本教程讲述如何水平扩展一个DolphinDB集群,以增强其数据容量及计算能力。
DolphinDB的集群是由控制节点(controller),代理节点(agent)及数据节点(data node)三类节点组成:
- controller负责管理集群元数据,提供Web集群管理工具。controller有三个配置文件:
- controller.cfg 负责定义控制节点的相关配置,比如IP端口,控制节点连接数上限等。
- cluster.nodes 定义集群内部的节点清单,控制节点会通过这个文件来获取集群的节点信息。
- cluster.cfg 负责集群内每一个节点的个性化配置,比如node3的volumes配置参数等。
- agent部署在每一台物理机上,负责本机节点的启动和停止。Agent上的配置文件为:
- agent.cfg 定义代理节点配置参数,比如代理节点IP和端口,所属集群控制节点等信息。与代理节点部署包一起部署在各台物理机上。
- data node是计算和数据节点,负责分发处理计算任务和存储数据。
离线扩展数据节点的主要步骤如下:
- 在新服务器上部署agent,并且配置好agent.cfg
- 向controller注册新的data node信息和agent信息
- 重启集群内controller和所有data node
在线扩展数据节点的主要步骤如下:
- 在新服务器上部署agent,并且配置好agent.cfg
- 向controller注册新的data node信息和agent信息
- 启动新节点
若仅对某data node存储空间进行扩展,例如增加磁盘卷,只需要修改节点配置文件,为指定节点volumes参数增加路径。
本例中,我们将为已有集群增加一台新的物理服务器,并在其上增加一个新的数据节点。 1.30.4之前版本DolphinDB只支持离线方式扩展,需要重启集群(详细步骤见3.1节),1.30.4版本新增动态方式扩展数据节点,无需重启集群(详细步骤见3.2节)。
原集群的配置情况为:服务器4台,操作系统均为 ubuntu 16.04,部署了 DolphinDB 1.30.4 版本。
172.18.0.10 : controller
172.18.0.11 : datanode1
172.18.0.12 : datanode2
172.18.0.13 : datanode3
具体的配置文件如下:
controller.cfg
localSite=172.18.0.10:8990:ctl8990
cluster.nodes
localSite,mode
172.18.0.11:8701:agent1,agent
172.18.0.12:8701:agent2,agent
172.18.0.13:8701:agent3,agent
172.18.0.11:8801:node1,datanode
172.18.0.12:8802:node2,datanode
172.18.0.13:8803:node3,datanode
启动controller脚本:
nohup ./dolphindb -console 0 -mode controller -script dolphindb.dos -config config/controller.cfg -logFile log/controller.log -nodesFile config/cluster.nodes &
启动agent脚本:
./dolphindb -mode agent -home data -script dolphindb.dos -config config/agent.cfg -logFile log/agent.log
为了在扩展集群工作完成之后验证效果,在集群内创建一个分布式数据库,并写入初始数据:
data = table(1..1000 as id,rand(`A`B`C,1000) as name)
//分区时预留了1000的余量,预备后续写入测试用
db = database("dfs://scaleout_test_db",RANGE,cutPoints(1..2000,10))
tb = db.createPartitionedTable(data,"scaleoutTB",`id)
tb.append!(data)
执行完后点击集群web管理界面的 DFS Explorer 按钮,查看生成的数据分布情况。

在后续完成集群扩展之后,我们会向此数据库中追加数据,来验证拓展部分是否已经启用。
需要了解集群初始化配置可以参考 多物理机上部署集群教程
需要新增的物理机IP:
172.18.0.14
新增的节点信息:
172.18.0.14:8804:datanode4
原服务器上的agent部署在/home/目录下,将该目录下文件拷贝到新机器的/home/目录,并对/home//config/agent.cfg做如下修改:
//指定新的agent node的IP和端口号
localSite=172.18.0.14:8701:agent4
//controller信息
controllerSite=172.18.0.10:8990:ctl8990
mode=agent
修改节点清单配置cluster.nodes,配置新增加的data node和agent node:
localSite,mode
172.18.0.11:8701:agent1,agent
172.18.0.12:8701:agent2,agent
172.18.0.13:8701:agent3,agent
172.18.0.11:8801:node1,datanode
172.18.0.12:8802:node2,datanode
172.18.0.13:8803:node3,datanode
//新增agent和data node
172.18.0.14:8704:agent4,agent
172.18.0.14:8804:node4,datanode
集群扩展数据节点必须重启整个集群,包括集群controller和所有的data node。
- 访问集群web管理界面
http://172.18.0.10:8990,关闭所有的数据节点。
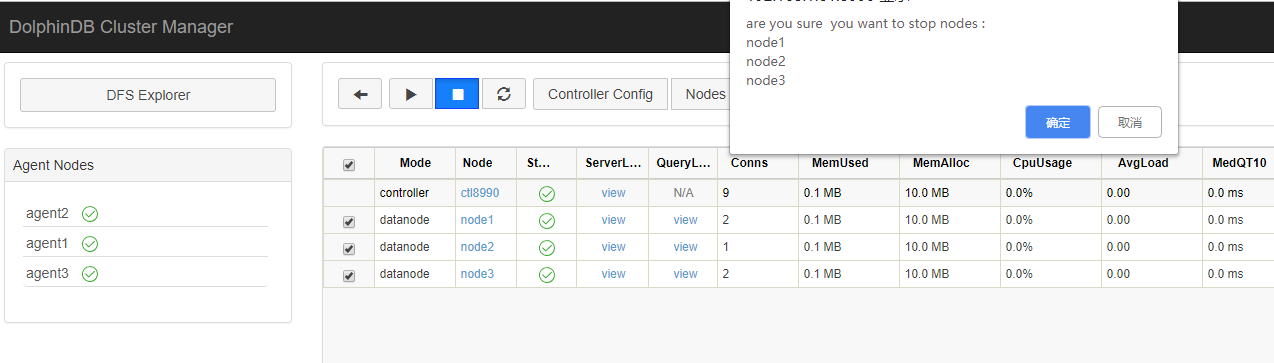
-
在172.18.0.10服务器上执行
pkill -9 dolphindb以关闭controller。 -
重新启动controller。
-
回到web管理界面,可以看到已经新增了一个agent4,在web界面上启动所有数据节点。

至此我们已经完成了离线方式新节点的增加。
服务器配置文件的修改同3.1节,修改完agent.cfg以及cluster.nodes,启动该服务器上的agent节点,然后通过web或GUI连接集群的控制节点并执行以下代码:
addAgentToController("172.18.0.14",8704,"agent4");
addNode("172.18.0.14",8804,"node4");
回到web管理界面,可以看到已经新增了一个agent4并且是未启动状态,再在web界面上启动所有数据节点。
至此我们已经完成了在线方式新节点的增加。
下面我们通过向集群写入一些数据来验证node4是否已经在集群中启用。
tb = database("dfs://scaleout_test_db").loadTable("scaleoutTB")
tb.append!(table(1001..2000 as id,rand(`A`B`C,1000) as name))
点击DFS Explorer并打开scaleout_test_db,可以看到数据已经分布到新添加的 node4 节点上。
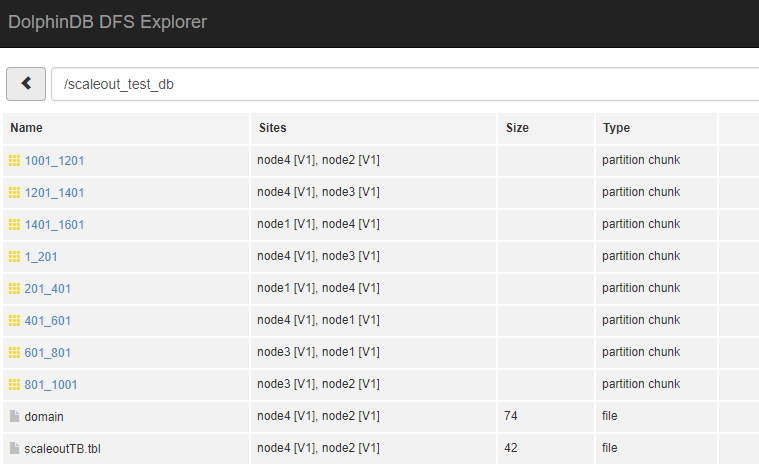
在流行的MPP架构的集群中,添加节点后因为hash值变了,必须要对一部分数据resharding,而通常对海量数据做resharding需要很长时间。DolphinDB的数据存储基于底层分布式文件系统,通过元数据进行数据副本的管理,所以扩展了节点之后,不需要对原有的数据进行resharding,新增的数据会保存到新的数据节点去。通过resharding可以让数据分布更加均匀,DolphinDB正在开发这样的工具。
本例中沿用上例中的原有集群。由于node3所在服务器本身的磁盘空间不足,为node3扩展了一块磁盘,路径为/dev/disk2。
DolphinDB database 的节点存储可以通过配置参数volumes来配置,默认的存储路径为<HomeDir>/<Data Node Alias>/storage,本例中为/home/server/data/node3/storage目录。
若从默认路径增加磁盘,那么在设置volumes参数时,必须要将原默认路径显式设置,否则会导致默认路径下元数据丢失。
默认的volumes参数值如下,如果cluster.cfg中没有这一行,需要手工添加。
cluster.cfg
node3.volumes=/home/server/data/node3/storage
要增加新的磁盘路径/dev/disk2/node3到node3节点,只要将路径添加到上述配置后,用逗号分隔即可。
cluster.cfg
node3.volumes=/home/server/data/node3/storage,/dev/disk2/node3
修改配置文件后,在controller上执行loadClusterNodesConfigs()使得controller重新载入节点配置。如果上述步骤在集群管理web界面上完成,这个重载过程会自动完成,无需手工执行loadClusterNodesConfigs()。配置完成后无需重启controller,只要在web界面上重启node3节点即可使新配置生效。
如果希望node3暂不重启,但是新的存储马上生效,可以在node3上执行addVolumes("/dev/disk2/node3")函数动态添加volumes,此函数的效果并不会持久化,重启后会被新配置覆盖。
配置完成后,使用下面的语句向集群写入新数据,查看数据是否被写入新的磁盘卷。
tb = database("dfs://scaleout_test_db").loadTable("scaleoutTB")
tb.append!(table(1501..2000 as id,rand(`A`B`C,500) as name))
数据已被写入:

- 在验证节点的数据写入分布情况时 , 从dfs explorer里经常会发现site信息有时候会发生变化,比如原来保存在node3的数据迁移到其他节点了?
这个问题涉及到DolphinDB的Recovery 机制: DolphinDB的集群支持数据自动Recovery机制,当侦测到集群内部分节点长时间没有心跳时(判定宕机),将会从其他副本中自动恢复数据并且保持整个集群的副本数稳定, 这也是当某个节点长时间未启动,系统后台会发生数据迁移的原因。需要注意的是,这个数据稳定的前提是宕掉的节点数少于系统设置的数据副本数。这个机制涉及到的配置项及默认值如下:
controller.cfg
//集群内每个数据副本数,默认2
dfsReplicationFactor=2
//副本安全策略,0 多个副本允许存在一个节点 1 多个副本必须分存到不同节点,默认0
dfsReplicaReliabilityLevel=1
//节点心跳停止多久开启Recovery,默认不启用,单位ms
dfsRecoveryWaitTime=30000
这3个参数对于系统的数据稳定性非常重要。
dfsRecoveryWaitTime控制recovery的启动,默认不设置即关闭recovery功能。这个等待时间的设置主要是为了避免一些计划内的停机维护导致不必要的recovery,需要用户根据运维的实际情况来设置。
从稳定性上来讲,副本数越多数据越不容易因意外丢失,但是副本数过多也会导致系统保存数据时性能低下,所以dfsReplicationFactor的值不建议低于2,但是具体设置多高需要用户根据整体集群的节点数、数据稳定性需求、系统写入性能需求来综合考虑。
dfsReplicaReliabilityLevel这个设置在生产环境下建议设置为1,0只建议作为学习或者测试环境下使用。