所谓分治就是指的分而治之,即将较大规模的问题分解成几个较小规模的问题,通过对较小规模问题的求解达到对整个问题的求解。当我们将问题分解成两个较小问题求解时的分治方法称之为二分法。
分治的基本思想是将一个规模为n的问题分解为k个规模较小的子问题,这些子问题互相独立且与原问题相似。
找出各部分的解,然后把各部分的解组合成整个问题的解。
解决算法实现的同时,需要估算算法实现所需时间。
- 分治算法时间是这样确定的:
- 解决子问题所需的工作总量(由子问题的个数、解决每个子问题的工作量 决定)合并所有子问题所需的工作量。
- 分治法是把任意大小问题尽可能地等分成两个子问题的递归算法。
- 分治的具体过程:
{{开始}
if ①问题不可分 ②返回问题解
else {
③从原问题中划出含一半运算对象的子问题1;
④递归调用分治法过程,求出解1;
⑤从原问题中划出含另一半运算对象的子问题2;
⑥递归调用分治法过程,求出解2;
⑦将解1、解2组合成整个问题的解;
}
} //结束
【例1】快速排序(递归算法)
void qsort(int l,int r)
{
int i,j,mid,p;
i=l;j=r;
mid=a[(l+r)/2]; //将当前序列在中间位置的数定义为分隔数
do
{
while (a[i]<mid) {i++;} //在左半部分寻找比中间数大的数
while (a[j]>mid) {j--;} //在右半部分寻找比中间数小的数
if (i<=j)
{ //若找到一组与排序目标不一致的数对则交换它们
p=a[i];a[i]=a[j];a[j]=p;
i++;j--; //继续找
}
}while(i<=j); //注意这里要有等号
if (l<j) qsort(l,j); //若未到两个数的边界,则递归搜索左右区间
if (i<r) qsort(i,r);
}【例2】用递归算法实现二分查找即:有n个已经从小到大排序好的数据,输入一个数m,用二分查找算法,判断它是否在这n个数中。
#include<iostream>
using namespace std;
int jc(int,int);
int n,a[1000],m;
int main()
{
int x,y,i;
cin>>n;
x=1;y=n;
for (i=1;i<=n;i++) //输入排序好的数
cin>>a[i];
cin>>m; //输入要查找的数
jc(x,y); //递归过程
cout<<endl;
}
int jc(int x,int y) //递归过程
{
int k;
k=(x+y)/2; //取中间位置点
if (a[k]==m)
cout<<"then num in "<<k<<endl; //找到查找的数,输出结果
if (x>y) cout<<"no find"<<endl; //找不到该数
else
{
if (a[k]<m) jc(k+1,y); //在后半中查找
if (a[k]>m) jc(x,k-1); //在前半中查找
}
}【例3】一元三次方程求解
有形如:ax3+bx2+cx+d=0这样的一个一元三次方程。给出该方程中各项的系数(a,b,c,d均为实数),并约定该方程存在三个不同实根(根的范围在-100至100之间),且根与根之差的绝对值≥1。
要求由小到大依次在同一行输出这三个实根(根与根之间留有空格),并精确到小数点后2位。
提示:记方程f(x)=0,若存在2个数x1和x2,且x1<x2,f(x1)* f(x2)<0,则在(x1,x2)之间一定有一个根。
输入:a,b,c,d 输出:三个实根(根与根之间留有空格)
【输入输出样例】
输入:1 -5 -4 20 输出:-2.00 2.00 5.00
【算法分析】
这是一道有趣的解方程题。为了便于求解,设方程f(x)=ax3+bx2+cx+d=0,设根的值域(-100至100之间)中有x, 其左右两边相距0.0005的地方有x1和x2两个数,即 x1=x-0.0005,x2=x+0.0005。
x1和x2间的距离(0.001)满足精度要求(精确到小数点后2位)。若出现如图1所示的两种情况之一,则确定x为f(x)=0的根。**
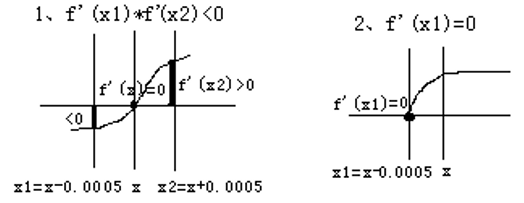
有两种方法计算f(x)=0的根x:
1.枚举法
根据根的值域和根与根之间的间距要求(≥1),我们不妨将根的值域扩大100倍(-10000≤x≤10000),依次枚举该区间的每一个整数值x,并在题目要求的精度内设定区间:x1=,x2=。
若区间端点的函数值f(x1)和f(x2)异号或者在区间端点x1的函数值f(x1)=0,则确定为f(x)=0的一个根。
由此得出算法:
输入方程中各项的系数a,b,c,d ;
for (x=-10000;x<=10000;x++) //枚举当前根*100的可能范围
{
x1=(x-0.05)/100;x2=(x+0.05)/100;//在题目要求的精度内设定区间
if (f(x1)*f(x2)<0||f(x1)==0) //若在区间两端的函数值异号或在x1处
的函数值为0,则确定x/100为根
printf(“%.2f”,x/100);
}
其中函数f(x)计算x3+b*x2+c*x+d:
double f(double x) //计算x3+b*x2+c*x+d
{
f=x*x*x+b*x*x+c*x+d;
} //f函数 2.分治法
枚举根的值域中的每一个整数x(-100≤x≤100)。由于根与根之差的绝对值≥1,因此设定搜索区间[x1,x2],其中x1=x,x2=x+1。若
- f(x1)=0,则确定x1为f(x)的根;
f(x1)*f(x2)>0,则确定根x不在区间[x1,x2]内,设定[x2,x2+1]为下一个搜索区间f(x1)*f(x2)<0,则确定根x在区间[x1,x2]内。
如果确定根x在区间[x1,x2]内的话(f(x1)*f(x2)<0),如何在该区间找到根的确切位置。采用二分法,将区间[x1,x2]分成左右两个子区间:左子区间[x1,x]和右子区间[x,x2]:
如果f(x1)*f(x)≤0,则确定根在左区间[x1,x]内,将x设为该区间的右指针(x2=x),继续对左区间进行对分;如果f(x1)*f(x)>0,则确定根在右区间[x,x2]内,将x设为该区间的左指针(x1=x),继续对右区间进行对分;
上述对分过程一直进行到区间的间距满足精度要求为止(x2-x1<0.001)。此时确定x1为f(x)的根。
由此得出算法:
输入方程中各项的系数a,b,c,d ;
{
for (x=-100;x<=100;x++) //枚举每一个可能的根
{
x1=x;x2=x+1; //确定根的可能区间
if (f(x1)==0) printf("%.2f ",x1); //若x1为根,则输出
else if (f(x1)*f(x2)<0) //若根在区间[x1,x2]中
{
while (x2-x1>=0.001) //若区间[x1,x2]不满足精度要求,则循环
{
xx=(x2+x1)/2; //计算区间[x1,x2]的中间位置
if ((f(x1)*f(xx))<=0) //若根在左区间,则调整右指针
x2=xx;
else x1=xx; //若根在右区间,则调整左指针
}
printf("%.2f ",x1); //区间[x1,x2]满足精度要求,确定x1为根
}
}
cout<<endl;
}
double f(double x) //将x代入函数
{
return (x*x*x*a+b*x*x+x*c+d);
}
其中f(x)的函数说明如枚举法所示。【例4】、循环比赛日程表(match)
【问题描述】
设有N个选手进行循环比赛,其中N=2M,要求每名选手要与其他N-1名选手都赛一次,每名选手每天比赛一次,循环赛共进行N-1天,要求每天没有选手轮空。
输入:M
输出:表格形式的比赛安排表
【样例输入】match.in
3
【样例输出】match.out
1 2 3 4 5 6 7 8
2 1 4 3 6 5 8 7
3 4 1 2 7 8 5 6
4 3 2 1 8 7 6 5
5 6 7 8 1 2 3 4
6 5 8 7 2 1 4 3
7 8 5 6 3 4 1 2
8 7 6 5 4 3 2 1
【问题分析】
以M=3(即N=23=8)为例,可以根据问题要求,制定出如下图所示的一种方案:
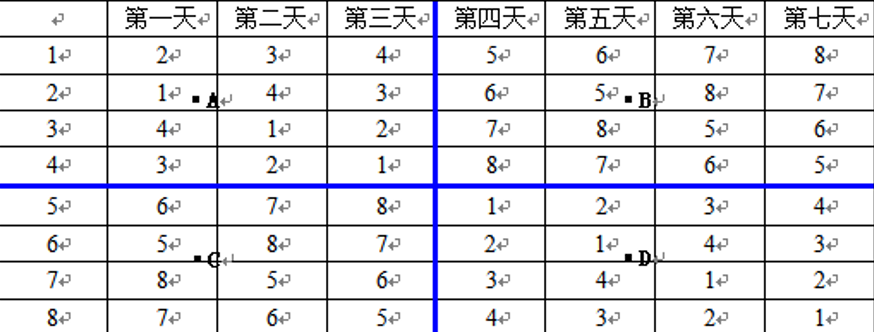
以表格的中心为拆分点,将表格分成A、B、C、D四个部分,就很容易看出有A=D,B=C,并且,这一规律同样适用于各个更小的部分。
设有n个选手的循环比赛,其中n=2m,要求每名选手要与其他n-1名选手都赛一次。每名选手每天比赛一次,循环赛共进行n-1天。要求每天没有选手轮空.以下是八名选手时的循环比赛表,表中第一行为八位选手的编号,下面七行依次是每位选手每天的对手。
1 2 3 4 5 6 7 8
2 1 4 3 6 5 8 7
3 4 1 2 7 8 5 6
4 3 2 1 8 7 6 5
5 6 7 8 1 2 3 4
6 5 8 7 2 1 4 3
7 8 5 6 3 4 1 2
8 7 6 5 4 3 2 1
【算法分析】
从八位选手的循环比赛表中可以看出,这是一个具有对称性的方阵,可以把方阵一分为四来看,那么左上角的4*4的方阵就是前四位选手的循环比赛表,而右上角的4*4的方阵就是后四位选手的循环比赛表,它们在本质上是一样的,都是4个选手的循环比赛表.
所不同的只是选手编号不同而已,将左上角中方阵的所有元素加上4就能得到右上角的方阵.
下方的两个方阵表示前四位选手和后四位选手进行交叉循环比赛的情况,同样具有对称性,将右上角方阵复制到左下角即得到1,2,3,4四位选手和5,6,7,8四位选手的循环比赛表,根据对称性, 右下角的方阵应与左上角的方阵相同.
这样,八名选手的循环比赛表可以由四名选手的循环比赛表根据对称性生成出来.
同样地, 四名选手的循环比赛表可以由二名选手的循环比赛表根据对称性生成出来,而两名选手的循环比赛表可以说是已知的,这种程序设计方法叫做分治法,其基本思想是把一个规模为n的问题分成若干个规模较小的问题,使得从这些较小问题的解易于构造出整个问题的解。
程序中用数组matchlist记录n名选手的循环比赛表, 整个循环比赛表从最初的1*1的方阵按上述规则生成出2*2 的方阵, 再生成出4*4 的方阵,……,直到生成出整个循环比赛表为止.变量half表示当前方阵的大小,也是要生成的下一个方阵的大小的一半 。
#include<cstdio>
const int MAXN=33,MAXM=5;
int matchlist[MAXN][MAXN];
int m;
int main()
{
printf("Input m:");
scanf("%d",&m);
int n=1<<m,k=1,half=1; // 1<<m 相当于 2^m
matchlist[0][0]=1;
while (k<=m)
{
for (int i=0;i<half;i++) //构造右上方方阵
for (int j=0;j<half;j++)
matchlist[i][j+half]=matchlist[i][j]+half;
for (int i=0;i<half;i++) //对称交换构造下半部分方阵
for (int j=0;j<half;j++)
{
matchlist[i+half][j]=matchlist[i][j+half]; //左下方方阵等于右上方方阵
matchlist[i+half][j+half]=matchlist[i][j]; //右下方方阵等于左上方方阵
}
half*=2;
k++;
}
for (int i=0;i<n;i++)
{
for (int j=0;j<n;j++)
printf("%4d",matchlist[i][j]);
putchar('\n');
}
return 0;
}【例5】取余运算(mod)
【问题描述】
输入b,p,k的值,求bp mod k的值。其中b,p,k*k为长整形数。
【输入样例】mod.in
2 10 9
【输出样例】mod.out
2^10 mod 9=7
【算法分析】
本题主要的难点在于数据规模很大(b,p都是长整型数),对于bp显然不能死算,那样的话时间复杂度和编程复杂度都很大。
下面先介绍一个原理:A*B%K = (A%K )*(B% K )%K。显然有了这个原理,就可以把较大的幂分解成较小的,因而免去高精度计算等复杂过程。那么怎样分解最有效呢?
显然对于任何一个自然数P,有P=2 * P/2 + P%2,如19=2 * 19/2 + 19%2=2*9+1,利用上述原理就可以把B的19次方除以K的余数转换为求B的9次方除以K的余数,即B19=B2*9+1=B*B9*B9,再进一步分解下去就不难求得整个问题的解。
#include<iostream>
#include<cstdio>
using namespace std;
int b,p,k,a;
int f(int p) //利用分治求b^p % k
{
if (p==0) return 1; // b^0 %k=1
int tmp=f(p/2)%k;
tmp=(tmp*tmp) % k; // b^p %k=(b^(p/2))^2 % k
if (p%2==1) tmp=(tmp * b) %k; //如果p为奇数,则 b^p %
return tmp; //k=((b^(p/2))^2)* b%k
}
int main()
{
cin>>b>>p>>k; //读入3个数
int tmpb=b; //将b的值备份
b%=k; //防止b太大
printf("%d^%d mod %d=%d\n",tmpb,p,k,f(p)); //输出
return 0;
}【例8】、黑白棋子的移动(chessman)
【问题描述】
有2n个棋子(n≥4)排成一行,开始位置为白子全部在左边,黑子全部在右边,如下图为n=5的情形:
○○○○○●●●●●
移动棋子的规则是:每次必须同时移动相邻的两个棋子,颜色不限,可以左移也可以右移到空位上去,但不能调换两个棋子的左右位置。每次移动必须跳过若干个棋子(不能平移),要求最后能移成黑白相间的一行棋子。如n=5时,成为:
○●○●○●○●○●
任务:编程打印出移动过程。
【输入样例】chessman.in
7
【输出样例】chessman.out
step 0:ooooooo*******--
step 1:oooooo--******o*
step 2:oooooo******--o*
step 3:ooooo--*****o*o*
step 4:ooooo*****--o*o*
step 5:oooo--****o*o*o*
step 6:oooo****--o*o*o*
step 7:ooo--***o*o*o*o*
step 8:ooo*o**--*o*o*o*
step 9:o--*o**oo*o*o*o*
step10:o*o*o*--o*o*o*o*
step11:--o*o*o*o*o*o*o*
【算法分析】
我们先从n=4开始试试看,初始时:
○○○○●●●●
第1步:○○○——●●●○● {—表示空位}
第2步:○○○●○●●——●
第3步:○——●○●●○○●
第4步:○●○●○●——○●
第5步:——○●○●○●○●
如果n=5呢?我们继续尝试,希望看出一些规律,初始时:
○○○○○●●●●●
第1步:○○○○——●●●●○●
第2步:○○○○●●●●——○●
这样,n=5的问题又分解成了n=4的情况,下面只要再做一下n=4的5个步骤就行了。同理,n=6的情况又可以分解成n=5的情况,……,所以,对于一个规模为n的问题,我们很容易地就把他分治成了规模为n-1的相同类型子问题。
数据结构如下:数组c[1..max]用来作为棋子移动的场所,初始时,c[1]~c[n]存放白子(用字符o表示),c[n+1]~c[2n]存放黑子(用字符*表示),c[2n+1],c[2n+2]为空位置(用字符—表示)。最后结果在c[3]~c[2n+2]中。
#include<iostream>
using namespace std;
int n,st,sp;
char c[101];
void print() //打印
{
int i;
cout<<"step "<<st<<':';
for (i=1;i<=2*n+2;i++) cout<<c[i];
cout<<endl;
st++;
}
void init(int n) //初始化
{
int i;
st=0;
sp=2*n+1;
for (i=1;i<=n;i++) c[i]='o';
for (i=n+1;i<=2*n;i++) c[i]='*';
c[2*n+1]='-';c[2*n+2]='-';
print();
}
void move(int k) //移动一步
{
int j;
for (j=0;j<=1;j++)
{
c[sp+j]=c[k+j];
c[k+j]='-';
}
sp=k;
print();
}
void mv(int n) //主要过程
{
int i,k;
if (n==4) //n等于4的情况要特殊处理
{
move(4); move(8); move(2); move(7); move(1);
}
else
{
move(n); move(2*n-1); mv(n-1);
}
}
int main()
{
cin>>n;
init(n);
mv(n);
}