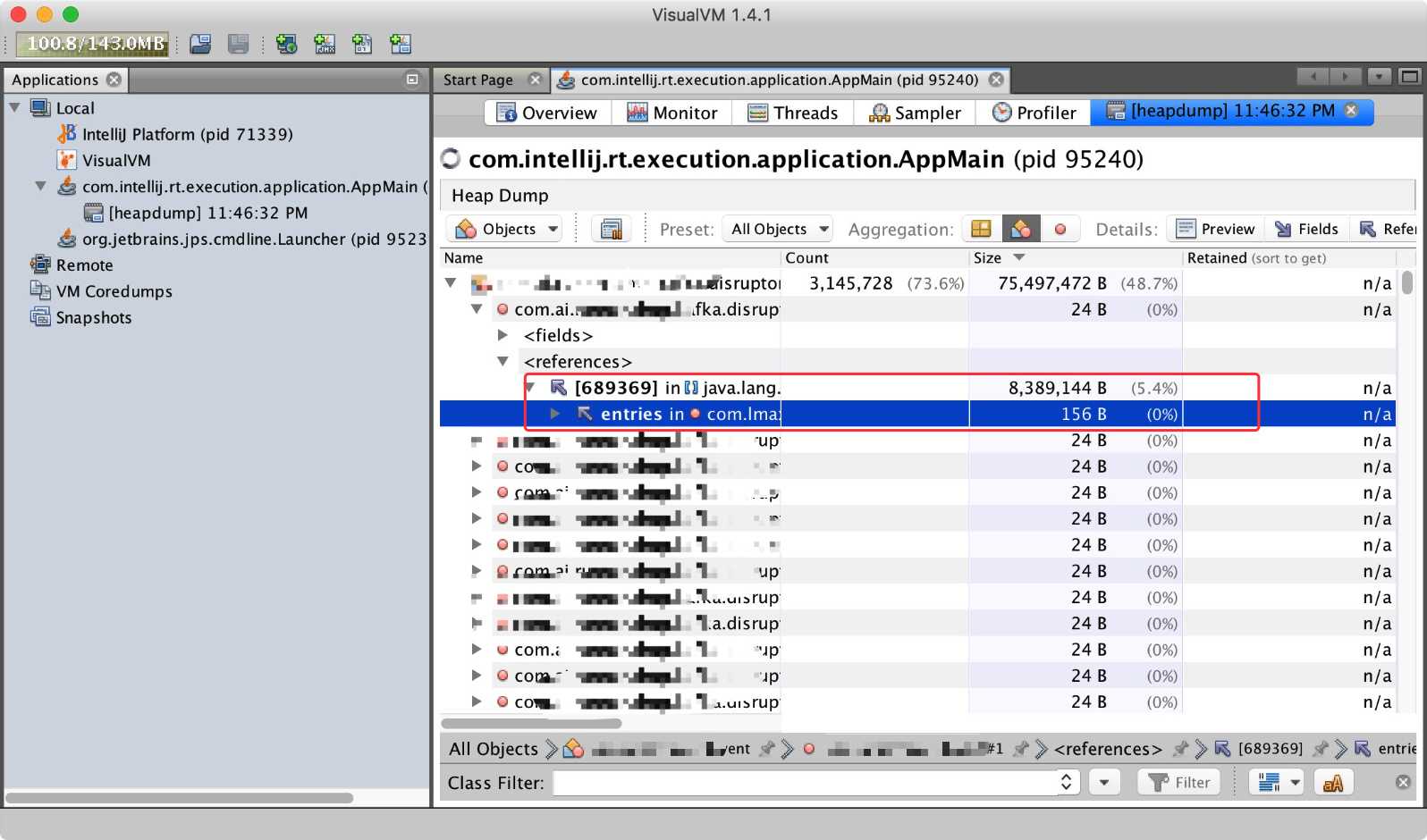
结果发现 com.lmax.disruptor.RingBuffer 类型的对象占用了将近 50% 的内存。
看到这个包自然就想到了 Disruptor 环形队列了。
Disruptor 是一个高性能的异步处理框架,它的核心思想是:通过无锁的方式来实现高性能的并发处理,其性能是高于 JDK 的 BlockingQueue 的。
再次 review 代码发现:从 Kafka 里取出的 700 条数据是直接往 Disruptor 里丢的。
这里也就能说明为什么第一次模拟数据没复现问题了。
模拟的时候是一个对象放进队列里,而生产的情况是 700 条数据放进队列里。这个数据量就是 700 倍的差距啊。
而 Disruptor 作为一个环形队列,在对象没有被覆盖之前是一直存在的。
我也做了一个实验,证明确实如此。
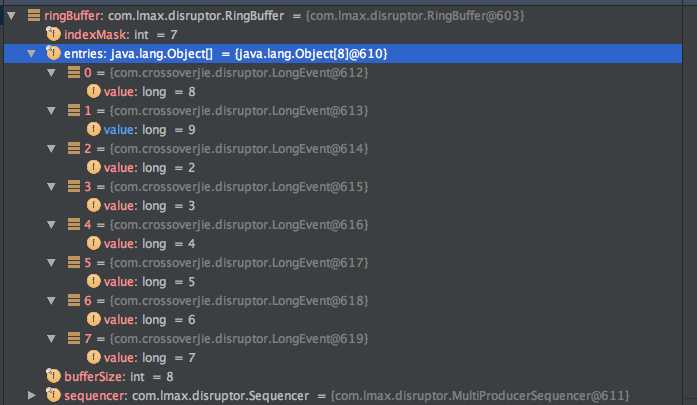
我设置队列大小为 8 ,从 0~9 往里面写 10 条数据,当写到 8 的时候就会把之前 0 的位置覆盖掉,后面的以此类推(类似于 HashMap 的取模定位)。
所以在生产环境上,假设我们的队列大小是 1024,那么随着系统的运行最终会导致 1024 个位置上装满了对象,而且每个位置都是 700 个!
于是查看了生产环境上 Disruptor 的 RingBuffer 配置,结果是:1024*1024。
这个数量级就非常吓人了。
为了验证是否是这个问题,我在本地将该值设为 2 ,一个最小值试试。
同样的 128M 内存,也是通过 Kafka 一直源源不断的取出数据。通过监控如下:
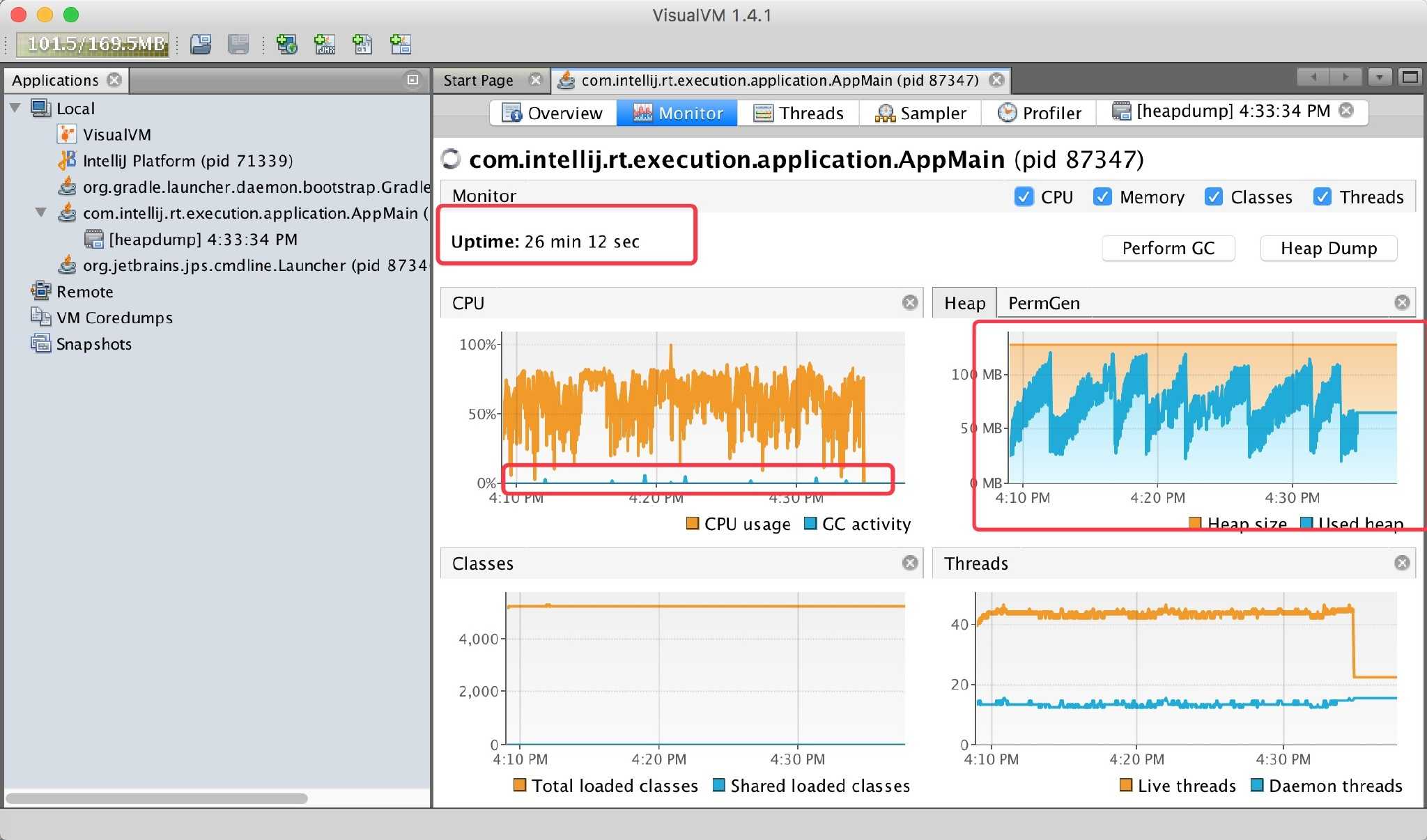
跑了 20 几分钟系统一切正常,每当一次 GC 都能回收大部分内存,最终呈现锯齿状。
这样问题就找到了,不过生产上这个值具体设置多少还得根据业务情况测试才能知道,但原有的 1024*1024 是绝对不能再使用了。
虽然到了最后也就改了一行代码(还没改,直接修改配置),但这个排查过程我觉得是很有意义的。
也会让大部分觉得 JVM 这样的黑盒难以下手的球友有一个直观感受。
同时也得感叹 Disruptor 东西虽好,也不能乱用哦!
相关演示代码查看:
https://github.com/crossoverJie/JCSprout/tree/master/src/main/java/com/crossoverjie/disruptor
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括 Java 基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM 等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
