list = hotelService.list();
+ BulkRequest request = new BulkRequest();
+ // 添加采用indexRequest
+ for (Hotel hotel : list) {
+ // 转为HotelDoc并添加
+ HotelDoc hotelDoc = new HotelDoc(hotel);
+ // 添加到请求
+ request.add(new IndexRequest("hotel")
+ .id(hotelDoc.getId().toString())
+ .source(JSON.toJSONString(hotelDoc)));
+ }
+ client.bulk(request,RequestOptions.DEFAULT);
+}
+```
+
+### 总结
+
+文档操作的基本步骤:
+
+- 初始化RestHighLevelClient
+- 创建xxxRequest。xxx是Index、Get、Update、Delete
+- 准备参数(Index和Update时需要)
+- 发送请求。调用RestHighLevelClient.xxx(),xxx是index、get、update、delete
+- 解析结果(GET需要)
+
diff --git a/public/markdowns/SpringSecurity.md b/public/markdowns/SpringSecurity.md
new file mode 100644
index 0000000..14fad35
--- /dev/null
+++ b/public/markdowns/SpringSecurity.md
@@ -0,0 +1,228 @@
+---
+title: SpringSecurity
+abbrlink: 7d2eec83
+date: 2023-10-26 22:38:08
+tags:
+categories:
+ - 安全
+description: SpringSecurity
+---
+
+# SpringSecurity简介
+
+Spring是一个很棒的Java应用开发框架,Spring Security 基于Spring框架,提供了一套Web应用安全性的完整解决方案,一般来说,web应用的安全性包括**用户认证(Authenticaiton)和用户授权(Authorization)**两个部分
+
+- 用户认证指的是验证某个用户是否为系统中的合法主体,也就是说,该用户能否访问该系统,用户认证一般要求用户提供用户名和密码。系统通过校验用户名和密码来完成认证过程
+- 用户授权指的是验证某个用户是否有权限执行某个操作。在一个系统中,不同用户所具有的权限是不同的。比如对一个文件来说,有的用户只能进行读取,而有的用户可以进行修改。一般来说,系统会为不同的用户分配不同的角色,而每个角色则对应一系列的权限
+
+在用户认证方面,Spring Security框架支持主流的认证方式,包括Http基本认证、Http表单验证、Http摘要认证、OpenID和LDAP等。在用户授权方面。Spring Security提供了基于角色的访问控制和访问控制列表(Access Control List,ACL),可以对应用中的领域对象进行细粒度的控制
+
+Spring Security是一套安全框架,可以基于RBAC(基于角色的权限控制)对用户的访问权限进行控制
+
+核心思想是通过一系列的filter chain来进行拦截过滤,对用户的访问权限进行控制
+
+spring security的核心功能主要包括:
+
+- 认证(你是谁)
+- 授权(你能干什么)
+- 攻击防护(防止伪造身份)
+
+其核心就是一组过滤器链,项目启动后将会自动配置。最核心的就是Basic Authentication Filter用来认证用户的身份,一个在spring security 中一种过滤器处理一种认证方式
+
+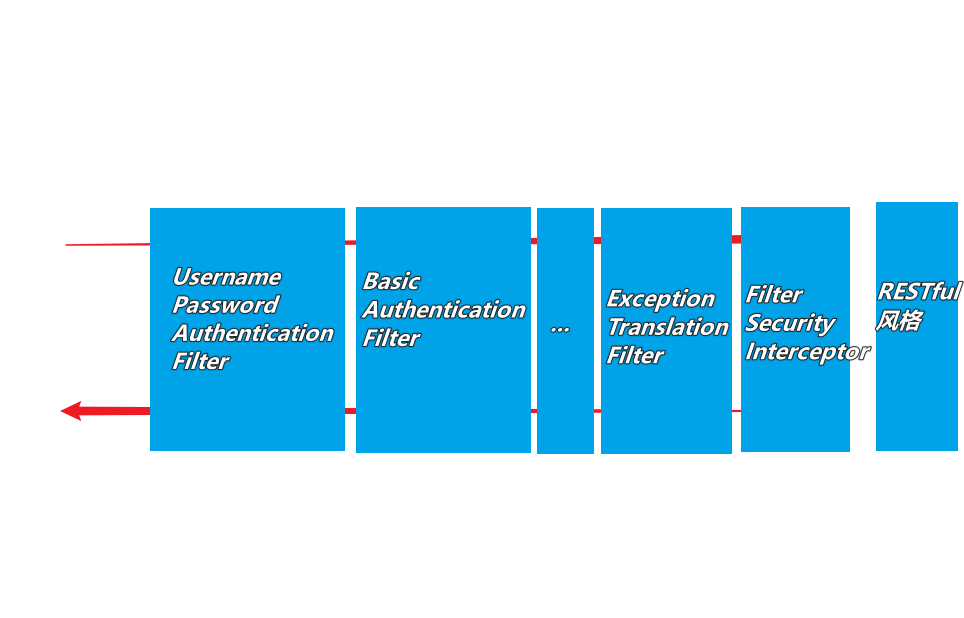 +
+比如,对于username password认证过滤器来说,
+
+```
+会检查是否是一个登录请求;
+是否包含username和password(也就是该过滤器需要的一些认证信息);
+如果不满足则放行给下一个;
+下一个按照自身的职责判定是否是自身需要的信息,basic的特征就是在请求头中有Authorization:Basic eHh4Onh4的信息。中间可能还有更多的认证过滤器。最后一环是FilterSecurityInterceptor,这里会判定该请求是否能进行访问rest服务,判断的依据是BrowserSecurityConfig中的配置,如果被拒绝了就会抛出不同的异常(根据具体的原因),Exception Translation Filter会捕获抛出的错误,然后根据不同的认证方式进行信息的返回提示
+从Exception Translation Filter到最后的过滤器都无法控制,其他的可以进行配置是否生效
+```
+
+
+
+# 认证和授权
+
+ 一般来说的应用访问安全性,都是围绕认证(Authentication)和授权(Authorization)这两个核心概念来展开
+
+即:
+
+- 首先需要确认用户身份
+- 再确认用户是否有访问指定资源的权限
+
+认证这块的解决方案有很多,主流的有`CAS`、`SAML2`、`OAUTH2`等,常说的单点登录方案(SSO)就是这块授权的话,主流一般是spring security和shiro
+
+shiro比较轻量级,相比较而言spring security 架构比较复杂
+
+## OAuth2
+
+OAuth2是一个关于授权的开放标准,核心思路是通过各类认证手段认证用户身份
+
+并颁发token(令牌),使得第三方应用可以使用该令牌在**限定时间、限定范围**访问**指定资源**
+
+主要涉及RFC规范有【`RFC6748`(整体授权框架)】、【`RFC6750`(令牌使用)】、【`RFC6819`(威胁模型)】这几个,一般需要了解的是`RFC6749`
+
+获取令牌的方式主要有四种,分别是`授权码模式`、`简单模式`、`密码模式`、`客户端模型`
+
+总之:OAuth2是一个授权(Authorization)协议。
+
+认证(Authentication)证明你是不是这个人,而授权(Authoration)则是证明这个人有没有访问这个资源(Resource)的权限。
+
+### OAuth2的抽象流程
+
+ +--------+ +---------------+
+ | |--(A)- Authorization Request ->| Resource |
+ | | | Owner |
+ | |<-(B)-- Authorization Grant ---| |
+ | | +---------------+
+ | |
+ | | +---------------+
+ | |--(C)-- Authorization Grant -->| Authorization |
+ | Client | | Server |
+ | |<-(D)----- Access Token -------| |
+ | | +---------------+
+ | |
+ | | +---------------+
+ | |--(E)----- Access Token ------>| Resource |
+ | | | Server |
+ | |<-(F)--- Protected Resource ---| |
+ +--------+ +---------------+
+
+上面的图是一张来自OAuth2的抽象流程图
+
+Client:客户端应用程序(Application)
+
+Authorization Server:授权服务器
+
+Resource Server:资源服务器
+
+解释上图的大致流程:
+
+- 用户连接客户端应用程序后,客户端应用程序(Client)要求用户给予授权
+- 用户同意给予客户端应用程序授权
+- 客户端应用程序使用上一步获得的授权(Grant),向授权服务器申请令牌
+- 授权服务器对客户端应用程序的授权(Grant)进行验证后,确认无误,发放令牌
+- 客户端应用程序使用令牌,向资源服务器申请获取资源
+- 资源服务器确认令牌无误,同意向客户端应用程序开放资源
+
+其实流程无非如下,用户连接-->客户端-->客户端要求用户给出授权-->客户端拿授权申请令牌-->授权服务器校验授权无误后发放令牌-->客户端拿着令牌,找资源服务器要资源-->资源服务器校验令牌无误后发放资源
+
+从上面的流程可以看出,如何获取**授权(Grant)**才是关键。拥有正确的授权(Authorzation)就可以去拿到任意的东西了
+
+### OAuth2的4种授权类型
+
+#### Authorization Code(授权码模式)
+
+功能最完整、流程最严密的授权模式。通过第三方应用程序服务器与认证服务器进行互动。广泛用于各种第三方认证。
+
+ +----------+
+ | Resource |
+ | Owner |
+ | |
+ +----------+
+ ^
+ |
+ (B)
+ +----|-----+ Client Identifier +---------------+
+ | -+----(A)-- & Redirection URI ---->| |
+ | User- | | Authorization |
+ | Agent -+----(B)-- User authenticates --->| Server |
+ | | | |
+ | -+----(C)-- Authorization Code ---<| |
+ +-|----|---+ +---------------+
+ | | ^ v
+ (A) (C) | |
+ | | | |
+ ^ v | |
+ +---------+ | |
+ | |>---(D)-- Authorization Code ---------' |
+ | Client | & Redirection URI |
+ | | |
+ | |<---(E)----- Access Token -------------------'
+ +---------+ (w/ Optional Refresh Token)
+ Note: The lines illustrating steps (A), (B), and (C) are broken into
+ two parts as they pass through the user-agent.
+
+- 用户(Resource Owner)通过用户代理(User-Agent)访问客户端(Client),客户端索要授权,并将用户导向认证服务器(Authorization Server)
+- 用户选择是否给予客户端授权
+- 假设用户给予授权,认证服务器将用户导向客户端事先指定的**重定向URI**,同时附上一个授权码
+- 客户端收到授权码,附上早先的**重定向URI**,向认证服务器申请令牌。这一步是在客户端的后台服务器上完成的,对用户不可见
+- 认证服务器核对授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。这一步对用户也不可见
+
+#### Implicit(简化模式)
+
+不通过第三方应用程序服务器,直接在浏览器中向认证服务器申请令牌,更适用于移动端的App及没有服务器端的第三方单页面应用。
+
+##### Resource Owner Password(密码模式)
+
+用户向客户端服务器提供自己的用户名和密码,用户对客户端高度信任的情况下使用,比如公司、组织的内部系统,SSO
+
+ +----------+
+ | Resource |
+ | Owner |
+ | |
+ +----------+
+ v
+ | Resource Owner
+ (A) Password Credentials
+ |
+ v
+ +---------+ +---------------+
+ | |>--(B)---- Resource Owner ------->| |
+ | | Password Credentials | Authorization |
+ | Client | | Server |
+ | |<--(C)---- Access Token ---------<| |
+ | | (w/ Optional Refresh Token) | |
+ +---------+ +---------------+
+
+ Figure 5: Resource Owner Password Credentials Flow
+
+- 用户(Resource Owner资源持有者)向客户端(Client)提供用户名和密码
+- 客户端将用户名和密码发给认证服务器(Authorization Server),向后者请求令牌
+- 认证服务器确认无误后,向客户端提供访问令牌
+
+#### Client Credentials(客户端模式)
+
+客户端服务器以自己的名义,而不是以用户的名义,向认证服务器进行认证
+
+## 令牌刷新
+
+```
+ +--------+ +---------------+
+ | |--(A)------- Authorization Grant --------->| |
+ | | | |
+ | |<-(B)----------- Access Token -------------| |
+ | | & Refresh Token | |
+ | | | |
+ | | +----------+ | |
+ | |--(C)---- Access Token ---->| | | |
+ | | | | | |
+ | |<-(D)- Protected Resource --| Resource | | Authorization |
+ | Client | | Server | | Server |
+ | |--(E)---- Access Token ---->| | | |
+ | | | | | |
+ | |<-(F)- Invalid Token Error -| | | |
+ | | +----------+ | |
+ | | | |
+ | |--(G)----------- Refresh Token ----------->| |
+ | | | |
+ | |<-(H)----------- Access Token -------------| |
+ +--------+ & Optional Refresh Token +---------------+
+```
+
+- 客户端找授权服务器索要授权
+
+- 当用户同意给予授权后,授权服务器给予令牌,并给予刷新令牌
+
+- 此时通过令牌去资源服务器中获取资源
+
+- 得到资源
+
+ 假设token过期
+
+- 再次获取资源,发现Token无效了
+- 通过刷新令牌去授权服务器中获取Token
+- 通过Token再次获取令牌和刷新令牌,重复流程
+
diff --git a/public/markdowns/Vue.md b/public/markdowns/Vue.md
new file mode 100644
index 0000000..74b7656
--- /dev/null
+++ b/public/markdowns/Vue.md
@@ -0,0 +1,11821 @@
+---
+title: Vue2
+tags:
+ - Vue2
+categories:
+ - 前端
+description: Vue2
+abbrlink: 4d45ebbb
+---
+# Vue核心
+
+## 搭建Vue环境
+
+先在此处附上Vue的安装教程地址:https://v2.cn.vuejs.org/v2/guide/installation.html
+
+这里有两个版本,一个开发版本,一个生产版本
+
+开发版本是在开发时使用的,当出现问题的时候会在控制台报警告
+
+生产版本是在项目上线时使用的,不会有警告,而且体积更小
+
+
+
+在这里,我使用的是开发版本,学习一般使用开发版
+
+将开发版本下载后保存到本地,使用方法与jquery是一致的,使用来script引入
+
+### 直接用script引入
+
+创建一个文件夹,在里面创建一个html文件
+
+然后直接引入vue文件即可
+
+```html
+
+
+
+
+
+
+
+ Document
+
+
+
+
+
+
+
+
+```
+
+运行文件
+
+### 消除开发环境提示
+
+在console里查看
+
+
+
+第一个是说下载vue的开发者工具来达到一个更好的开发者体验
+
+第二个是说你正在运行开发环境,请你确信在生产环境不要这样做
+
+两个小提示,但是不影响,后面再解决
+
+如果成功引入了Vue,在console上写入Vue会输出其对应的函数
+
+
+
+解决第一个提示的方法是下载一个vue的开发者工具即可
+
+vue开发者工具的github链接如下:https://github.com/vuejs/devtools#vue-devtools
+
+找到下面这个地方,点击进入谷歌商店下载
+
+
+
+
+
+第二个提示需要在代码中对其进行配置
+
+```vue
+
+```
+
+## 模板语法
+
+Vue模板语法有2大类:
+
+1. 插值语法:
+
+ 功能:用于解析标签体内容
+
+ 写法:{{xxx}},xxx是js表达式,且可以直接读取到data中的所有属性
+
+2. 指令语法:
+
+ 功能:用于解析标签(包括:标签属性、标签体内容、绑定事件等)
+
+ 举例:v-bind:hreft="xxx"或简写为:href="xxx",xxx同样要写js表达式。且可以直接读取到data中的所有属性
+
+ 备注:Vue中有很多的指令,且形式都是:v-?????
+
+### 插值语法
+
+```html
+
+
+
+
+
+
+
+ Document
+
+
+
+
+
+
+比如,对于username password认证过滤器来说,
+
+```
+会检查是否是一个登录请求;
+是否包含username和password(也就是该过滤器需要的一些认证信息);
+如果不满足则放行给下一个;
+下一个按照自身的职责判定是否是自身需要的信息,basic的特征就是在请求头中有Authorization:Basic eHh4Onh4的信息。中间可能还有更多的认证过滤器。最后一环是FilterSecurityInterceptor,这里会判定该请求是否能进行访问rest服务,判断的依据是BrowserSecurityConfig中的配置,如果被拒绝了就会抛出不同的异常(根据具体的原因),Exception Translation Filter会捕获抛出的错误,然后根据不同的认证方式进行信息的返回提示
+从Exception Translation Filter到最后的过滤器都无法控制,其他的可以进行配置是否生效
+```
+
+
+
+# 认证和授权
+
+ 一般来说的应用访问安全性,都是围绕认证(Authentication)和授权(Authorization)这两个核心概念来展开
+
+即:
+
+- 首先需要确认用户身份
+- 再确认用户是否有访问指定资源的权限
+
+认证这块的解决方案有很多,主流的有`CAS`、`SAML2`、`OAUTH2`等,常说的单点登录方案(SSO)就是这块授权的话,主流一般是spring security和shiro
+
+shiro比较轻量级,相比较而言spring security 架构比较复杂
+
+## OAuth2
+
+OAuth2是一个关于授权的开放标准,核心思路是通过各类认证手段认证用户身份
+
+并颁发token(令牌),使得第三方应用可以使用该令牌在**限定时间、限定范围**访问**指定资源**
+
+主要涉及RFC规范有【`RFC6748`(整体授权框架)】、【`RFC6750`(令牌使用)】、【`RFC6819`(威胁模型)】这几个,一般需要了解的是`RFC6749`
+
+获取令牌的方式主要有四种,分别是`授权码模式`、`简单模式`、`密码模式`、`客户端模型`
+
+总之:OAuth2是一个授权(Authorization)协议。
+
+认证(Authentication)证明你是不是这个人,而授权(Authoration)则是证明这个人有没有访问这个资源(Resource)的权限。
+
+### OAuth2的抽象流程
+
+ +--------+ +---------------+
+ | |--(A)- Authorization Request ->| Resource |
+ | | | Owner |
+ | |<-(B)-- Authorization Grant ---| |
+ | | +---------------+
+ | |
+ | | +---------------+
+ | |--(C)-- Authorization Grant -->| Authorization |
+ | Client | | Server |
+ | |<-(D)----- Access Token -------| |
+ | | +---------------+
+ | |
+ | | +---------------+
+ | |--(E)----- Access Token ------>| Resource |
+ | | | Server |
+ | |<-(F)--- Protected Resource ---| |
+ +--------+ +---------------+
+
+上面的图是一张来自OAuth2的抽象流程图
+
+Client:客户端应用程序(Application)
+
+Authorization Server:授权服务器
+
+Resource Server:资源服务器
+
+解释上图的大致流程:
+
+- 用户连接客户端应用程序后,客户端应用程序(Client)要求用户给予授权
+- 用户同意给予客户端应用程序授权
+- 客户端应用程序使用上一步获得的授权(Grant),向授权服务器申请令牌
+- 授权服务器对客户端应用程序的授权(Grant)进行验证后,确认无误,发放令牌
+- 客户端应用程序使用令牌,向资源服务器申请获取资源
+- 资源服务器确认令牌无误,同意向客户端应用程序开放资源
+
+其实流程无非如下,用户连接-->客户端-->客户端要求用户给出授权-->客户端拿授权申请令牌-->授权服务器校验授权无误后发放令牌-->客户端拿着令牌,找资源服务器要资源-->资源服务器校验令牌无误后发放资源
+
+从上面的流程可以看出,如何获取**授权(Grant)**才是关键。拥有正确的授权(Authorzation)就可以去拿到任意的东西了
+
+### OAuth2的4种授权类型
+
+#### Authorization Code(授权码模式)
+
+功能最完整、流程最严密的授权模式。通过第三方应用程序服务器与认证服务器进行互动。广泛用于各种第三方认证。
+
+ +----------+
+ | Resource |
+ | Owner |
+ | |
+ +----------+
+ ^
+ |
+ (B)
+ +----|-----+ Client Identifier +---------------+
+ | -+----(A)-- & Redirection URI ---->| |
+ | User- | | Authorization |
+ | Agent -+----(B)-- User authenticates --->| Server |
+ | | | |
+ | -+----(C)-- Authorization Code ---<| |
+ +-|----|---+ +---------------+
+ | | ^ v
+ (A) (C) | |
+ | | | |
+ ^ v | |
+ +---------+ | |
+ | |>---(D)-- Authorization Code ---------' |
+ | Client | & Redirection URI |
+ | | |
+ | |<---(E)----- Access Token -------------------'
+ +---------+ (w/ Optional Refresh Token)
+ Note: The lines illustrating steps (A), (B), and (C) are broken into
+ two parts as they pass through the user-agent.
+
+- 用户(Resource Owner)通过用户代理(User-Agent)访问客户端(Client),客户端索要授权,并将用户导向认证服务器(Authorization Server)
+- 用户选择是否给予客户端授权
+- 假设用户给予授权,认证服务器将用户导向客户端事先指定的**重定向URI**,同时附上一个授权码
+- 客户端收到授权码,附上早先的**重定向URI**,向认证服务器申请令牌。这一步是在客户端的后台服务器上完成的,对用户不可见
+- 认证服务器核对授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。这一步对用户也不可见
+
+#### Implicit(简化模式)
+
+不通过第三方应用程序服务器,直接在浏览器中向认证服务器申请令牌,更适用于移动端的App及没有服务器端的第三方单页面应用。
+
+##### Resource Owner Password(密码模式)
+
+用户向客户端服务器提供自己的用户名和密码,用户对客户端高度信任的情况下使用,比如公司、组织的内部系统,SSO
+
+ +----------+
+ | Resource |
+ | Owner |
+ | |
+ +----------+
+ v
+ | Resource Owner
+ (A) Password Credentials
+ |
+ v
+ +---------+ +---------------+
+ | |>--(B)---- Resource Owner ------->| |
+ | | Password Credentials | Authorization |
+ | Client | | Server |
+ | |<--(C)---- Access Token ---------<| |
+ | | (w/ Optional Refresh Token) | |
+ +---------+ +---------------+
+
+ Figure 5: Resource Owner Password Credentials Flow
+
+- 用户(Resource Owner资源持有者)向客户端(Client)提供用户名和密码
+- 客户端将用户名和密码发给认证服务器(Authorization Server),向后者请求令牌
+- 认证服务器确认无误后,向客户端提供访问令牌
+
+#### Client Credentials(客户端模式)
+
+客户端服务器以自己的名义,而不是以用户的名义,向认证服务器进行认证
+
+## 令牌刷新
+
+```
+ +--------+ +---------------+
+ | |--(A)------- Authorization Grant --------->| |
+ | | | |
+ | |<-(B)----------- Access Token -------------| |
+ | | & Refresh Token | |
+ | | | |
+ | | +----------+ | |
+ | |--(C)---- Access Token ---->| | | |
+ | | | | | |
+ | |<-(D)- Protected Resource --| Resource | | Authorization |
+ | Client | | Server | | Server |
+ | |--(E)---- Access Token ---->| | | |
+ | | | | | |
+ | |<-(F)- Invalid Token Error -| | | |
+ | | +----------+ | |
+ | | | |
+ | |--(G)----------- Refresh Token ----------->| |
+ | | | |
+ | |<-(H)----------- Access Token -------------| |
+ +--------+ & Optional Refresh Token +---------------+
+```
+
+- 客户端找授权服务器索要授权
+
+- 当用户同意给予授权后,授权服务器给予令牌,并给予刷新令牌
+
+- 此时通过令牌去资源服务器中获取资源
+
+- 得到资源
+
+ 假设token过期
+
+- 再次获取资源,发现Token无效了
+- 通过刷新令牌去授权服务器中获取Token
+- 通过Token再次获取令牌和刷新令牌,重复流程
+
diff --git a/public/markdowns/Vue.md b/public/markdowns/Vue.md
new file mode 100644
index 0000000..74b7656
--- /dev/null
+++ b/public/markdowns/Vue.md
@@ -0,0 +1,11821 @@
+---
+title: Vue2
+tags:
+ - Vue2
+categories:
+ - 前端
+description: Vue2
+abbrlink: 4d45ebbb
+---
+# Vue核心
+
+## 搭建Vue环境
+
+先在此处附上Vue的安装教程地址:https://v2.cn.vuejs.org/v2/guide/installation.html
+
+这里有两个版本,一个开发版本,一个生产版本
+
+开发版本是在开发时使用的,当出现问题的时候会在控制台报警告
+
+生产版本是在项目上线时使用的,不会有警告,而且体积更小
+
+
+
+在这里,我使用的是开发版本,学习一般使用开发版
+
+将开发版本下载后保存到本地,使用方法与jquery是一致的,使用来script引入
+
+### 直接用script引入
+
+创建一个文件夹,在里面创建一个html文件
+
+然后直接引入vue文件即可
+
+```html
+
+
+
+
+
+
+
+ Document
+
+
+
+
+
+
+
+
+```
+
+运行文件
+
+### 消除开发环境提示
+
+在console里查看
+
+
+
+第一个是说下载vue的开发者工具来达到一个更好的开发者体验
+
+第二个是说你正在运行开发环境,请你确信在生产环境不要这样做
+
+两个小提示,但是不影响,后面再解决
+
+如果成功引入了Vue,在console上写入Vue会输出其对应的函数
+
+
+
+解决第一个提示的方法是下载一个vue的开发者工具即可
+
+vue开发者工具的github链接如下:https://github.com/vuejs/devtools#vue-devtools
+
+找到下面这个地方,点击进入谷歌商店下载
+
+
+
+
+
+第二个提示需要在代码中对其进行配置
+
+```vue
+
+```
+
+## 模板语法
+
+Vue模板语法有2大类:
+
+1. 插值语法:
+
+ 功能:用于解析标签体内容
+
+ 写法:{{xxx}},xxx是js表达式,且可以直接读取到data中的所有属性
+
+2. 指令语法:
+
+ 功能:用于解析标签(包括:标签属性、标签体内容、绑定事件等)
+
+ 举例:v-bind:hreft="xxx"或简写为:href="xxx",xxx同样要写js表达式。且可以直接读取到data中的所有属性
+
+ 备注:Vue中有很多的指令,且形式都是:v-?????
+
+### 插值语法
+
+```html
+
+
+
+
+
+
+
+ Document
+
+
+
+
+
+ {{test}}
+
+
+
+
+
+
+```
+
+### 指令语法
+
+#### v-bind
+
+单向绑定数据
+
+```html
+
+
+
+
+
+```
+
+可以简写为`跳转到百度`
+
+```html
+
+
+
+
+
+```
+
+
+
+## 数据绑定
+
+v-bind:单向数据绑定
+
+v-model:双向数据绑定
+
+Vue中有2种数据绑定的方式:
+
+1. 单向绑定(v-bind):数据只能从data流向页面
+
+2. 双向绑定(v-model):数据不仅能从data流向页面,还可以从页面流向data
+
+ 备注:
+
+ 1. 双向绑定一般都应用在表单类元素上(如:input、select等)
+ 2. v-model:value 可以简写为v-model,因为v-model默认收集的就是value值
+
+
+
+- el有两种写法
+
+ 1. new Vue时配置el属性
+
+ ```vue
+ new Vue({
+ // el: '#box', 第一种写法
+ })
+ ```
+
+ 2. 先创建Vue实例,随后再通过vm.$mount('#root')指定el的值
+
+ `vm.$mount('#box')`
+
+- data有2种写法
+
+ 1. 对象式
+
+ ```html
+ new Vue({
+ // el: '#box', 第一种写法
+ })
+ ```
+
+ 2. 函数式
+
+ ```html
+ // data的第二种写法:函数式
+ data() {
+ return {
+ name: 'zhangsan'
+ }
+ }
+ ```
+
+- 一个重要的原则
+
+ - 由Vue管理的函数,一定不要写箭头函数,一旦写了箭头函数,this就不再是Vue实例了
+
+v-bind的简写方式::xxx=""
+
+v-model的简写方式:v-model=""
+
+```html
+单向数据绑定:
+双向数据绑定:
+```
+
+### 单向数据绑定
+
+下面这段代码是对其进行了一个单向数据绑定,可以在页面中进行测试
+
+```html
+
+
+ 单向数据绑定:
+
+
+
+
+```
+
+之前在网上下载的Vue开发者工具此时就可以使用了
+
+打开页面后单击F12,打开这个页面,在最后一栏找到Vue
+
+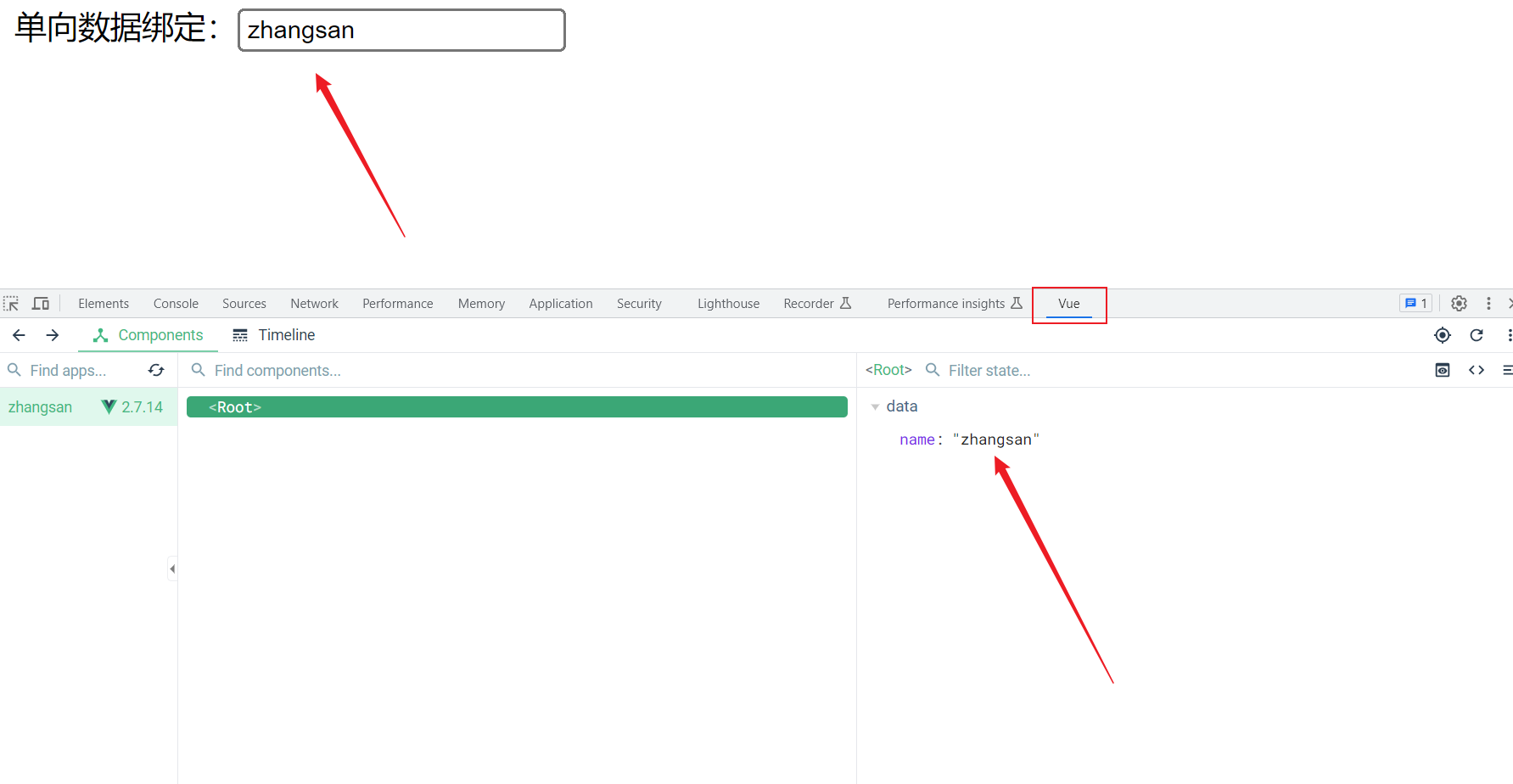 +
+在name:'zhangsan'的位置进行修改,单向数据绑定处的数据也会发生改变,而在输入框中修改,并不会改变name:'zhangsan'的内容
+
+### 双向数据绑定
+
+v-model:双向数据绑定
+
+```html
+
+
+
+在name:'zhangsan'的位置进行修改,单向数据绑定处的数据也会发生改变,而在输入框中修改,并不会改变name:'zhangsan'的内容
+
+### 双向数据绑定
+
+v-model:双向数据绑定
+
+```html
+
+
+ 单向数据绑定:
+ 双向数据绑定:
+
+
+
+
+```
+
+被绑定了双向后,在测试工具中输入任意的数据,输入框中的内容都会发生改变,或者在输入框中输入内容,也会互相的改变
+
+当输入框中的内容改变时,会带起一系列的连锁反应
+
+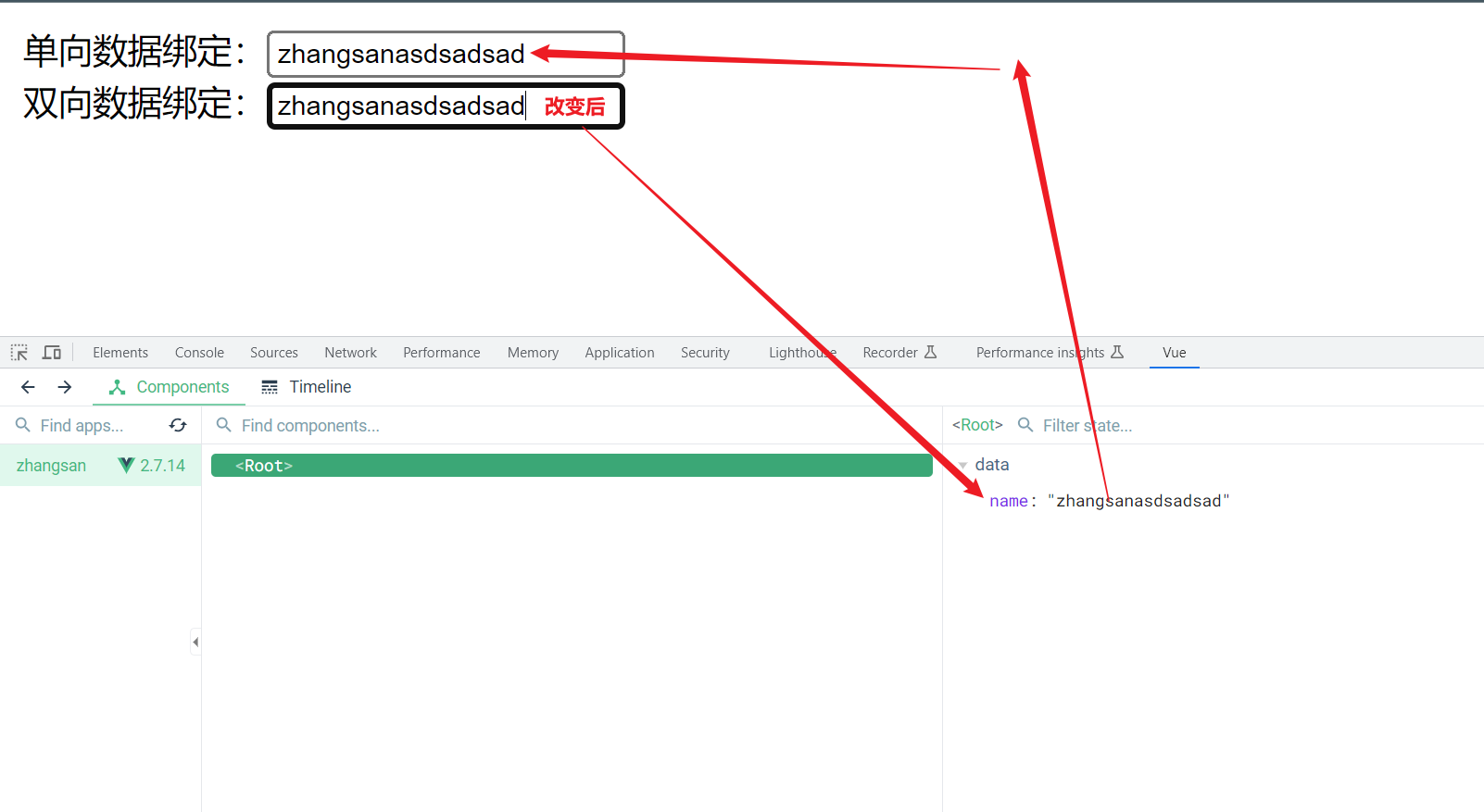 +
+**注意:v-model元素只能应用在表单类元素上(输入类元素),在其他标签类元素上使用会报错**
+
+## el与data的两种写法
+
+对象式
+
+```html
+
+
+
+**注意:v-model元素只能应用在表单类元素上(输入类元素),在其他标签类元素上使用会报错**
+
+## el与data的两种写法
+
+对象式
+
+```html
+
+
+ 单向数据绑定:
+ 双向数据绑定:
+
+
+
+
+```
+
+相较之下,第二种更灵活,使用的时候两种都可以
+
+```html
+
+
+ 单向数据绑定:
+ 双向数据绑定:
+
+
+
+
+```
+
+data可以简写为下面的方式
+
+```vue
+ // data的第二种写法:函数式
+ data() {
+ return {
+ name: 'zhangsan'
+ }
+ }
+```
+
+## MVVM
+
+M:模型(Model),对应data中的数据
+
+V:视图(View), 模板
+
+VM:视图模型(ViewModel),Vue实例对象
+
+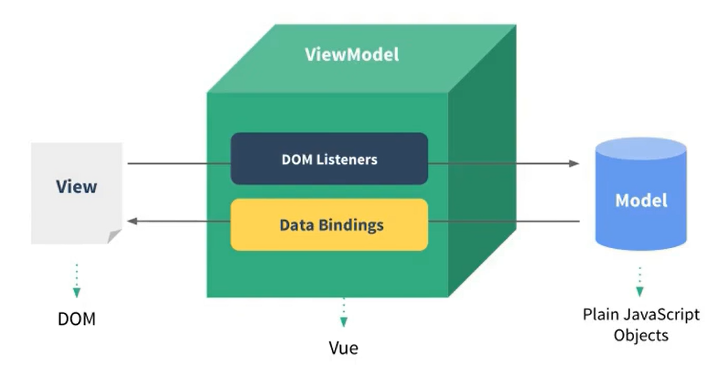 +
+Data Bindings:数据绑定,将Model中的数据绑定到View中
+
+DOM Listeners:页面模型监听器
+
+
+
+总结:
+
+- data中所有的属性,最后都出现了Vue对象上
+- vm身上所有的属性及Vue原型上所有属性,在Vue模板中都可以直接使用
+
+
+
+## 数据代理
+
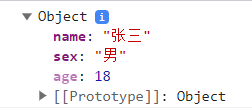
+### Object.defineProperty方法
+
+`Object.defineProperty(添加属性的对象名,添加的属性名,{value:添加的值})`
+
+```html
+
+
+
+
+```
+
+为person对象添加了一个age的属性,值为18
+
+
+
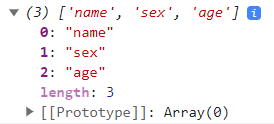
+这样添加与普通的添加方式有什么区别呢,这样添加的属性是不参与遍历的
+
+正常情况下是参与遍历的
+
+```html
+
+
+
+
+```
+
+
+
+但是使用该方法进行遍历就遍历不到了
+
+```html
+
+
+
+
+```
+
+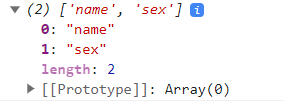
+
+这种情况也叫不可枚举,如果需要遍历该怎么办呢
+
+可以在代码中加入
+
+`enumerable: true`:控制属性是否可以被枚举,默认是false
+
+```html
+
+
+
+
+```
+
+再次运行,就可以遍历到了
+
+如果你试图修改`Object.defineProperty`添加的方法,可以修改,但不会修改成功
+
+如果需要被修改怎么办呢
+
+在代码中加入`writable: true`,控制属性是否可以被修改,默认是false
+
+```html
+
+
+
+
+```
+
+数据需要被删除,可以加入`configurable: true`,控制属性是否可以被删除,默认是false
+
+#### getter和setter
+
+下面的代码提供了`Object.defineProperty`的get和set示例
+
+```html
+
+
+
+
+```
+
+
+
+Data Bindings:数据绑定,将Model中的数据绑定到View中
+
+DOM Listeners:页面模型监听器
+
+
+
+总结:
+
+- data中所有的属性,最后都出现了Vue对象上
+- vm身上所有的属性及Vue原型上所有属性,在Vue模板中都可以直接使用
+
+
+
+## 数据代理
+
+### Object.defineProperty方法
+
+`Object.defineProperty(添加属性的对象名,添加的属性名,{value:添加的值})`
+
+```html
+
+
+
+
+```
+
+为person对象添加了一个age的属性,值为18
+
+
+
+这样添加与普通的添加方式有什么区别呢,这样添加的属性是不参与遍历的
+
+正常情况下是参与遍历的
+
+```html
+
+
+
+
+```
+
+
+
+但是使用该方法进行遍历就遍历不到了
+
+```html
+
+
+
+
+```
+
+
+
+这种情况也叫不可枚举,如果需要遍历该怎么办呢
+
+可以在代码中加入
+
+`enumerable: true`:控制属性是否可以被枚举,默认是false
+
+```html
+
+
+
+
+```
+
+再次运行,就可以遍历到了
+
+如果你试图修改`Object.defineProperty`添加的方法,可以修改,但不会修改成功
+
+如果需要被修改怎么办呢
+
+在代码中加入`writable: true`,控制属性是否可以被修改,默认是false
+
+```html
+
+
+
+
+```
+
+数据需要被删除,可以加入`configurable: true`,控制属性是否可以被删除,默认是false
+
+#### getter和setter
+
+下面的代码提供了`Object.defineProperty`的get和set示例
+
+```html
+
+
+
+
+```
+
+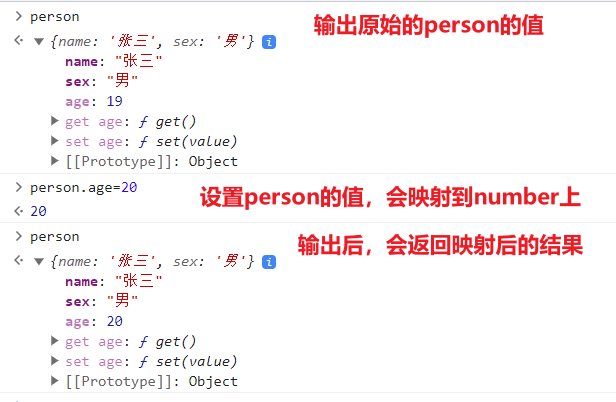 +
+
+
+### Vue中的数据代理
+
+数据代理就是让_data中的数据在Vue身上也有一份,不管是getter还是setter都可以直接通过属性名来获取使用,而不是通过 _data.属性名来使用,这样会非常的冗余,在getter时,数据代理会getter到 _data的身上,而setter时,会setter到 _data的身上,从而达到一个连锁的效果,简化了开发
+
+数据代理图示:
+
+
+
+
+
+### Vue中的数据代理
+
+数据代理就是让_data中的数据在Vue身上也有一份,不管是getter还是setter都可以直接通过属性名来获取使用,而不是通过 _data.属性名来使用,这样会非常的冗余,在getter时,数据代理会getter到 _data的身上,而setter时,会setter到 _data的身上,从而达到一个连锁的效果,简化了开发
+
+数据代理图示:
+
+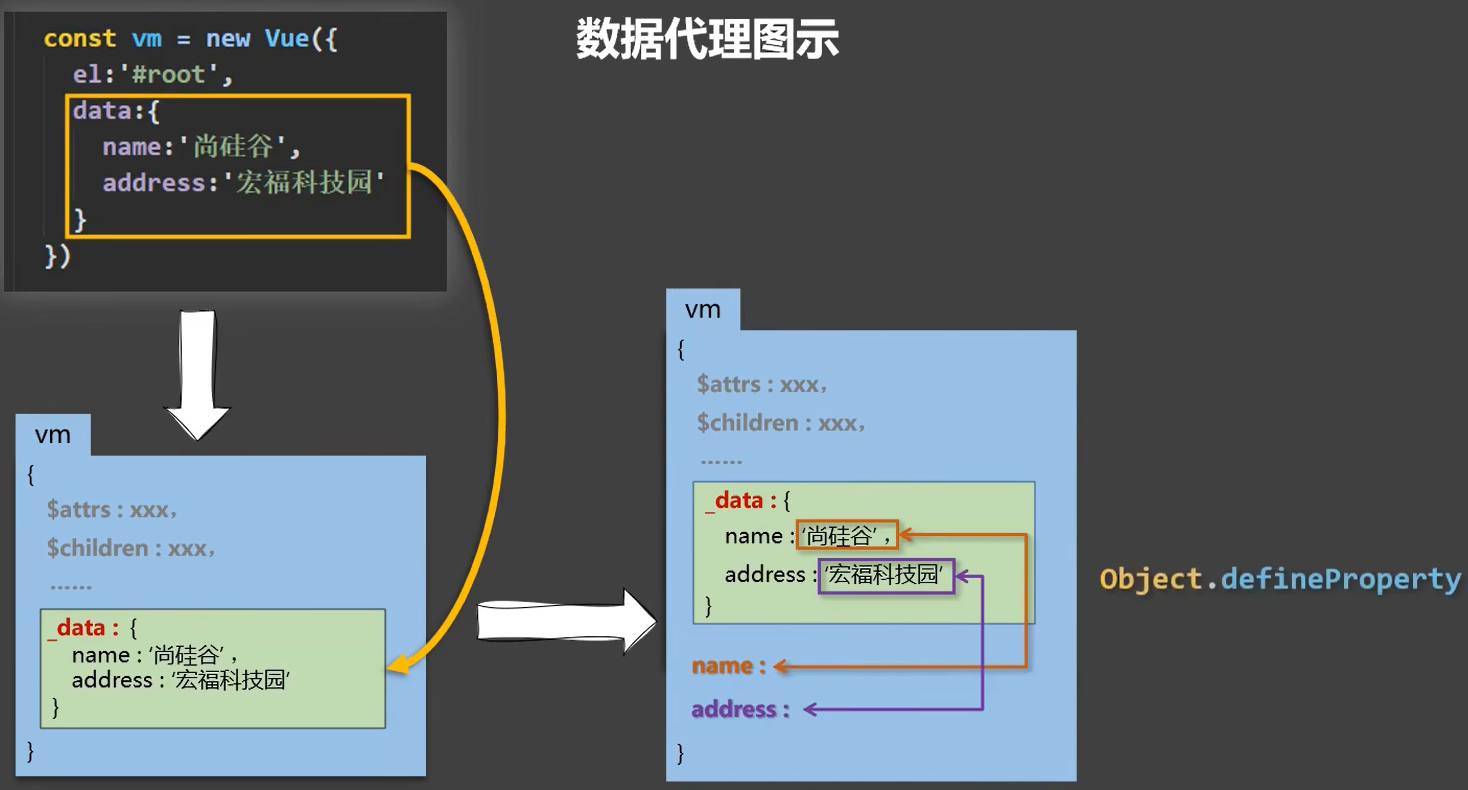 +
+Vue先将data中的数据存放到_data中,然后再通过`Object.defineProperty`方法将数据放到vm身上,这样就起到一个数据代理的效果
+
+```html
+
+
+
+Vue先将data中的数据存放到_data中,然后再通过`Object.defineProperty`方法将数据放到vm身上,这样就起到一个数据代理的效果
+
+```html
+
+
+
{{name}}
+ {{age}}
+
+
+
+
+```
+
+以上面这段示例代码为例,Vue中的数据代理其实也是同理的
+
+当有人访问页面中的name或age时,它会利用getter去访问data中的name或age
+
+当有人修改页面中的name或age时,它会利用setter去修改data中的name或age
+
+此时就不是直接访问,而是以一种代理的形式,通过访问Vue上的getter或setter方法来达到修改data上的数据
+
+
+
+这里对数据代理的两种形式做一个验证
+
+修改data中的属性后,查看其中vue中的data是否发生变化
+
+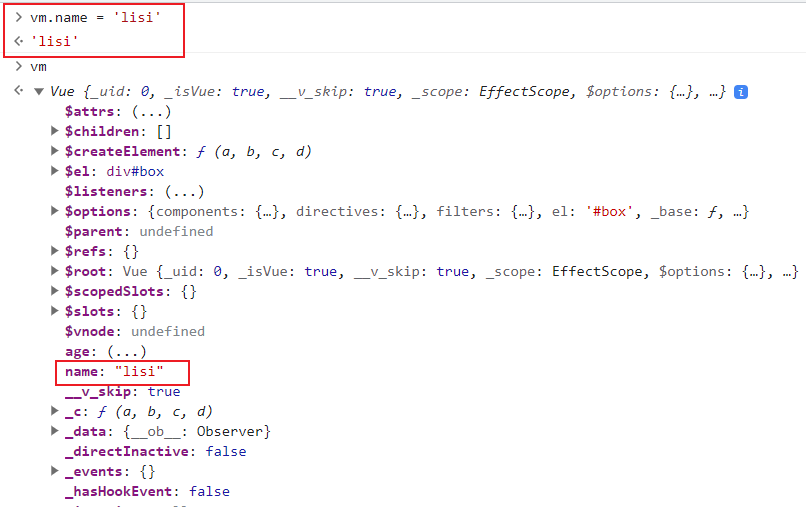 +
+发现此时这里的name确实是发生改变了,这说明数据改变后,依然是从data中来获取的
+
+
+
+对setter进行一个验证
+
+修改对应的属性,然后获取其data中的属性是否发生了改变
+
+
+
+这里我们发现,修改了它的属性后,data中的属性也发生了改变,这说明setter方法是存在数据代理的,设置完的属性会放到data中
+
+
+
+总结:
+
+1. Vue中的数据代理:
+
+ 通过vm对象来代理data对象中属性的操作(读/写)
+
+2. Vue中数据代理的好处:
+
+ 更加方便的操作data中的数据
+
+3. 基本原理
+
+ 通过Object.defineProperty()把data对象中所有属性添加到vm上
+
+ 通过每一个添加到vm上的属性,都指定一个getter/setter
+
+ 在getter/setter内部去操作(读/写)data中对应的属性
+
+
+
+## 事件处理
+
+### 事件的基本使用
+
+事件的基本使用:
+
+1. 使用v-on:xxx 或 @xxx绑定事件,其中xxx是事件名
+2. 事件的回调需要配置在methods对象中,最终会在vm上
+3. methods配置的函数,不要用箭头函数,否则this就不是vm了
+4. methods中配置的函数,都是被Vue所管理的函数,this的指向是vm或组件实例对象
+5. @click="demo" 和 @click="demo($event)" 效果一致,但后者可以传参
+
+#### v-on:click
+
+**简写形式为:@click**
+
+当被点击时
+
+```html
+
+
+
+发现此时这里的name确实是发生改变了,这说明数据改变后,依然是从data中来获取的
+
+
+
+对setter进行一个验证
+
+修改对应的属性,然后获取其data中的属性是否发生了改变
+
+
+
+这里我们发现,修改了它的属性后,data中的属性也发生了改变,这说明setter方法是存在数据代理的,设置完的属性会放到data中
+
+
+
+总结:
+
+1. Vue中的数据代理:
+
+ 通过vm对象来代理data对象中属性的操作(读/写)
+
+2. Vue中数据代理的好处:
+
+ 更加方便的操作data中的数据
+
+3. 基本原理
+
+ 通过Object.defineProperty()把data对象中所有属性添加到vm上
+
+ 通过每一个添加到vm上的属性,都指定一个getter/setter
+
+ 在getter/setter内部去操作(读/写)data中对应的属性
+
+
+
+## 事件处理
+
+### 事件的基本使用
+
+事件的基本使用:
+
+1. 使用v-on:xxx 或 @xxx绑定事件,其中xxx是事件名
+2. 事件的回调需要配置在methods对象中,最终会在vm上
+3. methods配置的函数,不要用箭头函数,否则this就不是vm了
+4. methods中配置的函数,都是被Vue所管理的函数,this的指向是vm或组件实例对象
+5. @click="demo" 和 @click="demo($event)" 效果一致,但后者可以传参
+
+#### v-on:click
+
+**简写形式为:@click**
+
+当被点击时
+
+```html
+
+
+
+
+
+
+
+```
+
+
+
+如果需要接收参数,可以这样写
+
+```html
+
+
+
+
+
+
+
+```
+
+但是这样写event就无法使用了
+
+可以通过在传参位置加入占位符`$event`的形式传递event参数
+
+```html
+
+
+
+
+
+
+
+```
+
+### 事件修饰符
+
+正常的运行下面这段代码,会在代码运行后依然将网页跳转到了百度
+
+```html
+
+
+
+
+
+```
+
+跳转是a标签的默认行为,我们有什么好的办法来阻止这个默认行为呢
+
+可以通过`e.preventDefault`方法对这个默认行为进行阻止
+
+```html
+methods: {
+
+ jump(e) {
+
+ e.preventDefault();
+
+ alert("跳走喽")
+
+ }
+
+ },
+```
+
+也可以通过Vue中的事件修饰符
+
+1. **prevent:阻止默认事件(常用)**
+2. **stop:阻止事件冒泡(常用)**
+3. **once:事件只触发一次(常用)**
+4. capture:使用事件的捕获模式
+5. self:只有event.target是当前操作的元素时才触发事件
+6. passive:事件的默认行为立即执行,无需等待事件回调执行完毕
+
+演示一下常用的三种,其余不做演示
+
+#### prevent:
+
+**效果和`e.preventDefault();`是一样的**
+
+```html
+
+
+
+
+
+```
+
+#### stop:
+
+冒泡是从当没有返回值true或false之类时,会从里向外(向它的父元素执行其父元素的方法直到结束)
+
+冒泡情况演示
+
+```html
+
+
+
+
+
+```
+
+冒泡解决方案:
+
+```html
+
+
+
+
+
+```
+
+冒泡解决方案Vue版:
+
+```html
+
+
+
+
+
+
+```
+
+#### once:
+
+事件只触发一次,字面意思,挺好理解的
+
+```html
+
+
+
+
+
+
+
+```
+
+
+
+### 键盘事件
+
+@keyup:当键盘弹起时
+
+@keydown:当键盘按下时
+
+下面这段代码是当键盘弹起时,如果按下的是回车就打印内容在控制台上
+
+```html
+
+
+
+
+
+
+
+```
+
+这里的判断keyCode也可以置换为vue中的别名
+
+```html
+
+
+
+
+
+
+
+```
+
+#### vue常见按键别名
+
+回车 => enter
+
+删除 => delete(捕获"删除"和"退格"键)
+
+退出 => esc
+
+空格 => space
+
+换行 => tab
+
+上 => up
+
+下 => down
+
+左 => left
+
+右 => right
+
+
+
+Vue未提供别名的按键,可以使用按键原始的key值去绑定,但注意要转为kebab-case(短横线命名)
+
+短横线命名是什么意思呢?
+
+就是说,如果某个按键未提供别名,可以使用原始的key去绑定,比如CapsLock,如果想要使用的话,需要转为caps-lock,记得要在两个单词之间加入短横线-
+
+示例代码
+
+```html
+
+
+
+
+
+
+
+```
+
+
+
+特殊按键tab:按了之后会离开焦点,这种不适合在keyup上使用,因为在键盘弹起后触发时,焦点已经离开了,方法可能就无法触发了(必须配合keydown使用)
+
+
+
+系统修饰键(用法特殊):ctrl、alt、shift、meta(win)
+
+1. 配合keyup使用:按下修饰键的同时,再按下其他键,随后释放其他键,事件才被触发
+2. 配合keydown使用:正常触发事件
+
+
+
+也可以使用keyCode去指定具体的按键(不推荐)
+
+``
+
+
+
+Vue.config.keyCodes.自定义键名 = 键码,可以定制按键别名
+
+`Vue.config.keyCodes.huiche = 13`
+
+```html
+
+
+
+
+
+
+
+```
+
+
+
+### 事件总结
+
+- 事件修饰符可以连着写,例如@click.prevent.stop="xxx",效果是停止默认事件并阻止冒泡,但它是有先后顺序的,也就是说,先停止默认事件,再阻止冒泡,谁写在前面谁先
+- 而键盘事件也可以连着写,例如,`@keyup.ctrl.y`,连着写之后的效果就是按下特定的这两位才会触发效果,其他的没效果
+
+
+
+## 计算属性
+
+### 姓名案例
+
+插值语法实现
+
+```html
+
+
+ 姓:
+ 名:
+ 姓名: {{firstName.slice(0,3)}}-{{lastName}}
+
+
+
+
+```
+
+如果我们想为名称加一些新的效果,但是会有很多,这样就会很麻烦,如果我们把它整理成一个methods,看起来就不会特别的冗余了
+
+```html
+
+
+ 姓:
+ 名:
+ 姓名: {{name()}}
+
+
+
+
+```
+
+### 计算属性
+
+1. 定义:要用的属性不存在,要通过**已有属性(vue中的才叫属性)**计算得来
+2. 原理:底层借助了Object.defineproperty方法提供的getter和setter
+3. get函数什么时候执行?
+ - 初次读取时会执行一次
+ - 当依赖的数据发生改变时会被再次调用
+4. 优势:与methods实现相比,内部有缓存机制(复用),效率更高,调试方便
+5. 备注:
+ 1. 计算属性最终会出现在vm上,直接读取使用即可
+ 2. 如果计算属性要被修改,那必须写set函数去响应修改,且set中要引起计算时**依赖的数据发生改变**,否则无效
+
+使用计算属性编写之前的姓名案例
+
+ 这里的get和`Object.defineProperty`是一样的
+
+当有人读取fullName时,get就会被调用,且返回值就作为fullName的值
+
+get什么时候调用
+
+- 初次读取fullName时
+- 所依赖的数据发生改变时
+
+```html
+
+
+ 姓:
+ 名:
+ 姓名: {{fullName}}
+
+
+
+
+```
+
+且get是有缓存的,而methods是没有缓存的,性能上computed更好一些
+
+有get肯定就有set,和get的道理其实也是一样的
+
+```html
+
+
+ 姓:
+ 名:
+ 姓名: {{fullName}}
+
+
+
+
+```
+
+### 计算属性简写
+
+简写的形式只有在**只读不改**的时候才能使用
+
+```html
+
+
+ 姓:
+ 名:
+ 姓名: {{fullName}}
+
+
+
+
+```
+
+
+
+## 监视属性
+
+### 天气案例
+
+先做一个天气的小案例,点击按钮后变换天气
+
+这里使用了计算属性来进行操作
+
+```html
+
+
+
今天天气很{{info}}
+
+
+
+
+
+```
+
+但是在这里有一个小坑
+
+如果我们将代码中的这一行改变了
+
+改变为`今天天气很一般
`
+
+此时页面上就不会用到isHot和info了,如果我们此时点击一下按钮,页面是肯定不会发生变化的,但是你打开开发者工具一看
+
+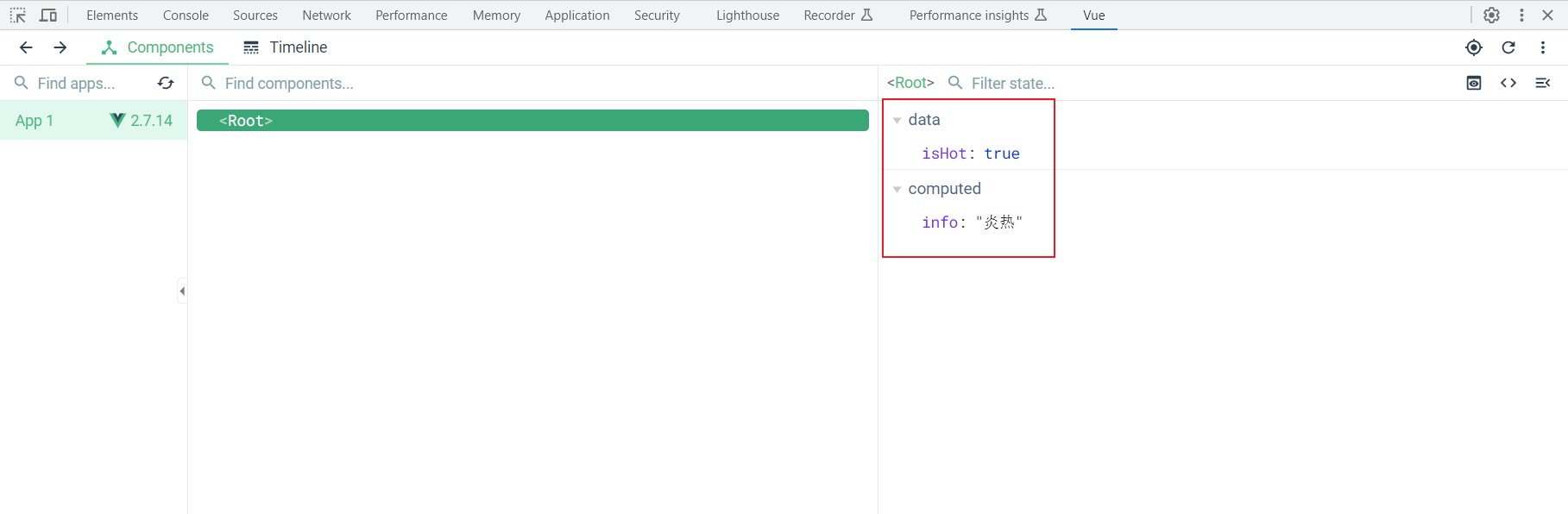 +
+开发者工具中却是true和炎热,我们去控制台上看一下
+
+
+
+开发者工具中却是true和炎热,我们去控制台上看一下
+
+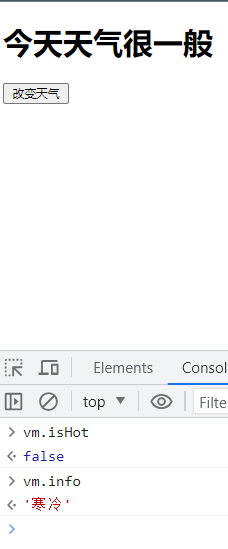 +
+控制台上就发生了变化了
+
+这是为什么呢,原因其实是vue的开发者工具认为你页面没有使用到该数据,就没有为你更新了,这个是官方的一个bug,不影响
+
+这里写的代码其实很多,只是为了实现一个切换功能,那还有什么办法能更简单吗
+
+```html
+
+
+
+控制台上就发生了变化了
+
+这是为什么呢,原因其实是vue的开发者工具认为你页面没有使用到该数据,就没有为你更新了,这个是官方的一个bug,不影响
+
+这里写的代码其实很多,只是为了实现一个切换功能,那还有什么办法能更简单吗
+
+```html
+
+
+
今天天气很{{info}}
+
+
+
+
+
+```
+
+一些简单的代码其实可以直接使用@click来写
+
+如果你不仅想做这个操作,还想做别的操作呢,有两种方式
+
+1. 直接在methods中写
+2. `@click="isHot = !isHot";你想做的操作`
+
+比如:
+
+```html
+
+
+
今天天气很{{info}}
+
+
+
+
+
+```
+
+
+
+### 监视属性watch
+
+1. 当被监视的属性变化时,回调函数自动调用,进行相关操作
+2. 监视的属性必须存在,才能进行监视
+3. 监视的两种写法:
+ 1. new Vue时传入watch配置
+ 2. 通过vm.$watch监视
+
+```html
+
+
+
今天天气很{{info}}
+
+
+
+
+
+```
+
+监视属性是watch,是一个对象的形式,里面可以放置多个对象,每个对象里面有配置属性和handler等
+
+handler中有两个参数可以接收,第一个是newValue,第二个是oldValue
+
+除了上面这种监视属性的写法,还有另一种监视属性的写法
+
+```html
+
+```
+
+
+
+### 深度监视
+
+1. Vue中的watch**默认不监测**对象内部值的改变(一层)
+2. 配置`deep:true`可以监测对象内部值的改变(多层)
+
+备注:
+
+- **Vue自身可以**监测对象内部值的改变,但Vue提供的watch**默认不可以**
+- 使用watch时根据数据的具体结构,决定是否采用深度监视,采用深度监视会有效率的问题
+
+#### 监视多级结构中某个属性的变化
+
+当多级结构中的a发生变化时,可以获取得到它
+
+```html
+
+
+
a的值是:{{numbers.a}}
+
+
+
+
+
+```
+
+#### 检测整体结构变化
+
+```html
+
+
+
a的值是:{{numbers.a}}
+
+
+
+
+
+
+
+
+```
+
+
+
+#### 检测整体结构的任意一个值的变化
+
+为watch中的属性配置deep即可检测值的变化
+
+```html
+
+
+
a的值是:{{numbers.a}}
+
+
+
+
+
+
+
+
+```
+
+
+
+### 监视的简写形式
+
+监视的简写形式只有在仅handler的情况下才可以使用
+
+```html
+
+
+
numbers的值是:{{numbers}}
+
+
+
+
+
+```
+
+但是监视有两种写法,它还有一种vm.$watch的写法,也可以简写
+
+```html
+
+
+
numbers的值是:{{numbers}}
+
+
+
+
+
+```
+
+
+
+### watch对比computed
+
+computed和watch之间的区别:
+
+1. computed能完成的功能,watch都可以完成
+2. watch能完成的功能,computed不一定能完成,例如:watch可以进行异步操作(定时器)
+
+两个重要的小原则:
+
+1. 被Vue所管理的函数,最好写成普通函数,这样this的指向才是vm或组件实例对象
+2. 所有不被Vue所管理的函数(定时器的回调函数、ajax的回调函数等),最好写成箭头函数,因为在JavaScript中,箭头函数并不会创建自己的this上下文,而是继承其所在代码块的this。因此,在Vue组件的方法中,如果我们使用了箭头函数,那么this才会指向Vue实例。
+
+watch写法的姓名案例
+
+```html
+
+
+ 姓:
+ 名:
+
姓名:{{fullName}}
+
+
+
+
+```
+
+computed写法的姓名案例
+
+```html
+
+
+ 姓:
+ 名:
+
姓名:{{fullName}}
+
+
+
+
+```
+
+
+
+## 绑定样式
+
+### 绑定class样式
+
+字符串写法,适用于:样式的类名不确定,需要动态指定
+
+可以将样式修改为指定的内容
+
+```html
+
+
+
+
+
+```
+
+也可以通过布尔值进行判断之类的情况
+
+当isActive为true时,active才会作为类生效
+
+```html
+
+
+
+
+
+```
+
+绑定计算属性作为class的判断
+
+```html
+
+
+
+
+
+```
+
+这段代码的释义是使用了一个计算属性
+
+计算属性的含义是classObject,当满足isActive为true并且error不为空的条件时,返回active;当error存在并且error的类型为fatal时返回text-danger
+
+### 数组语法
+
+我们可以把一个数组传给v-bind:class,来应用一个class列表的情况
+
+```html
+
+
+
+
+
+```
+
+最终它会渲染为`class='activeClass isYes'`
+
+如果想根据条件来切换数组语法中的内容,也是可以的
+
+```html
+test
+```
+
+可以通过三元表达式来对其进行修改
+
+如果觉得三元表达式不够友好,可以采取对象语法的方式
+
+```html
+test
+```
+
+
+
+### 绑定内联样式
+
+#### 对象语法
+
+```html
+
+
+
+
+
+```
+
+或者将样式绑定到一个对象中,直接使用对象
+
+```html
+hahahha
+```
+
+```js
+data: {
+ styleData: {
+ backgroundColor: 'red',
+ fontSize: '30px'
+ }
+ }
+```
+
+#### 数组语法
+
+将多个样式对象绑定到一个数组上
+
+```html
+hahahha
+```
+
+#### 多重值
+
+从vue2.3.0开始可以为style绑定中的property提供一个包含多个值的数组,常用于提供多个带前缀的值,例如:
+
+```html
+
+```
+
+`'-webkit-box,'-ms-flexbox','flex'`是不同浏览器支持的类型前缀,这样写只会渲染数组中最后一个被浏览器支持的值,如果浏览器支持不带浏览器前缀的flexbox,那么就只会渲染`display:flex`
+
+
+
+## 条件渲染
+
+### v-if、v-else
+
+`v-if` 指令用于条件性地渲染一块内容。这块内容只会在指令的表达式返回 true值的时候被渲染。
+
+`v-else`的效果是当if不生效时,else生效
+
+`v-else` 元素必须紧跟在带 `v-if` 或者 `v-else-if` 的元素的后面,否则它将不会被识别。
+
+```html
+
+
+
+
+
+```
+
+### 在``元素上使用v-if渲染分组
+
+因为`v-if`是一个指令,所以必须将它添加到一个元素上,但是如果想切换多个元素呢,此时可以把一个``元素当作不可见的包裹元素,并在上面使用`v-if`。最终的渲染结果不包含``元素
+
+```html
+
+
+
+
+ title
+ 1
+ 2
+
+
+
+
+
+
+```
+
+
+
+### v-else-if
+
+**2.1.0 新增**
+
+类似于 `v-else`,`v-else-if` 也必须紧跟在带 `v-if` 或者 `v-else-if` 的元素之后。
+
+```html
+
+
+
+ 成绩在90分及以上
+
+
+ 成绩在70分及以上
+
+
+ 成绩在50分及以上
+
+
+ 成绩在0分及以上
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+```
+
+那么在上面的代码中切换 `loginType` 将不会清除用户已经输入的内容。因为两个模板使用了相同的元素,`` 不会被替换掉——仅仅是替换了它的 `placeholder`。
+
+这样会起到复用input输入框的作用
+
+如果我们想让这两个元素是完全独立的,不要复用它们”。只需添加一个具有唯一值的 `key` attribute 即可:
+
+```html
+
+
+
+
+
+
+
+
+
+
+
+```
+
+` +
+# Axure9的基础功能
+
+## 菜单栏
+
+
+
+建议将备份设置为5分钟
+
+点击左上角文件菜单栏->自动备份设置,来进行设置
+
+偏好设置:可以对Axure的默认显示页面及辅助线、显示样式等进行设置;
+
+
+
+Axure中,总共有4种类型的文件;
+
+- .rp:原型文件
+- .rplib:元件库文件
+- .rpteam:团队项目文件
+ - 我们可以在左上角菜单栏中找到团队,进行团队项目的发布和分享
+- .html:网页文件
+
+
+
+备份设置:建议自动备份间隔5分钟;
+
+可以在视图中,对快速功能区进行自定义;
+
+发布模块,可以对预览选项进行编辑;
+
+
+
+如果想修改画布的尺寸可以在右侧样式->页面尺寸中进行调整
+
+如果不小心对页面中的一些窗口拖动,拖没了或拖错了,可以通过左侧菜单栏中的视图->重置视图来进行视图的重置
+
+
+
+如果想让多个形状或图片水平居中对齐,先选中对应的形状,再依次点击上方的中部和水平即可
+
+
+
+
+
+如果我们想看之前已经做好的内容,可以在菜单栏中找到发布->预览,进行查看
+
+## 工具栏
+
+在插入中可以进行形状的插入,如果我们想画一个正圆,可以通过按住shift再拖动即可
+
+
+
+在预览中,可以体验自己编写好的交互
+
+## 母版
+
+
+
+# Axure9的基础功能
+
+## 菜单栏
+
+
+
+建议将备份设置为5分钟
+
+点击左上角文件菜单栏->自动备份设置,来进行设置
+
+偏好设置:可以对Axure的默认显示页面及辅助线、显示样式等进行设置;
+
+
+
+Axure中,总共有4种类型的文件;
+
+- .rp:原型文件
+- .rplib:元件库文件
+- .rpteam:团队项目文件
+ - 我们可以在左上角菜单栏中找到团队,进行团队项目的发布和分享
+- .html:网页文件
+
+
+
+备份设置:建议自动备份间隔5分钟;
+
+可以在视图中,对快速功能区进行自定义;
+
+发布模块,可以对预览选项进行编辑;
+
+
+
+如果想修改画布的尺寸可以在右侧样式->页面尺寸中进行调整
+
+如果不小心对页面中的一些窗口拖动,拖没了或拖错了,可以通过左侧菜单栏中的视图->重置视图来进行视图的重置
+
+
+
+如果想让多个形状或图片水平居中对齐,先选中对应的形状,再依次点击上方的中部和水平即可
+
+
+
+
+
+如果我们想看之前已经做好的内容,可以在菜单栏中找到发布->预览,进行查看
+
+## 工具栏
+
+在插入中可以进行形状的插入,如果我们想画一个正圆,可以通过按住shift再拖动即可
+
+
+
+在预览中,可以体验自己编写好的交互
+
+## 母版
+
+ +
+## 样式面板
+
+
+
+## 快捷键
+
+
+
+# 元件
+
+
+
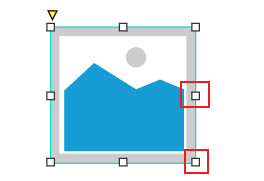
+如果想让放入到图片组件中的图片与图片组件一样大,令图片组件旁边的小按钮变为白色即可
+
+
+
+如果小按钮是黄色,此时图片则为原来的大小
+
+
+
+在使用文本标签时,如果小按钮为黄色,输入字体后不会自动换行,当小按钮为白色,则会自动换行
+
+
+
+
+
+# 热区、动态面板
+
+Axure中的热区可以让某个元件的触发范围变大,在热区中对触发条件进行添加即可
+
+
+
+动态面板:
+
+直接拖出动态面板后,双击动态面板,就能进入到对应的效果页面
+
+如图所示:
+
+
+
+## 样式面板
+
+
+
+## 快捷键
+
+
+
+# 元件
+
+
+
+如果想让放入到图片组件中的图片与图片组件一样大,令图片组件旁边的小按钮变为白色即可
+
+
+
+如果小按钮是黄色,此时图片则为原来的大小
+
+
+
+在使用文本标签时,如果小按钮为黄色,输入字体后不会自动换行,当小按钮为白色,则会自动换行
+
+
+
+
+
+# 热区、动态面板
+
+Axure中的热区可以让某个元件的触发范围变大,在热区中对触发条件进行添加即可
+
+
+
+动态面板:
+
+直接拖出动态面板后,双击动态面板,就能进入到对应的效果页面
+
+如图所示:
+
+ +
+上方有一个状态栏,每个状态都代表了不同的动态面板,我们对当前state1的面板画一个圆,然后修改状态
+
+
+
+上方有一个状态栏,每个状态都代表了不同的动态面板,我们对当前state1的面板画一个圆,然后修改状态
+
+ +
+切换状态后,圆不见了
+
+# 内联框架、中继器
+
+拖出内联框架,双击后,可以链接到网页或当前原型中的页面
+
+如果链接到网页中,点击预览后,对应的页面会缩小到内联框架对应的大小内
+
+
+
+中继器的使用方式,双击后会有一个单独像单个值一样的边框,修改该内容,在关闭中继器后外部的多个中继器都会被修改
+
+# 表单元件
+
+
+
+切换状态后,圆不见了
+
+# 内联框架、中继器
+
+拖出内联框架,双击后,可以链接到网页或当前原型中的页面
+
+如果链接到网页中,点击预览后,对应的页面会缩小到内联框架对应的大小内
+
+
+
+中继器的使用方式,双击后会有一个单独像单个值一样的边框,修改该内容,在关闭中继器后外部的多个中继器都会被修改
+
+# 表单元件
+
+ +
+在文本框中,可以编写一些对应的操作内容
+
+
+
+在文本框中,可以编写一些对应的操作内容
+
+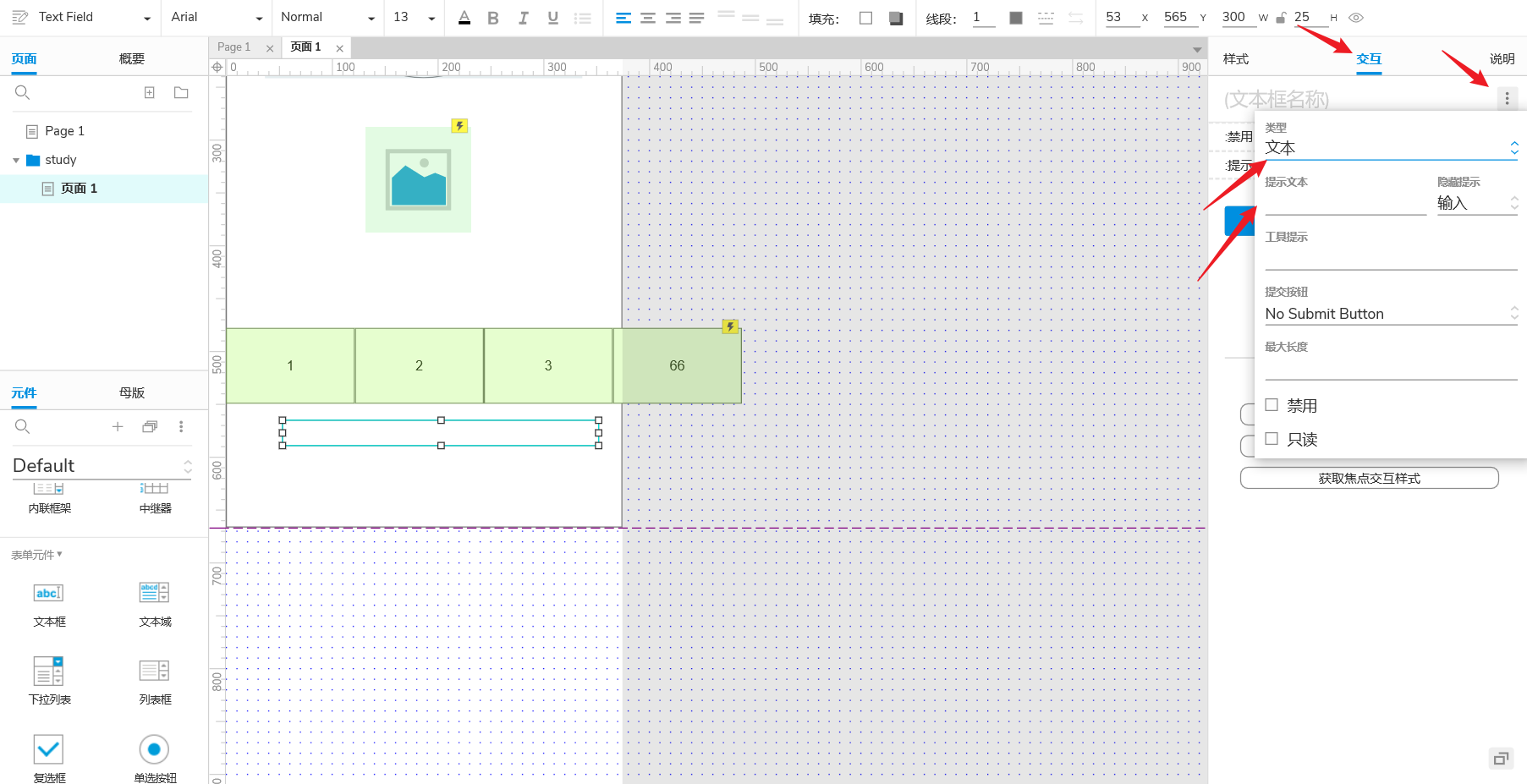 +
+在多选框中,如果我们想默认勾选上第一项的内容,可以这样操作
+
+勾选上你想默认的那一项即可
+
+
+
+在多选框中,如果我们想默认勾选上第一项的内容,可以这样操作
+
+勾选上你想默认的那一项即可
+
+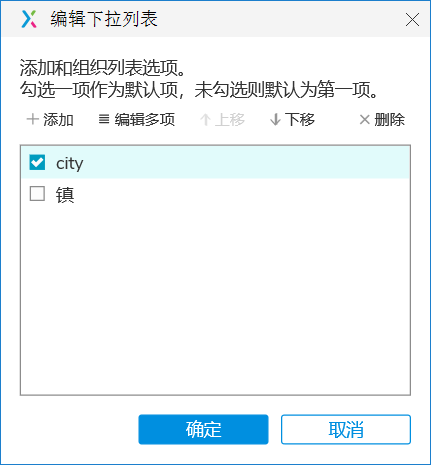 +
+单选按钮需要注意的是,需要提前为它设定组,才能起到单选按钮的效果
+
+选中对应的按钮
+
+
+
+单选按钮需要注意的是,需要提前为它设定组,才能起到单选按钮的效果
+
+选中对应的按钮
+
+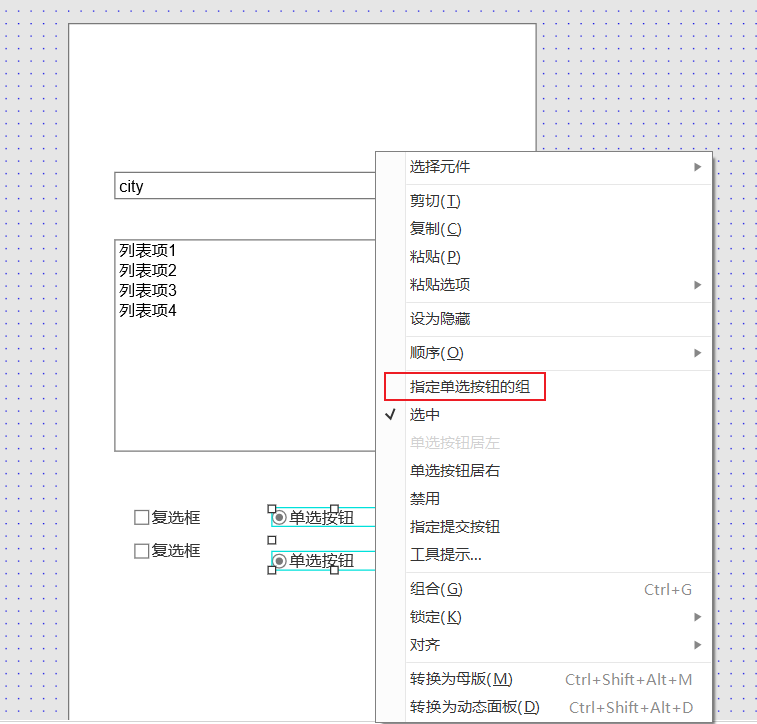 +
+# 菜单表格
+
+没啥难度,正常使用即可
+
+
+
+# 菜单表格
+
+没啥难度,正常使用即可
+
+ +
+# 标记元件
+
+快照使用较少,其他正常使用即可
+
+# 事件
+
+## 常用的交互设计
+
+
+
+# 标记元件
+
+快照使用较少,其他正常使用即可
+
+# 事件
+
+## 常用的交互设计
+
+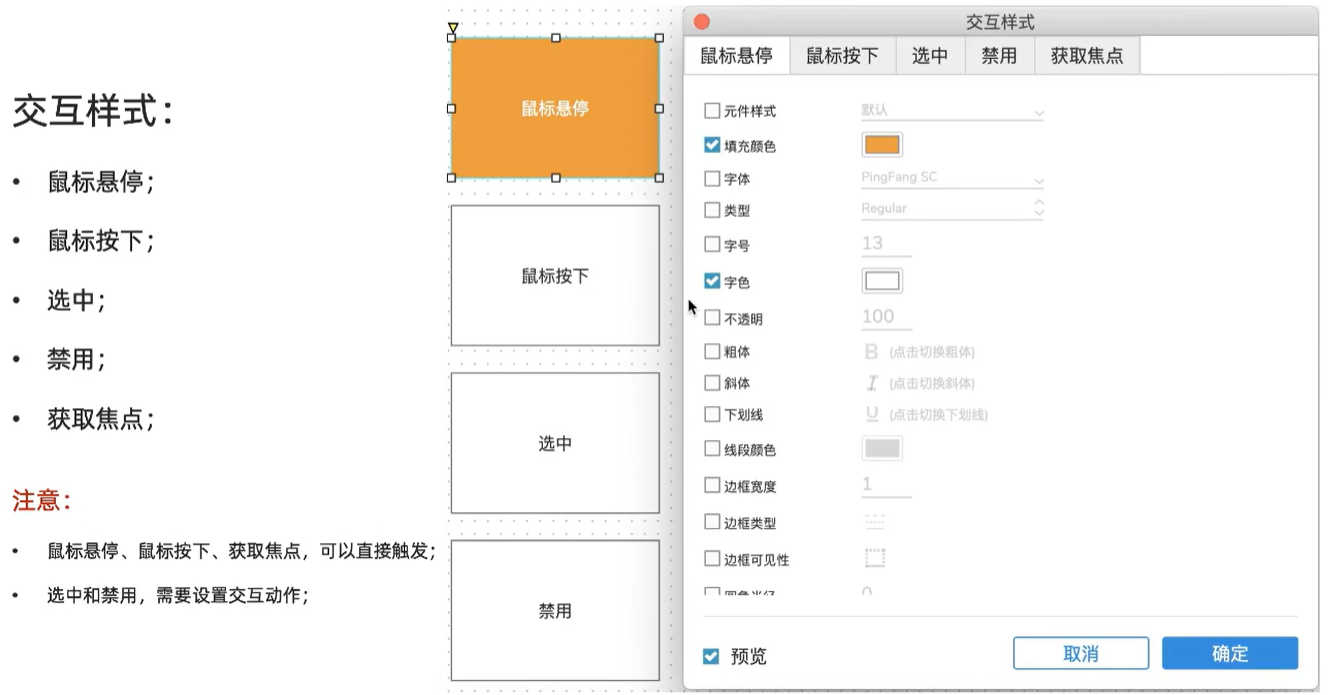 +
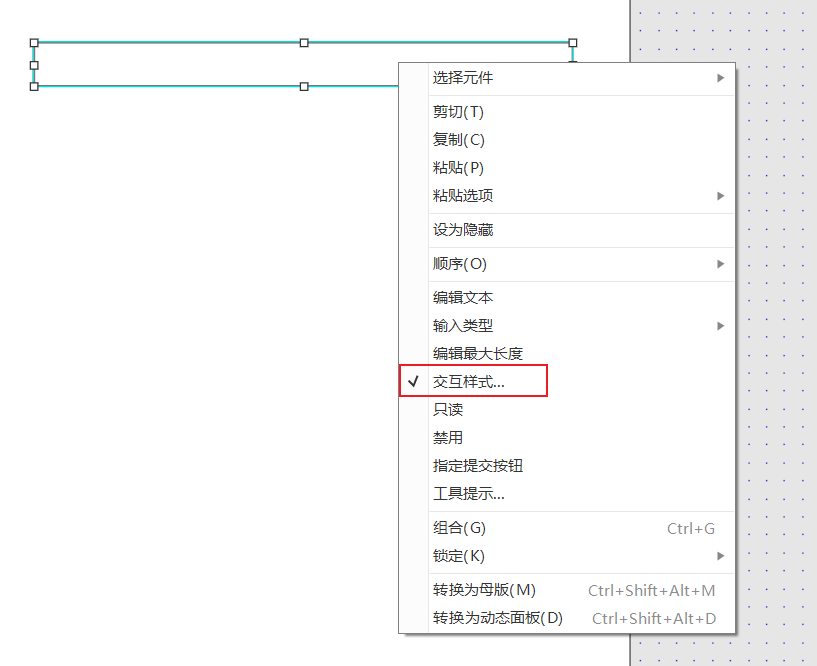
+对元件选中后添加交互样式
+
+
+
+对元件选中后添加交互样式
+
+ +
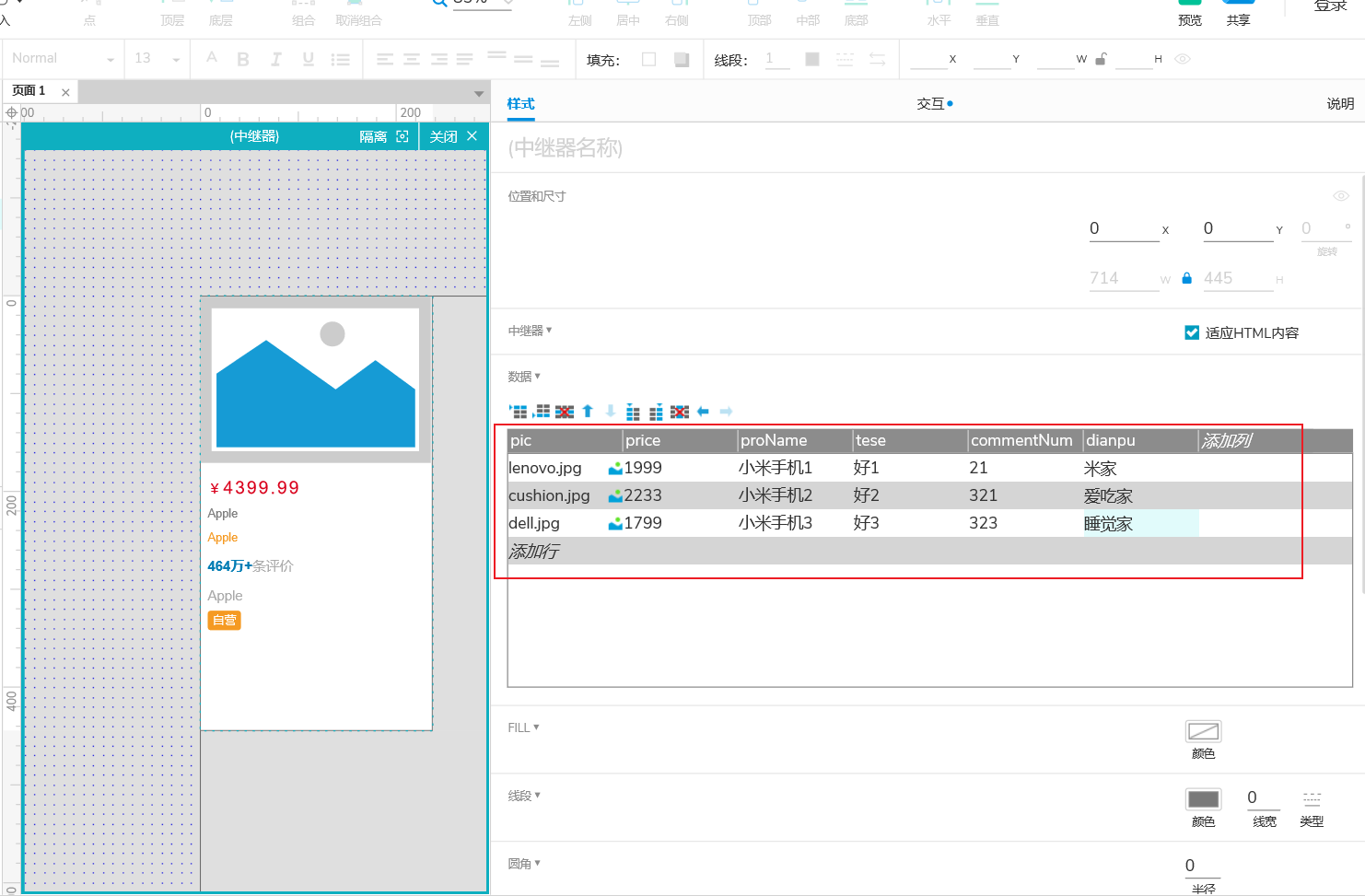
+# 中继器
+
+- 载入时
+- 每项加载时
+- 列表项尺寸改变
+
+当我们想写一个商品列表时,就可以用到中继器
+
+先编写好中继器的模板,接着编辑对应的数据
+
+
+
+# 中继器
+
+- 载入时
+- 每项加载时
+- 列表项尺寸改变
+
+当我们想写一个商品列表时,就可以用到中继器
+
+先编写好中继器的模板,接着编辑对应的数据
+
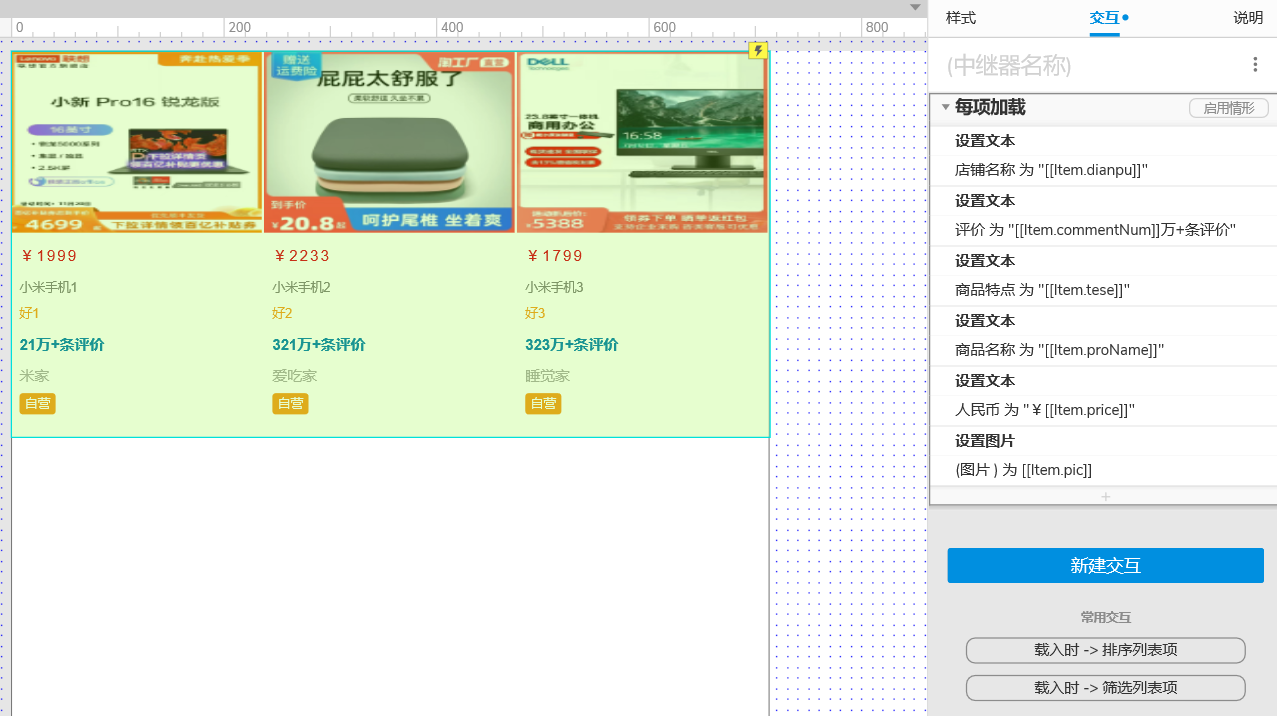
+ +
+需要通过交互事件来获取中继器中写好的数据
+
+
+
+需要通过交互事件来获取中继器中写好的数据
+
+ +
+此时如果我们写了四行,那么第四个就会超出这个掉在边框外面,如果你想有规律的放置每一行的项数,在样式->布局->网格分布, 然后填写每行项数量即可
+
diff --git a/public/markdowns/Docker.md b/public/markdowns/Docker.md
new file mode 100644
index 0000000..ef1e44a
--- /dev/null
+++ b/public/markdowns/Docker.md
@@ -0,0 +1,1000 @@
+---
+title: Docker
+abbrlink: f5f9fa9b
+date: 2023-11-07 13:38:38
+tags:
+ - Docker
+ - MQ
+categories:
+ - 微服务
+description: Docker快速入门教程
+---
+
+# Docker的安装
+
+## 删除Docker
+
+在安装Docker之前需要先进行Docker的删除,防止本地存在Docker导致冲突
+
+```bash
+yum remove docker \
+ docker-client \
+ docker-client-latest \
+ docker-common \
+ docker-latest \
+ docker-latest-logrotate \
+ docker-logrotate \
+ docker-engine
+```
+
+## 配置Docker的yum库
+
+首先要安装一个yum工具
+
+```bash
+yum install -y yum-utils
+```
+
+安装成功后,执行命令,配置Docker的yum源:
+
+```Bash
+yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
+```
+
+## 安装Docker
+
+执行命令,安装Docker
+
+```Bash
+yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
+```
+
+安装完成后,输入命令`docker -v`可以查看docker的版本
+
+## 启动和校验
+
+这里可以设置docker为开机自启
+
+然后启动docker,并输入`docker images`或者`docker ps`查看是否有效,如果有效就说明启动成功了
+
+```Bash
+# 启动Docker
+systemctl start docker
+
+# 停止Docker
+systemctl stop docker
+
+# 重启
+systemctl restart docker
+
+# 设置开机自启
+systemctl enable docker
+
+# 执行docker ps命令,如果不报错,说明安装启动成功
+docker ps
+```
+
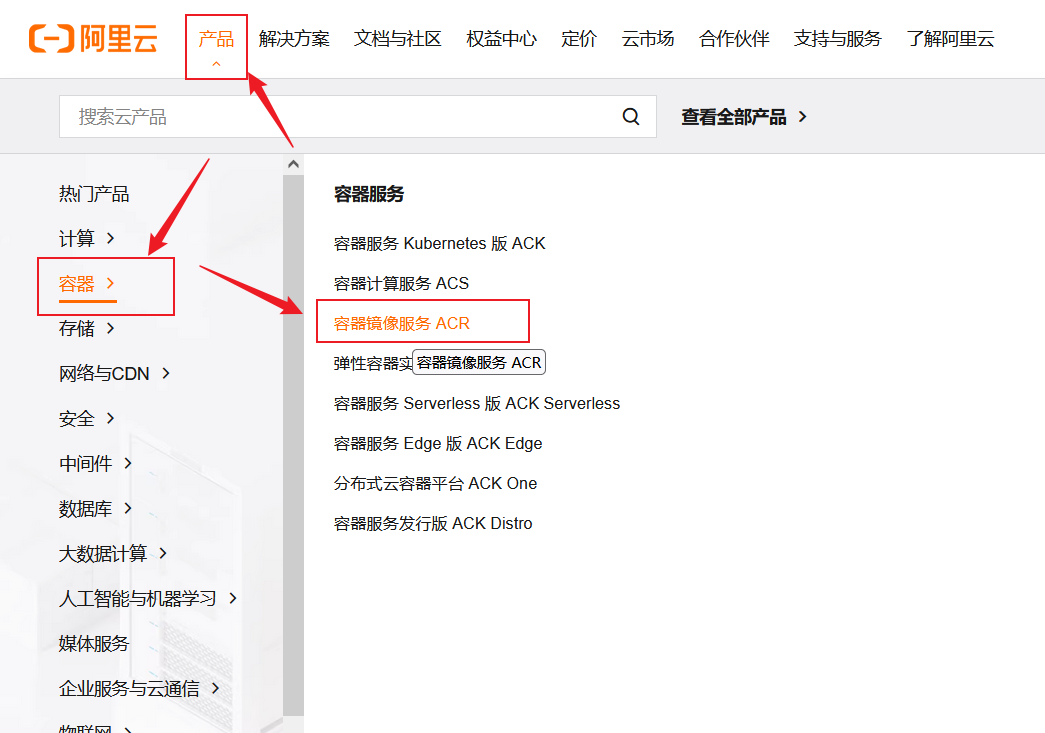
+## 配置镜像加速
+
+这里配置阿里的镜像加速
+
+注册阿里云账号https://www.aliyun.com/
+
+
+
+此时如果我们写了四行,那么第四个就会超出这个掉在边框外面,如果你想有规律的放置每一行的项数,在样式->布局->网格分布, 然后填写每行项数量即可
+
diff --git a/public/markdowns/Docker.md b/public/markdowns/Docker.md
new file mode 100644
index 0000000..ef1e44a
--- /dev/null
+++ b/public/markdowns/Docker.md
@@ -0,0 +1,1000 @@
+---
+title: Docker
+abbrlink: f5f9fa9b
+date: 2023-11-07 13:38:38
+tags:
+ - Docker
+ - MQ
+categories:
+ - 微服务
+description: Docker快速入门教程
+---
+
+# Docker的安装
+
+## 删除Docker
+
+在安装Docker之前需要先进行Docker的删除,防止本地存在Docker导致冲突
+
+```bash
+yum remove docker \
+ docker-client \
+ docker-client-latest \
+ docker-common \
+ docker-latest \
+ docker-latest-logrotate \
+ docker-logrotate \
+ docker-engine
+```
+
+## 配置Docker的yum库
+
+首先要安装一个yum工具
+
+```bash
+yum install -y yum-utils
+```
+
+安装成功后,执行命令,配置Docker的yum源:
+
+```Bash
+yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
+```
+
+## 安装Docker
+
+执行命令,安装Docker
+
+```Bash
+yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
+```
+
+安装完成后,输入命令`docker -v`可以查看docker的版本
+
+## 启动和校验
+
+这里可以设置docker为开机自启
+
+然后启动docker,并输入`docker images`或者`docker ps`查看是否有效,如果有效就说明启动成功了
+
+```Bash
+# 启动Docker
+systemctl start docker
+
+# 停止Docker
+systemctl stop docker
+
+# 重启
+systemctl restart docker
+
+# 设置开机自启
+systemctl enable docker
+
+# 执行docker ps命令,如果不报错,说明安装启动成功
+docker ps
+```
+
+## 配置镜像加速
+
+这里配置阿里的镜像加速
+
+注册阿里云账号https://www.aliyun.com/
+
+ +
+
+
+具体命令如下:
+
+```Bash
+# 创建目录
+mkdir -p /etc/docker
+
+# 复制内容,注意把其中的镜像加速地址改成你自己的
+tee /etc/docker/daemon.json <<-'EOF'
+{
+ "registry-mirrors": ["https://xxxx.mirror.aliyuncs.com"]
+}
+EOF
+
+# 重新加载配置
+systemctl daemon-reload
+
+# 重启Docker
+systemctl restart docker
+```
+
+# 部署MySQL
+
+部署MySQL只需要一条指令
+
+```bash
+docker run -d \
+ --name mysql \
+ -p 3306:3306 \
+ -e TZ=Asia/Shanghai \
+ -e MYSQL_ROOT_PASSWORD=123 \
+ mysql
+```
+
+接着你可以打开你使用的sql工具,来连接docker刚刚部署的mysql,连接成功说明,部署成功了
+
+## 镜像和容器
+
+当我们利用Docker安装应用时,Docker会自动搜索并下载应用**镜像(image)**。镜像不仅包含应用本身,还包含应用运行所需要的环境、配置、系统函数库。Docker会在运行镜像时创建一个隔离环境。称为**容器(container)**。
+
+**镜像仓库**:存储和管理镜像的平台,Docker官方维护了一个公共仓库:Docker Hub。
+
+在我们启动Docker的服务器后,docker daemon守护进程会对docker命令进行监听,当我们运行docker xxx的命令后,守护进程就会去查看本地是否存在镜像,存在就直接使用,否则就回去镜像仓库进行下载,下载完成后作为容器来使用
+
+## 命令解读
+
+```bash
+docker run -d \
+ --name mysql \
+ -p 3306:3306 \
+ -e TZ=Asia/Shanghai \
+ -e MYSQL_ROOT_PASSWORD=123 \
+ mysql
+```
+
+- `docker run -d` :创建并运行一个容器,`-d`则是让容器以后台进程运行
+- `--name mysql ` : 给容器起个名字叫`mysql`,你可以叫别的
+- `-p 3306:3306` : 设置端口映射。
+ - **容器是隔离环境**,外界不可访问。但是可以将宿主机端口映射容器内到端口,当访问宿主机指定端口时,就是在访问容器内的端口了。
+ - 容器内端口往往是由容器内的进程决定,例如MySQL进程默认端口是3306,因此容器内端口一定是3306;而宿主机端口则可以任意指定,一般与容器内保持一致。
+ - 格式: `-p 宿主机端口:容器内端口`,示例中就是将宿主机的3306映射到容器内的3306端口
+- `-e TZ=Asia/Shanghai` : 配置容器内进程运行时的一些参数
+ - 格式:`-e KEY=VALUE`,KEY和VALUE都由容器内进程决定
+ - 案例中,`TZ=Asia/Shanghai`是设置时区;`MYSQL_ROOT_PASSWORD=123`是设置MySQL默认密码
+- `mysql`:设置**镜像**名称,Docker会根据这个名字搜索并下载镜像
+ - 格式:`REPOSITORY:TAG`,例如`mysql:8.0`,其中`REPOSITORY`可以理解为镜像名,`TAG`是版本号
+ - 在未指定`TAG`的情况下,默认是最新版本,也就是`mysql:latest`
+
+### 镜像命名规范
+
+- 镜像名称一般分两部分组成:[repository]:[tag]
+ - 其中repository就是镜像名
+ - tag是镜像的版本
+- 在没有指定tag时,默认是latest(最新),代表最新版本的镜像
+
+# Docker基础
+
+Docker最常见的命令就是操作镜像、容器的命令,详见官方文档:https://docs.docker.com/
+
+Docker常见命令,可以参考官方文档:https://docs.docker.com/engine/reference/commandline/cli/
+
+比较常见的命令有:
+
+| **命令** | **说明** | **文档地址** |
+| :------------- | :----------------------------- | :----------------------------------------------------------- |
+| docker pull | 拉取镜像 | [docker pull](https://docs.docker.com/engine/reference/commandline/pull/) |
+| docker push | 推送镜像到DockerRegistry | [docker push](https://docs.docker.com/engine/reference/commandline/push/) |
+| docker images | 查看本地镜像 | [docker images](https://docs.docker.com/engine/reference/commandline/images/) |
+| docker rmi | 删除本地镜像 | [docker rmi](https://docs.docker.com/engine/reference/commandline/rmi/) |
+| docker run | 创建并运行容器(不能重复创建) | [docker run](https://docs.docker.com/engine/reference/commandline/run/) |
+| docker stop | 停止指定容器 | [docker stop](https://docs.docker.com/engine/reference/commandline/stop/) |
+| docker start | 启动指定容器 | [docker start](https://docs.docker.com/engine/reference/commandline/start/) |
+| docker restart | 重新启动容器 | [docker restart](https://docs.docker.com/engine/reference/commandline/restart/) |
+| docker rm | 删除指定容器 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/rm/) |
+| docker ps | 查看容器 | [docker ps](https://docs.docker.com/engine/reference/commandline/ps/) |
+| docker logs | 查看容器运行日志 | [docker logs](https://docs.docker.com/engine/reference/commandline/logs/) |
+| docker exec | 进入容器 | [docker exec](https://docs.docker.com/engine/reference/commandline/exec/) |
+| docker save | 保存镜像到本地压缩文件 | [docker save](https://docs.docker.com/engine/reference/commandline/save/) |
+| docker load | 加载本地压缩文件到镜像 | [docker load](https://docs.docker.com/engine/reference/commandline/load/) |
+| docker inspect | 查看容器详细信息 | [docker inspect](https://docs.docker.com/engine/reference/commandline/inspect/) |
+
+## 保存镜像到本地压缩文件
+
+```bash
+docker save -o 镜像名称.tar 镜像名称:版本
+```
+
+## 删除镜像
+
+删除镜像时如果遇到以下报错:Error response from daemon: conflict: unable to remove repository reference "mysql:latest" (must force) - container 0fa37bf7c610 is using its referenced image 3218b38490ce
+
+报错内容是因为镜像被容器引用,那么删除容器再删除镜像。
+
+此时使用`docker rm 0fa37bf7c610 `
+
+再次执行即可
+
+```bash
+docker rmi 镜像名:版本
+```
+
+## 加载已有镜像
+
+-p:不输出任何内容
+
+```
+docker load -i 读取的镜像名称 -p
+```
+
+## 创建并运行容器
+
+docker run
+
+-d:后台运行
+
+--name:容器名称
+
+-p:端口号,分为宿主机端口:容器内端口
+
+-e:相关配置
+
+最后是设置镜像名称
+
+```bash
+docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123 mysql
+```
+
+## 停止容器运行
+
+```bash
+docker stop 容器名
+```
+
+## 查看容器是否运行
+
+```bash
+docker ps
+```
+
+查看所有容器,包括没有运行的容器
+
+```bash
+docker ps -a
+```
+
+## 启动容器
+
+```bash
+docker start 容器名
+```
+
+## 查看容器日志
+
+```bash
+docker logs 容器名
+```
+
+### 持续查看容器日志
+
+```bash
+docker logs -f 容器名
+```
+
+## 进入容器内部
+
+-it:添加一个可输入的终端
+
+bash:命令行交互
+
+```bash
+docker exec -it 容器名 bash
+# 退出
+exit
+```
+
+## 删除容器
+
+删除容器需要先停止容器再删除
+
+```bash
+docker stop 被删除的容器名
+```
+
+```bash
+docker rm 容器名
+```
+
+也可以强制删除docker
+
+```bash
+docker rm 容器名 -f
+```
+
+## 命令别名
+
+```bash
+# 修改/root/.bashrc文件
+vi /root/.bashrc
+内容如下:
+# .bashrc
+
+# User specific aliases and functions
+
+alias rm='rm -i'
+alias cp='cp -i'
+alias mv='mv -i'
+alias dps='docker ps --format "table {{.ID}}\t{{.Image}}\t{{.Ports}}\t{{.Status}}\t{{.Names}}"'
+alias dis='docker images'
+
+# Source global definitions
+if [ -f /etc/bashrc ]; then
+ . /etc/bashrc
+fi
+```
+
+
+
+# 数据卷
+
+数据卷(volume)是一个虚拟目录,是**容器内目录**与**宿主机目录**之间映射的桥梁
+
+数据卷可以映射容器内目录到宿主机上,因为容器内目录是无法直接修改里面的内容的,原因是容器内目录是最小化的服务器,只有服务器的功能,其他的功能都没有,所以无法通过命令修改,通过数据卷可以将容器内的目录映射到一个固定的目录下进行修改
+
+
+
+## 数据卷命令
+
+| **命令** | **说明** | **文档地址** |
+| :-------------------- | :------------------- | :----------------------------------------------------------- |
+| docker volume create | 创建数据卷 | [docker volume create](https://docs.docker.com/engine/reference/commandline/volume_create/) |
+| docker volume ls | 查看所有数据卷 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/volume_ls/) |
+| docker volume rm | 删除指定数据卷 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/volume_prune/) |
+| docker volume inspect | 查看某个数据卷的详情 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/volume_inspect/) |
+| docker volume prune | 清除数据卷 | [docker volume prune](https://docs.docker.com/engine/reference/commandline/volume_prune/) |
+
+## 创建相关数据卷
+
+注意:容器与数据卷的挂载要在创建容器时配置,对于创建好的容器,是不能设置数据卷的。而且**创建容器的过程中,数据卷会自动创建**。
+
+也就是说,数据卷要在容器创建前进行创建,所以之前的容器需要删除,我们可以将之前的nginx容器删除
+
+```bash
+docker rm -f nginx
+```
+
+- 在执行docker run命令时,使用-v 数据卷名称:容器内目录 可以完成数据卷挂载
+- 当创建容器时,如果挂载了数据卷且数据卷不存在,会自动创建数据卷
+
+创建容器并创建对应数据卷,-d以后台形式运行,名称为nginx,开放宿主机端口为80且容器内端口为80,使用-v 数据卷名称:容器内目录来映射对应的数据卷完成数据卷挂载,最后的nginx设置的是数据卷的镜像名称,镜像名称需要自己特意指定,会在本地和docker仓库进行搜索
+
+```bash
+docker run -d --name nginx -p 80:80 -v html:/usr/share/nginx/html nginx
+```
+
+查看nginx容器是否创建成功
+
+```bash
+docker ps
+```
+
+查看数据卷是否创建成功
+
+```bash
+docker volume ls
+```
+
+展示数据卷的详细信息
+
+```bash
+docker volume inspect 数据卷的名称
+```
+
+这里的数据卷是html,所以通过html来查询,`docker volume inspect html`
+
+```bash
+[
+ {
+ "CreatedAt": "2023-11-07T05:27:47-08:00",
+ "Driver": "local",
+ "Labels": null,
+ "Mountpoint": "/var/lib/docker/volumes/html/_data",
+ "Name": "html",
+ "Options": null,
+ "Scope": "local"
+ }
+]
+```
+
+**Mountpoint**是所挂载的宿主机的位置
+
+此时,如果你进入挂载到的位置进行查看,就会看到你所访问的位置与之前nginx位置的内容是一致的
+
+## 数据卷的常用命令
+
+- docker volume ls:查看数据卷
+- docker volume rm:删除数据卷
+- docker volume inspect:查看数据卷详情
+- docker volume prune:删除未使用的数据卷
+
+## 本地目录挂载
+
+### 查看容器详情
+
+```bash
+docker inspect 容器名
+```
+
+- 在执行docker run命令时,使用-v 本地目录:容器内目录可以完成本地目录挂载
+- 本地目录必须以`/`或`./`开头,如果直接以名称开头,会被识别为数据卷而非本地目录
+ - -v mysql:/var/lib/mysql 会被识别为一个数据卷叫mysql
+ - -v ./mysql:/var/lib/mysql 会被识别当前目录下的mysql目录挂载
+
+挂载MySQL的目录到本地上
+
+```bash
+docker run -d \
+--name mysql \
+-p 3306:3306 \
+-e MYSQL_ROOT_PASSWORD=123 \
+-v /root/mysql/data:/var/lib/mysql \
+-v /root/mysql/init/:/docker-entrypoint-initdb.d \
+-v /root/mysql/conf/:/etc/mysql/conf.d \
+mysql
+```
+
+创建完成后
+
+查看目前启动的容器
+
+```bash
+docker ps
+```
+
+此时如果数据库中存在内容,说明挂载完成了,即使mysql镜像被删除了,只要你不删除挂载目录,数据就不会丢失,你只需要重新挂载到这些目录下,数据就能回来
+
+# 自定义镜像
+
+前面我们一直在使用别人准备好的镜像,那如果我要部署一个Java项目,把它打包为一个镜像该怎么做呢?
+
+## 镜像结构
+
+要想自己构建镜像,必须先了解镜像的结构。
+
+之前我们说过,镜像之所以能让我们快速跨操作系统部署应用而忽略其运行环境、配置,就是因为镜像中包含了程序运行需要的系统函数库、环境、配置、依赖。
+
+因此,自定义镜像本质就是依次准备好程序运行的基础环境、依赖、应用本身、运行配置等文件,并且打包而成。
+
+举个例子,我们要从0部署一个Java应用,大概流程是这样:
+
+- 准备一个linux服务(CentOS或者Ubuntu均可)
+
+- 安装并配置JDK
+- 上传Jar包
+- 运行jar包
+
+那因此,我们打包镜像也是分成这么几步:
+
+- 准备Linux运行环境(java项目并不需要完整的操作系统,仅仅是基础运行环境即可)
+- 安装并配置JDK
+- 拷贝jar包
+- 配置启动脚本
+
+上述步骤中的每一次操作其实都是在生产一些文件(系统运行环境、函数库、配置最终都是磁盘文件),所以**镜像就是一堆文件的集合**。
+
+但需要注意的是,镜像文件不是随意堆放的,而是按照操作的步骤分层叠加而成,每一层形成的文件都会单独打包并标记一个唯一id,称为**Layer**(**层**)。这样,如果我们构建时用到的某些层其他人已经制作过,就可以直接拷贝使用这些层,而不用重复制作。
+
+例如,第一步中需要的Linux运行环境,通用性就很强,所以Docker官方就制作了这样的只包含Linux运行环境的镜像。我们在制作java镜像时,就无需重复制作,直接使用Docker官方提供的CentOS或Ubuntu镜像作为基础镜像。然后再搭建其它层即可,这样逐层搭建,最终整个Java项目的镜像结构如图所示:
+
+
+
+此时我们可以拉取一个镜像来测试一下
+我们可以拉取redis的镜像来测试
+
+```bash
+docker pull redis
+```
+
+
+
+此时我们可以看到Already exists,重复的存在
+
+这是因为镜像文件中存在着重复的层,所以可以直接拷贝来加快镜像的拉取速度
+
+## Dockerfile
+
+由于制作镜像的过程中,需要逐层处理和打包,比较复杂,所以Docker就提供了自动打包镜像的功能。我们只需要将打包的过程,每一层要做的事情用固定的语法写下来,交给Docker去执行即可。
+
+而这种记录镜像结构的文件就称为**Dockerfile**,其对应的语法可以参考官方文档:
+
+https://docs.docker.com/engine/reference/builder/
+
+其中的语法比较多,比较常用的有:
+
+| **指令** | **说明** | **示例** |
+| :------------- | :------------------------------------------- | :--------------------------- |
+| **FROM** | 指定基础镜像 | `FROM centos:6` |
+| **ENV** | 设置环境变量,可在后面指令使用 | `ENV key value` |
+| **COPY** | 拷贝本地文件到镜像的指定目录 | `COPY ./xx.jar /tmp/app.jar` |
+| **RUN** | 执行Linux的shell命令,一般是安装过程的命令 | `RUN yum install gcc` |
+| **EXPOSE** | 指定容器运行时监听的端口,是给镜像使用者看的 | EXPOSE 8080 |
+| **ENTRYPOINT** | 镜像中应用的启动命令,容器运行时调用 | ENTRYPOINT java -jar xx.jar |
+
+例如,要基于Ubuntu镜像来构建一个Java应用,其Dockerfile内容如下:
+
+```bash
+# 指定基础镜像
+FROM ubuntu:16.04
+# 配置环境变量,JDK的安装目录、容器内时区
+ENV JAVA_DIR=/usr/local
+ENV TZ=Asia/Shanghai
+# 拷贝jdk和java项目的包
+COPY ./jdk8.tar.gz $JAVA_DIR/
+COPY ./docker-demo.jar /tmp/app.jar
+# 设定时区
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
+# 安装JDK
+RUN cd $JAVA_DIR \
+ && tar -xf ./jdk8.tar.gz \
+ && mv ./jdk1.8.0_144 ./java8
+# 配置环境变量
+ENV JAVA_HOME=$JAVA_DIR/java8
+ENV PATH=$PATH:$JAVA_HOME/bin
+# 指定项目监听的端口
+EXPOSE 8080
+# 入口,java项目的启动命令
+ENTRYPOINT ["java", "-jar", "/app.jar"]
+```
+
+以后我们会有很多很多java项目需要打包为镜像,他们都需要Linux系统环境、JDK环境这两层,只有上面的3层不同(因为jar包不同)。如果每次制作java镜像都重复制作前两层镜像,是不是很麻烦。
+
+所以,就有人提供了基础的系统加JDK环境,我们在此基础上制作java镜像,就可以省去JDK的配置了:
+
+```Dockerfile
+# 基础镜像
+FROM openjdk:11.0-jre-buster
+# 设定时区
+ENV TZ=Asia/Shanghai
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
+# 拷贝jar包
+COPY docker-demo.jar /app.jar
+# 入口
+ENTRYPOINT ["java", "-jar", "/app.jar"]
+```
+
+## 自定义镜像
+
+当编写好了Dockerfile,可以利用下面的命令来构建镜像:
+
+```bash
+docker build -t myTest:1.0 .
+```
+
+- `-t`:是给镜像起名,格式依然是repository:tag的格式,不指定tag时,默认为latest(最新)
+- `.`:是指定Dockerfile所在目录,如果就在当前目录,则指定为`.`,如果是指定了当前目录的话,就需要对Dockerfile的目录做一些调整
+
+将资料中的demo目录拷贝到根目录下,进入demo目录
+
+```bash
+cd /root/demo
+```
+
+如果觉得下载镜像不方便可以拷贝资料中的images目录到根目录下
+
+并通过
+
+```bash
+# 加载为docker的镜像
+docker load -i tar包的名称
+```
+
+构建镜像
+
+```bash
+docker build -t docker-demo:1.0 .
+```
+
+命令说明:
+
+- `docker build `: 就是构建一个docker镜像
+- `-t docker-demo:1.0` :`-t`参数是指定镜像的名称(`repository`和`tag`)
+- `.` : 最后的点是指构建时Dockerfile所在路径,由于我们进入了demo目录,所以指定的是`.`代表当前目录,也可以直接指定Dockerfile目录:
+
+```bash
+# 直接指定Dockerfile目录
+docker build -t docker-demo:1.0 /root/demo
+```
+
+运行`docker images`
+
+```bash
+REPOSITORY TAG IMAGE ID CREATED SIZE
+docker-demo latest cee3813af51e 16 seconds ago 319MB
+nginx latest 605c77e624dd 22 months ago 141MB
+redis latest 7614ae9453d1 22 months ago 113MB
+mysql latest 3218b38490ce 22 months ago 516MB
+openjdk 11.0-jre-buster 57925f2e4cff 23 months ago 301MB
+```
+
+此时发现镜像被引入进来了
+
+接着运行该镜像
+
+```bash
+docker run -d --name demo -p 8080:8080 docker-demo
+```
+
+查看该镜像是否正在运行
+
+```bash
+docker ps
+```
+
+接着可以看看它的运行日志
+
+```bash
+docker logs -f demo
+```
+
+来到浏览器中
+
+```
+http://自己的ip地址:8080/hello/count
+```
+
+访问一下是否有效
+
+总结:
+
+镜像的结构是怎样的?
+
+- 镜像中包含了应用程序所需要的运行环境、函数库、配置、以及应用本身等各种文件,这些文件分层打包而成
+
+Dockerfile是做什么的?
+
+- Dockerfile就是利用固定的指令来描述镜像的结构和构建过程,这样Docker才可以依次来构建镜像
+
+构建镜像的命令是什么?
+
+- docker build -t 镜像名 Dockerfile目录
+
+# 容器网络互连
+
+java项目有时候需要访问其它各种中间件,例如MySQL、Redis等。现在,我们的容器之间能否互相访问呢?我们来测试一下
+
+首先,我们查看下MySQL容器的详细信息,重点关注其中的网络IP地址:
+
+记得启动mysql容器
+
+```bash
+docker inspect mysql
+```
+
+得到的IP地址如下:`"IPAddress": "172.17.0.3"`
+
+然后通过命令进入demo容器 `docker exec -it demo bash`
+
+在demo容器中ping mysql容器,查看是否能成功
+
+```bash
+64 bytes from 172.17.0.3: icmp_seq=1 ttl=64 time=0.168 ms
+64 bytes from 172.17.0.3: icmp_seq=2 ttl=64 time=0.087 ms
+64 bytes from 172.17.0.3: icmp_seq=3 ttl=64 time=0.077 ms
+64 bytes from 172.17.0.3: icmp_seq=4 ttl=64 time=0.077 ms
+```
+
+测试表明,可以互联
+
+默认情况下,所有容器是以bridge(网桥)方式连接到Docker的一个虚拟网桥上:
+
+
+
+但是,容器的网络IP其实是一个虚拟的IP,其值并不固定与某一个容器绑定,如果我们在开发时写死某个IP,而在部署时很可能MySQL容器的IP会发生变化,连接会失败。
+
+所以,我们必须借助于docker的网络功能来解决这个问题,官方文档:
+
+https://docs.docker.com/engine/reference/commandline/network/
+
+常见命令有:
+
+| **命令** | **说明** | **文档地址** |
+| :------------------------ | :----------------------- | :----------------------------------------------------------- |
+| docker network create | 创建一个网络 | [docker network create](https://docs.docker.com/engine/reference/commandline/network_create/) |
+| docker network ls | 查看所有网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_ls/) |
+| docker network rm | 删除指定网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_rm/) |
+| docker network prune | 清除未使用的网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_prune/) |
+| docker network connect | 使指定容器连接加入某网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_connect/) |
+| docker network disconnect | 使指定容器连接离开某网络 | [docker network disconnect](https://docs.docker.com/engine/reference/commandline/network_disconnect/) |
+| docker network inspect | 查看网络详细信息 | [docker network inspect](https://docs.docker.com/engine/reference/commandline/network_inspect/) |
+
+## 自定义网络
+
+```bash
+docker network ls
+```
+
+先查看存在的网络有哪些
+
+接着我们可以创建一个网络
+
+创建一个eastwind的网络,并查看所有网络
+
+```bash
+docker network create eastwind
+docker network ls
+```
+
+```bash
+NETWORK ID NAME DRIVER SCOPE
+3de0c3b573b5 bridge bridge local
+76140a3e4693 eastwind bridge local
+8c7edfa12652 host host local
+8ef97f11560b none null local
+```
+
+此时发现刚刚创建的网络也在其中
+如果想加入一个容器到自定义网络中,可以使用`connect`
+
+```bash
+docker network connect eastwind mysql
+```
+
+这样就可以将mysql加入到eastwind网络中了
+
+此时可以通过
+
+```bash
+# 查看网络
+docker inspect mysql
+```
+
+
+
+
+
+具体命令如下:
+
+```Bash
+# 创建目录
+mkdir -p /etc/docker
+
+# 复制内容,注意把其中的镜像加速地址改成你自己的
+tee /etc/docker/daemon.json <<-'EOF'
+{
+ "registry-mirrors": ["https://xxxx.mirror.aliyuncs.com"]
+}
+EOF
+
+# 重新加载配置
+systemctl daemon-reload
+
+# 重启Docker
+systemctl restart docker
+```
+
+# 部署MySQL
+
+部署MySQL只需要一条指令
+
+```bash
+docker run -d \
+ --name mysql \
+ -p 3306:3306 \
+ -e TZ=Asia/Shanghai \
+ -e MYSQL_ROOT_PASSWORD=123 \
+ mysql
+```
+
+接着你可以打开你使用的sql工具,来连接docker刚刚部署的mysql,连接成功说明,部署成功了
+
+## 镜像和容器
+
+当我们利用Docker安装应用时,Docker会自动搜索并下载应用**镜像(image)**。镜像不仅包含应用本身,还包含应用运行所需要的环境、配置、系统函数库。Docker会在运行镜像时创建一个隔离环境。称为**容器(container)**。
+
+**镜像仓库**:存储和管理镜像的平台,Docker官方维护了一个公共仓库:Docker Hub。
+
+在我们启动Docker的服务器后,docker daemon守护进程会对docker命令进行监听,当我们运行docker xxx的命令后,守护进程就会去查看本地是否存在镜像,存在就直接使用,否则就回去镜像仓库进行下载,下载完成后作为容器来使用
+
+## 命令解读
+
+```bash
+docker run -d \
+ --name mysql \
+ -p 3306:3306 \
+ -e TZ=Asia/Shanghai \
+ -e MYSQL_ROOT_PASSWORD=123 \
+ mysql
+```
+
+- `docker run -d` :创建并运行一个容器,`-d`则是让容器以后台进程运行
+- `--name mysql ` : 给容器起个名字叫`mysql`,你可以叫别的
+- `-p 3306:3306` : 设置端口映射。
+ - **容器是隔离环境**,外界不可访问。但是可以将宿主机端口映射容器内到端口,当访问宿主机指定端口时,就是在访问容器内的端口了。
+ - 容器内端口往往是由容器内的进程决定,例如MySQL进程默认端口是3306,因此容器内端口一定是3306;而宿主机端口则可以任意指定,一般与容器内保持一致。
+ - 格式: `-p 宿主机端口:容器内端口`,示例中就是将宿主机的3306映射到容器内的3306端口
+- `-e TZ=Asia/Shanghai` : 配置容器内进程运行时的一些参数
+ - 格式:`-e KEY=VALUE`,KEY和VALUE都由容器内进程决定
+ - 案例中,`TZ=Asia/Shanghai`是设置时区;`MYSQL_ROOT_PASSWORD=123`是设置MySQL默认密码
+- `mysql`:设置**镜像**名称,Docker会根据这个名字搜索并下载镜像
+ - 格式:`REPOSITORY:TAG`,例如`mysql:8.0`,其中`REPOSITORY`可以理解为镜像名,`TAG`是版本号
+ - 在未指定`TAG`的情况下,默认是最新版本,也就是`mysql:latest`
+
+### 镜像命名规范
+
+- 镜像名称一般分两部分组成:[repository]:[tag]
+ - 其中repository就是镜像名
+ - tag是镜像的版本
+- 在没有指定tag时,默认是latest(最新),代表最新版本的镜像
+
+# Docker基础
+
+Docker最常见的命令就是操作镜像、容器的命令,详见官方文档:https://docs.docker.com/
+
+Docker常见命令,可以参考官方文档:https://docs.docker.com/engine/reference/commandline/cli/
+
+比较常见的命令有:
+
+| **命令** | **说明** | **文档地址** |
+| :------------- | :----------------------------- | :----------------------------------------------------------- |
+| docker pull | 拉取镜像 | [docker pull](https://docs.docker.com/engine/reference/commandline/pull/) |
+| docker push | 推送镜像到DockerRegistry | [docker push](https://docs.docker.com/engine/reference/commandline/push/) |
+| docker images | 查看本地镜像 | [docker images](https://docs.docker.com/engine/reference/commandline/images/) |
+| docker rmi | 删除本地镜像 | [docker rmi](https://docs.docker.com/engine/reference/commandline/rmi/) |
+| docker run | 创建并运行容器(不能重复创建) | [docker run](https://docs.docker.com/engine/reference/commandline/run/) |
+| docker stop | 停止指定容器 | [docker stop](https://docs.docker.com/engine/reference/commandline/stop/) |
+| docker start | 启动指定容器 | [docker start](https://docs.docker.com/engine/reference/commandline/start/) |
+| docker restart | 重新启动容器 | [docker restart](https://docs.docker.com/engine/reference/commandline/restart/) |
+| docker rm | 删除指定容器 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/rm/) |
+| docker ps | 查看容器 | [docker ps](https://docs.docker.com/engine/reference/commandline/ps/) |
+| docker logs | 查看容器运行日志 | [docker logs](https://docs.docker.com/engine/reference/commandline/logs/) |
+| docker exec | 进入容器 | [docker exec](https://docs.docker.com/engine/reference/commandline/exec/) |
+| docker save | 保存镜像到本地压缩文件 | [docker save](https://docs.docker.com/engine/reference/commandline/save/) |
+| docker load | 加载本地压缩文件到镜像 | [docker load](https://docs.docker.com/engine/reference/commandline/load/) |
+| docker inspect | 查看容器详细信息 | [docker inspect](https://docs.docker.com/engine/reference/commandline/inspect/) |
+
+## 保存镜像到本地压缩文件
+
+```bash
+docker save -o 镜像名称.tar 镜像名称:版本
+```
+
+## 删除镜像
+
+删除镜像时如果遇到以下报错:Error response from daemon: conflict: unable to remove repository reference "mysql:latest" (must force) - container 0fa37bf7c610 is using its referenced image 3218b38490ce
+
+报错内容是因为镜像被容器引用,那么删除容器再删除镜像。
+
+此时使用`docker rm 0fa37bf7c610 `
+
+再次执行即可
+
+```bash
+docker rmi 镜像名:版本
+```
+
+## 加载已有镜像
+
+-p:不输出任何内容
+
+```
+docker load -i 读取的镜像名称 -p
+```
+
+## 创建并运行容器
+
+docker run
+
+-d:后台运行
+
+--name:容器名称
+
+-p:端口号,分为宿主机端口:容器内端口
+
+-e:相关配置
+
+最后是设置镜像名称
+
+```bash
+docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123 mysql
+```
+
+## 停止容器运行
+
+```bash
+docker stop 容器名
+```
+
+## 查看容器是否运行
+
+```bash
+docker ps
+```
+
+查看所有容器,包括没有运行的容器
+
+```bash
+docker ps -a
+```
+
+## 启动容器
+
+```bash
+docker start 容器名
+```
+
+## 查看容器日志
+
+```bash
+docker logs 容器名
+```
+
+### 持续查看容器日志
+
+```bash
+docker logs -f 容器名
+```
+
+## 进入容器内部
+
+-it:添加一个可输入的终端
+
+bash:命令行交互
+
+```bash
+docker exec -it 容器名 bash
+# 退出
+exit
+```
+
+## 删除容器
+
+删除容器需要先停止容器再删除
+
+```bash
+docker stop 被删除的容器名
+```
+
+```bash
+docker rm 容器名
+```
+
+也可以强制删除docker
+
+```bash
+docker rm 容器名 -f
+```
+
+## 命令别名
+
+```bash
+# 修改/root/.bashrc文件
+vi /root/.bashrc
+内容如下:
+# .bashrc
+
+# User specific aliases and functions
+
+alias rm='rm -i'
+alias cp='cp -i'
+alias mv='mv -i'
+alias dps='docker ps --format "table {{.ID}}\t{{.Image}}\t{{.Ports}}\t{{.Status}}\t{{.Names}}"'
+alias dis='docker images'
+
+# Source global definitions
+if [ -f /etc/bashrc ]; then
+ . /etc/bashrc
+fi
+```
+
+
+
+# 数据卷
+
+数据卷(volume)是一个虚拟目录,是**容器内目录**与**宿主机目录**之间映射的桥梁
+
+数据卷可以映射容器内目录到宿主机上,因为容器内目录是无法直接修改里面的内容的,原因是容器内目录是最小化的服务器,只有服务器的功能,其他的功能都没有,所以无法通过命令修改,通过数据卷可以将容器内的目录映射到一个固定的目录下进行修改
+
+
+
+## 数据卷命令
+
+| **命令** | **说明** | **文档地址** |
+| :-------------------- | :------------------- | :----------------------------------------------------------- |
+| docker volume create | 创建数据卷 | [docker volume create](https://docs.docker.com/engine/reference/commandline/volume_create/) |
+| docker volume ls | 查看所有数据卷 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/volume_ls/) |
+| docker volume rm | 删除指定数据卷 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/volume_prune/) |
+| docker volume inspect | 查看某个数据卷的详情 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/volume_inspect/) |
+| docker volume prune | 清除数据卷 | [docker volume prune](https://docs.docker.com/engine/reference/commandline/volume_prune/) |
+
+## 创建相关数据卷
+
+注意:容器与数据卷的挂载要在创建容器时配置,对于创建好的容器,是不能设置数据卷的。而且**创建容器的过程中,数据卷会自动创建**。
+
+也就是说,数据卷要在容器创建前进行创建,所以之前的容器需要删除,我们可以将之前的nginx容器删除
+
+```bash
+docker rm -f nginx
+```
+
+- 在执行docker run命令时,使用-v 数据卷名称:容器内目录 可以完成数据卷挂载
+- 当创建容器时,如果挂载了数据卷且数据卷不存在,会自动创建数据卷
+
+创建容器并创建对应数据卷,-d以后台形式运行,名称为nginx,开放宿主机端口为80且容器内端口为80,使用-v 数据卷名称:容器内目录来映射对应的数据卷完成数据卷挂载,最后的nginx设置的是数据卷的镜像名称,镜像名称需要自己特意指定,会在本地和docker仓库进行搜索
+
+```bash
+docker run -d --name nginx -p 80:80 -v html:/usr/share/nginx/html nginx
+```
+
+查看nginx容器是否创建成功
+
+```bash
+docker ps
+```
+
+查看数据卷是否创建成功
+
+```bash
+docker volume ls
+```
+
+展示数据卷的详细信息
+
+```bash
+docker volume inspect 数据卷的名称
+```
+
+这里的数据卷是html,所以通过html来查询,`docker volume inspect html`
+
+```bash
+[
+ {
+ "CreatedAt": "2023-11-07T05:27:47-08:00",
+ "Driver": "local",
+ "Labels": null,
+ "Mountpoint": "/var/lib/docker/volumes/html/_data",
+ "Name": "html",
+ "Options": null,
+ "Scope": "local"
+ }
+]
+```
+
+**Mountpoint**是所挂载的宿主机的位置
+
+此时,如果你进入挂载到的位置进行查看,就会看到你所访问的位置与之前nginx位置的内容是一致的
+
+## 数据卷的常用命令
+
+- docker volume ls:查看数据卷
+- docker volume rm:删除数据卷
+- docker volume inspect:查看数据卷详情
+- docker volume prune:删除未使用的数据卷
+
+## 本地目录挂载
+
+### 查看容器详情
+
+```bash
+docker inspect 容器名
+```
+
+- 在执行docker run命令时,使用-v 本地目录:容器内目录可以完成本地目录挂载
+- 本地目录必须以`/`或`./`开头,如果直接以名称开头,会被识别为数据卷而非本地目录
+ - -v mysql:/var/lib/mysql 会被识别为一个数据卷叫mysql
+ - -v ./mysql:/var/lib/mysql 会被识别当前目录下的mysql目录挂载
+
+挂载MySQL的目录到本地上
+
+```bash
+docker run -d \
+--name mysql \
+-p 3306:3306 \
+-e MYSQL_ROOT_PASSWORD=123 \
+-v /root/mysql/data:/var/lib/mysql \
+-v /root/mysql/init/:/docker-entrypoint-initdb.d \
+-v /root/mysql/conf/:/etc/mysql/conf.d \
+mysql
+```
+
+创建完成后
+
+查看目前启动的容器
+
+```bash
+docker ps
+```
+
+此时如果数据库中存在内容,说明挂载完成了,即使mysql镜像被删除了,只要你不删除挂载目录,数据就不会丢失,你只需要重新挂载到这些目录下,数据就能回来
+
+# 自定义镜像
+
+前面我们一直在使用别人准备好的镜像,那如果我要部署一个Java项目,把它打包为一个镜像该怎么做呢?
+
+## 镜像结构
+
+要想自己构建镜像,必须先了解镜像的结构。
+
+之前我们说过,镜像之所以能让我们快速跨操作系统部署应用而忽略其运行环境、配置,就是因为镜像中包含了程序运行需要的系统函数库、环境、配置、依赖。
+
+因此,自定义镜像本质就是依次准备好程序运行的基础环境、依赖、应用本身、运行配置等文件,并且打包而成。
+
+举个例子,我们要从0部署一个Java应用,大概流程是这样:
+
+- 准备一个linux服务(CentOS或者Ubuntu均可)
+
+- 安装并配置JDK
+- 上传Jar包
+- 运行jar包
+
+那因此,我们打包镜像也是分成这么几步:
+
+- 准备Linux运行环境(java项目并不需要完整的操作系统,仅仅是基础运行环境即可)
+- 安装并配置JDK
+- 拷贝jar包
+- 配置启动脚本
+
+上述步骤中的每一次操作其实都是在生产一些文件(系统运行环境、函数库、配置最终都是磁盘文件),所以**镜像就是一堆文件的集合**。
+
+但需要注意的是,镜像文件不是随意堆放的,而是按照操作的步骤分层叠加而成,每一层形成的文件都会单独打包并标记一个唯一id,称为**Layer**(**层**)。这样,如果我们构建时用到的某些层其他人已经制作过,就可以直接拷贝使用这些层,而不用重复制作。
+
+例如,第一步中需要的Linux运行环境,通用性就很强,所以Docker官方就制作了这样的只包含Linux运行环境的镜像。我们在制作java镜像时,就无需重复制作,直接使用Docker官方提供的CentOS或Ubuntu镜像作为基础镜像。然后再搭建其它层即可,这样逐层搭建,最终整个Java项目的镜像结构如图所示:
+
+
+
+此时我们可以拉取一个镜像来测试一下
+我们可以拉取redis的镜像来测试
+
+```bash
+docker pull redis
+```
+
+
+
+此时我们可以看到Already exists,重复的存在
+
+这是因为镜像文件中存在着重复的层,所以可以直接拷贝来加快镜像的拉取速度
+
+## Dockerfile
+
+由于制作镜像的过程中,需要逐层处理和打包,比较复杂,所以Docker就提供了自动打包镜像的功能。我们只需要将打包的过程,每一层要做的事情用固定的语法写下来,交给Docker去执行即可。
+
+而这种记录镜像结构的文件就称为**Dockerfile**,其对应的语法可以参考官方文档:
+
+https://docs.docker.com/engine/reference/builder/
+
+其中的语法比较多,比较常用的有:
+
+| **指令** | **说明** | **示例** |
+| :------------- | :------------------------------------------- | :--------------------------- |
+| **FROM** | 指定基础镜像 | `FROM centos:6` |
+| **ENV** | 设置环境变量,可在后面指令使用 | `ENV key value` |
+| **COPY** | 拷贝本地文件到镜像的指定目录 | `COPY ./xx.jar /tmp/app.jar` |
+| **RUN** | 执行Linux的shell命令,一般是安装过程的命令 | `RUN yum install gcc` |
+| **EXPOSE** | 指定容器运行时监听的端口,是给镜像使用者看的 | EXPOSE 8080 |
+| **ENTRYPOINT** | 镜像中应用的启动命令,容器运行时调用 | ENTRYPOINT java -jar xx.jar |
+
+例如,要基于Ubuntu镜像来构建一个Java应用,其Dockerfile内容如下:
+
+```bash
+# 指定基础镜像
+FROM ubuntu:16.04
+# 配置环境变量,JDK的安装目录、容器内时区
+ENV JAVA_DIR=/usr/local
+ENV TZ=Asia/Shanghai
+# 拷贝jdk和java项目的包
+COPY ./jdk8.tar.gz $JAVA_DIR/
+COPY ./docker-demo.jar /tmp/app.jar
+# 设定时区
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
+# 安装JDK
+RUN cd $JAVA_DIR \
+ && tar -xf ./jdk8.tar.gz \
+ && mv ./jdk1.8.0_144 ./java8
+# 配置环境变量
+ENV JAVA_HOME=$JAVA_DIR/java8
+ENV PATH=$PATH:$JAVA_HOME/bin
+# 指定项目监听的端口
+EXPOSE 8080
+# 入口,java项目的启动命令
+ENTRYPOINT ["java", "-jar", "/app.jar"]
+```
+
+以后我们会有很多很多java项目需要打包为镜像,他们都需要Linux系统环境、JDK环境这两层,只有上面的3层不同(因为jar包不同)。如果每次制作java镜像都重复制作前两层镜像,是不是很麻烦。
+
+所以,就有人提供了基础的系统加JDK环境,我们在此基础上制作java镜像,就可以省去JDK的配置了:
+
+```Dockerfile
+# 基础镜像
+FROM openjdk:11.0-jre-buster
+# 设定时区
+ENV TZ=Asia/Shanghai
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
+# 拷贝jar包
+COPY docker-demo.jar /app.jar
+# 入口
+ENTRYPOINT ["java", "-jar", "/app.jar"]
+```
+
+## 自定义镜像
+
+当编写好了Dockerfile,可以利用下面的命令来构建镜像:
+
+```bash
+docker build -t myTest:1.0 .
+```
+
+- `-t`:是给镜像起名,格式依然是repository:tag的格式,不指定tag时,默认为latest(最新)
+- `.`:是指定Dockerfile所在目录,如果就在当前目录,则指定为`.`,如果是指定了当前目录的话,就需要对Dockerfile的目录做一些调整
+
+将资料中的demo目录拷贝到根目录下,进入demo目录
+
+```bash
+cd /root/demo
+```
+
+如果觉得下载镜像不方便可以拷贝资料中的images目录到根目录下
+
+并通过
+
+```bash
+# 加载为docker的镜像
+docker load -i tar包的名称
+```
+
+构建镜像
+
+```bash
+docker build -t docker-demo:1.0 .
+```
+
+命令说明:
+
+- `docker build `: 就是构建一个docker镜像
+- `-t docker-demo:1.0` :`-t`参数是指定镜像的名称(`repository`和`tag`)
+- `.` : 最后的点是指构建时Dockerfile所在路径,由于我们进入了demo目录,所以指定的是`.`代表当前目录,也可以直接指定Dockerfile目录:
+
+```bash
+# 直接指定Dockerfile目录
+docker build -t docker-demo:1.0 /root/demo
+```
+
+运行`docker images`
+
+```bash
+REPOSITORY TAG IMAGE ID CREATED SIZE
+docker-demo latest cee3813af51e 16 seconds ago 319MB
+nginx latest 605c77e624dd 22 months ago 141MB
+redis latest 7614ae9453d1 22 months ago 113MB
+mysql latest 3218b38490ce 22 months ago 516MB
+openjdk 11.0-jre-buster 57925f2e4cff 23 months ago 301MB
+```
+
+此时发现镜像被引入进来了
+
+接着运行该镜像
+
+```bash
+docker run -d --name demo -p 8080:8080 docker-demo
+```
+
+查看该镜像是否正在运行
+
+```bash
+docker ps
+```
+
+接着可以看看它的运行日志
+
+```bash
+docker logs -f demo
+```
+
+来到浏览器中
+
+```
+http://自己的ip地址:8080/hello/count
+```
+
+访问一下是否有效
+
+总结:
+
+镜像的结构是怎样的?
+
+- 镜像中包含了应用程序所需要的运行环境、函数库、配置、以及应用本身等各种文件,这些文件分层打包而成
+
+Dockerfile是做什么的?
+
+- Dockerfile就是利用固定的指令来描述镜像的结构和构建过程,这样Docker才可以依次来构建镜像
+
+构建镜像的命令是什么?
+
+- docker build -t 镜像名 Dockerfile目录
+
+# 容器网络互连
+
+java项目有时候需要访问其它各种中间件,例如MySQL、Redis等。现在,我们的容器之间能否互相访问呢?我们来测试一下
+
+首先,我们查看下MySQL容器的详细信息,重点关注其中的网络IP地址:
+
+记得启动mysql容器
+
+```bash
+docker inspect mysql
+```
+
+得到的IP地址如下:`"IPAddress": "172.17.0.3"`
+
+然后通过命令进入demo容器 `docker exec -it demo bash`
+
+在demo容器中ping mysql容器,查看是否能成功
+
+```bash
+64 bytes from 172.17.0.3: icmp_seq=1 ttl=64 time=0.168 ms
+64 bytes from 172.17.0.3: icmp_seq=2 ttl=64 time=0.087 ms
+64 bytes from 172.17.0.3: icmp_seq=3 ttl=64 time=0.077 ms
+64 bytes from 172.17.0.3: icmp_seq=4 ttl=64 time=0.077 ms
+```
+
+测试表明,可以互联
+
+默认情况下,所有容器是以bridge(网桥)方式连接到Docker的一个虚拟网桥上:
+
+
+
+但是,容器的网络IP其实是一个虚拟的IP,其值并不固定与某一个容器绑定,如果我们在开发时写死某个IP,而在部署时很可能MySQL容器的IP会发生变化,连接会失败。
+
+所以,我们必须借助于docker的网络功能来解决这个问题,官方文档:
+
+https://docs.docker.com/engine/reference/commandline/network/
+
+常见命令有:
+
+| **命令** | **说明** | **文档地址** |
+| :------------------------ | :----------------------- | :----------------------------------------------------------- |
+| docker network create | 创建一个网络 | [docker network create](https://docs.docker.com/engine/reference/commandline/network_create/) |
+| docker network ls | 查看所有网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_ls/) |
+| docker network rm | 删除指定网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_rm/) |
+| docker network prune | 清除未使用的网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_prune/) |
+| docker network connect | 使指定容器连接加入某网络 | [docs.docker.com](https://docs.docker.com/engine/reference/commandline/network_connect/) |
+| docker network disconnect | 使指定容器连接离开某网络 | [docker network disconnect](https://docs.docker.com/engine/reference/commandline/network_disconnect/) |
+| docker network inspect | 查看网络详细信息 | [docker network inspect](https://docs.docker.com/engine/reference/commandline/network_inspect/) |
+
+## 自定义网络
+
+```bash
+docker network ls
+```
+
+先查看存在的网络有哪些
+
+接着我们可以创建一个网络
+
+创建一个eastwind的网络,并查看所有网络
+
+```bash
+docker network create eastwind
+docker network ls
+```
+
+```bash
+NETWORK ID NAME DRIVER SCOPE
+3de0c3b573b5 bridge bridge local
+76140a3e4693 eastwind bridge local
+8c7edfa12652 host host local
+8ef97f11560b none null local
+```
+
+此时发现刚刚创建的网络也在其中
+如果想加入一个容器到自定义网络中,可以使用`connect`
+
+```bash
+docker network connect eastwind mysql
+```
+
+这样就可以将mysql加入到eastwind网络中了
+
+此时可以通过
+
+```bash
+# 查看网络
+docker inspect mysql
+```
+
+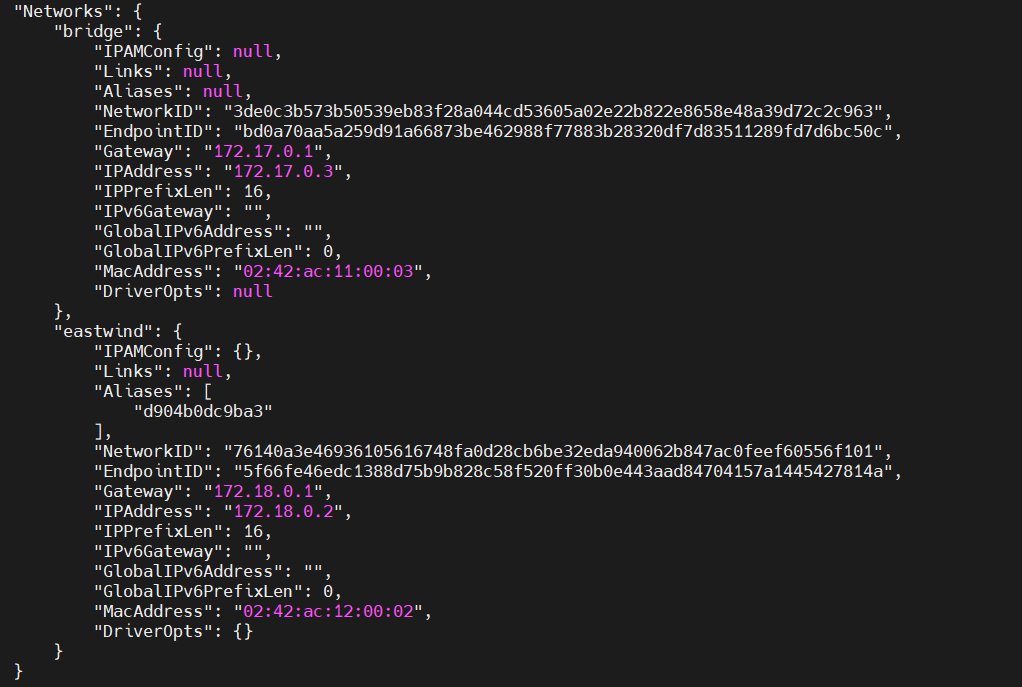 +
+上面这种是可以在容器存在时进行网络连接,下面这种方法可以让容器在创建时就进行连接
+我们先将之前的demo容器删除
+
+接着在创建容器时,可以添加一个参数`--network`,后面跟自定义网络的名称
+
+```bash
+docker run -d --name demo -p 8080:8080 --network eastwind docker-demo
+```
+
+```bash
+docker inspect
+```
+
+此时如果我们进入demo容器中ping mysql和nginx
+
+```bash
+docker exec -it demo bash
+ping mysql
+ping nginx
+```
+
+因为nginx与demo不在一个网段中,所以无法ping通,但mysql可以
+
+**加入自定义网络的容器才可以通过容器名互相访问**
+
+# 部署Java项目
+
+将资料中的项目打包为jar包
+
+将jar包和Dockerfile文件传入linux下
+
+```bash
+docker build -t emall .
+```
+
+查看docker 镜像是否部署成功
+
+```bash
+docker images
+```
+
+接着运行该镜像
+
+代码释义:
+
+后台运行该镜像,名称为emall,指定开放端口为8080,设置网络为eastwind,指定运行的镜像为emall
+
+```bash
+docker run -d --name emall -p 8080:8080 --network eastwind emall
+```
+
+接着可以通过查看日志
+
+```bash
+docker logs -f emall
+```
+
+访问该路径
+
+```
+http://192.168.10.142:8080/hi
+```
+
+# 部署前端
+
+修改nginx目录下的nginx.conf为
+
+这里的proxy_pass需要修改http://自己的后端镜像:8080
+
+```conf
+server {
+ listen 18080;
+ # 指定前端项目所在的位置
+ location / {
+ root /usr/share/nginx/html/hmall-portal;
+ }
+
+ error_page 500 502 503 504 /50x.html;
+ location = /50x.html {
+ root html;
+ }
+ location /api {
+ rewrite /api/(.*) /$1 break;
+ proxy_pass http://eastwind:8080;
+ }
+ }
+ server {
+ listen 18081;
+ # 指定前端项目所在的位置
+ location / {
+ root /usr/share/nginx/html/hmall-admin;
+ }
+
+ error_page 500 502 503 504 /50x.html;
+ location = /50x.html {
+ root html;
+ }
+ location /api {
+ rewrite /api/(.*) /$1 break;
+ proxy_pass http://eastwind:8080;
+ }
+ }
+```
+
+将前台的打包好的内容上传
+
+运行前台的项目
+
+命令解读:
+
+以后台模式运行一个叫nginx的容器
+
+开放端口18080和18081,并且与容器内的队友路径进行关联
+
+设置对应的网络为自定义网络eastwind
+
+设置使用的镜像为nginx
+
+```bash
+docker run -d \
+--name nginx \
+-p 18080:18080 \
+-p 18081:18081 \
+-v /root/nginx/html:/usr/share/nginx/html \
+-v /root/nginx/nginx.conf:/etc/nginx/nginx.conf \
+--network eastwind \
+nginx
+```
+
+访问http://你的虚拟机ip:18080
+
+# DockerCompose
+
+我们部署一个简单的java项目,其中包含3个容器:
+
+- MySQL
+- Nginx
+- Java项目
+
+而稍微复杂的项目,其中还会有各种各样的其它中间件,需要部署的东西远不止3个。如果还像之前那样手动的逐一部署,就太麻烦了。
+
+而Docker Compose就可以帮助我们实现**多个相互关联的Docker容器的快速部署**。它允许用户通过一个单独的 docker-compose.yml 模板文件(YAML 格式)来定义一组相关联的应用容器。
+
+## 基本语法
+
+docker-compose.yml文件的基本语法可以参考官方文档:https://docs.docker.com/compose/compose-file/compose-file-v3/
+
+docker-compose文件中可以定义多个相互关联的应用容器,每一个应用容器被称为一个服务(service)。由于service就是在定义某个应用的运行时参数,因此与`docker run`参数非常相似。
+
+举例来说,用docker run部署MySQL的命令如下:
+
+```bash
+docker run -d \
+ --name mysql \
+ -p 3306:3306 \
+ -e TZ=Asia/Shanghai \
+ -e MYSQL_ROOT_PASSWORD=123 \
+ -v ./mysql/data:/var/lib/mysql \
+ -v ./mysql/conf:/etc/mysql/conf.d \
+ -v ./mysql/init:/docker-entrypoint-initdb.d \
+ --network eastwind
+ mysql
+```
+
+如果用`docker-compose.yml`文件来定义,就是这样:
+
+```yaml
+version: "3.8"
+
+services:
+ mysql:
+ image: mysql
+ container_name: mysql
+ ports:
+ - "3306:3306"
+ environment:
+ TZ: Asia/Shanghai
+ MYSQL_ROOT_PASSWORD: 123
+ volumes:
+ - "./mysql/conf:/etc/mysql/conf.d"
+ - "./mysql/data:/var/lib/mysql"
+ networks:
+ - new
+networks:
+ new:
+ name: eastwind
+```
+
+对比如下:
+
+| **docker run 参数** | **docker compose 指令** | **说明** |
+| :------------------ | :---------------------- | :--------- |
+| --name | container_name | 容器名称 |
+| -p | ports | 端口映射 |
+| -e | environment | 环境变量 |
+| -v | volumes | 数据卷配置 |
+| --network | networks | 网络 |
+
+商城部署文件:
+
+```YAML
+version: "3.8"
+
+services:
+ mysql:
+ image: mysql
+ container_name: mysql
+ ports:
+ - "3306:3306"
+ environment:
+ TZ: Asia/Shanghai
+ MYSQL_ROOT_PASSWORD: 123
+ volumes:
+ - "./mysql/conf:/etc/mysql/conf.d"
+ - "./mysql/data:/var/lib/mysql"
+ - "./mysql/init:/docker-entrypoint-initdb.d"
+ networks:
+ - hm-net
+ hmall:
+ build:
+ context: .
+ dockerfile: Dockerfile
+ container_name: hmall
+ ports:
+ - "8080:8080"
+ networks:
+ - hm-net
+ depends_on:
+ - mysql
+ nginx:
+ image: nginx
+ container_name: nginx
+ ports:
+ - "18080:18080"
+ - "18081:18081"
+ volumes:
+ - "./nginx/nginx.conf:/etc/nginx/nginx.conf"
+ - "./nginx/html:/usr/share/nginx/html"
+ depends_on:
+ - hmall
+ networks:
+ - hm-net
+networks:
+ hm-net:
+ name: hmall
+```
+
+编写好docker-compose.yml文件,就可以部署项目了。常见的命令:https://docs.docker.com/compose/reference/
+
+基本语法如下:
+
+```bash
+docker compose [OPTIONS] [COMMAND]
+```
+
+其中,OPTIONS和COMMAND都是可选参数,比较常见的有:
+
+
+
+需要删除旧容器及旧镜像
+
+在root目录运行即可docker compose up -d
+
diff --git a/public/markdowns/Git.md b/public/markdowns/Git.md
new file mode 100644
index 0000000..0d2c5c7
--- /dev/null
+++ b/public/markdowns/Git.md
@@ -0,0 +1,420 @@
+---
+title: Git工具
+tags:
+ - Git
+ - 瑞吉外卖
+categories:
+ - Git
+description: Git快速入门教程
+abbrlink: a97adaa0
+---
+
+# 1、Git概述
+
+- Git是一个分布式版本控制工具,主要用于管理开发过程中的源代码文件(Java类、xml文件、html页面等),在软件开发过程中被广泛使用。
+- 作用
+ 1. 代码回溯
+ 2. 版本切换
+ 3. 多人协作
+ 4. 远程备份
+
+## 简介
+
+- Git 是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理。通过Git仓库来存储和管理这些文件,Git仓库分为两种:
+ 1. 本地仓库:开发人员自己电脑上的Git仓库
+ 2. 远程仓库:远程服务器上的Git仓库
+- `commit`:提交。将本地文件和版本信息保存到本地仓库
+- `push`:推送,将本地仓库文件和版本信息上传到远程仓库
+- `pull`:拉取,将远程仓库文件和版本信息下载到本地仓库
+
+Git一般的操作就是将本地仓库中的数据提交后推送到远程仓库上,而另一个本地仓库需要时只需要拉取一下在远程仓库上的数据即可,反之同理
+
+## 下载和安装
+
+- 这个应该没啥好说的,安装完毕之后再任意目录点击右键出现如下菜单,则说明安装成功
+
+
+
+上面这种是可以在容器存在时进行网络连接,下面这种方法可以让容器在创建时就进行连接
+我们先将之前的demo容器删除
+
+接着在创建容器时,可以添加一个参数`--network`,后面跟自定义网络的名称
+
+```bash
+docker run -d --name demo -p 8080:8080 --network eastwind docker-demo
+```
+
+```bash
+docker inspect
+```
+
+此时如果我们进入demo容器中ping mysql和nginx
+
+```bash
+docker exec -it demo bash
+ping mysql
+ping nginx
+```
+
+因为nginx与demo不在一个网段中,所以无法ping通,但mysql可以
+
+**加入自定义网络的容器才可以通过容器名互相访问**
+
+# 部署Java项目
+
+将资料中的项目打包为jar包
+
+将jar包和Dockerfile文件传入linux下
+
+```bash
+docker build -t emall .
+```
+
+查看docker 镜像是否部署成功
+
+```bash
+docker images
+```
+
+接着运行该镜像
+
+代码释义:
+
+后台运行该镜像,名称为emall,指定开放端口为8080,设置网络为eastwind,指定运行的镜像为emall
+
+```bash
+docker run -d --name emall -p 8080:8080 --network eastwind emall
+```
+
+接着可以通过查看日志
+
+```bash
+docker logs -f emall
+```
+
+访问该路径
+
+```
+http://192.168.10.142:8080/hi
+```
+
+# 部署前端
+
+修改nginx目录下的nginx.conf为
+
+这里的proxy_pass需要修改http://自己的后端镜像:8080
+
+```conf
+server {
+ listen 18080;
+ # 指定前端项目所在的位置
+ location / {
+ root /usr/share/nginx/html/hmall-portal;
+ }
+
+ error_page 500 502 503 504 /50x.html;
+ location = /50x.html {
+ root html;
+ }
+ location /api {
+ rewrite /api/(.*) /$1 break;
+ proxy_pass http://eastwind:8080;
+ }
+ }
+ server {
+ listen 18081;
+ # 指定前端项目所在的位置
+ location / {
+ root /usr/share/nginx/html/hmall-admin;
+ }
+
+ error_page 500 502 503 504 /50x.html;
+ location = /50x.html {
+ root html;
+ }
+ location /api {
+ rewrite /api/(.*) /$1 break;
+ proxy_pass http://eastwind:8080;
+ }
+ }
+```
+
+将前台的打包好的内容上传
+
+运行前台的项目
+
+命令解读:
+
+以后台模式运行一个叫nginx的容器
+
+开放端口18080和18081,并且与容器内的队友路径进行关联
+
+设置对应的网络为自定义网络eastwind
+
+设置使用的镜像为nginx
+
+```bash
+docker run -d \
+--name nginx \
+-p 18080:18080 \
+-p 18081:18081 \
+-v /root/nginx/html:/usr/share/nginx/html \
+-v /root/nginx/nginx.conf:/etc/nginx/nginx.conf \
+--network eastwind \
+nginx
+```
+
+访问http://你的虚拟机ip:18080
+
+# DockerCompose
+
+我们部署一个简单的java项目,其中包含3个容器:
+
+- MySQL
+- Nginx
+- Java项目
+
+而稍微复杂的项目,其中还会有各种各样的其它中间件,需要部署的东西远不止3个。如果还像之前那样手动的逐一部署,就太麻烦了。
+
+而Docker Compose就可以帮助我们实现**多个相互关联的Docker容器的快速部署**。它允许用户通过一个单独的 docker-compose.yml 模板文件(YAML 格式)来定义一组相关联的应用容器。
+
+## 基本语法
+
+docker-compose.yml文件的基本语法可以参考官方文档:https://docs.docker.com/compose/compose-file/compose-file-v3/
+
+docker-compose文件中可以定义多个相互关联的应用容器,每一个应用容器被称为一个服务(service)。由于service就是在定义某个应用的运行时参数,因此与`docker run`参数非常相似。
+
+举例来说,用docker run部署MySQL的命令如下:
+
+```bash
+docker run -d \
+ --name mysql \
+ -p 3306:3306 \
+ -e TZ=Asia/Shanghai \
+ -e MYSQL_ROOT_PASSWORD=123 \
+ -v ./mysql/data:/var/lib/mysql \
+ -v ./mysql/conf:/etc/mysql/conf.d \
+ -v ./mysql/init:/docker-entrypoint-initdb.d \
+ --network eastwind
+ mysql
+```
+
+如果用`docker-compose.yml`文件来定义,就是这样:
+
+```yaml
+version: "3.8"
+
+services:
+ mysql:
+ image: mysql
+ container_name: mysql
+ ports:
+ - "3306:3306"
+ environment:
+ TZ: Asia/Shanghai
+ MYSQL_ROOT_PASSWORD: 123
+ volumes:
+ - "./mysql/conf:/etc/mysql/conf.d"
+ - "./mysql/data:/var/lib/mysql"
+ networks:
+ - new
+networks:
+ new:
+ name: eastwind
+```
+
+对比如下:
+
+| **docker run 参数** | **docker compose 指令** | **说明** |
+| :------------------ | :---------------------- | :--------- |
+| --name | container_name | 容器名称 |
+| -p | ports | 端口映射 |
+| -e | environment | 环境变量 |
+| -v | volumes | 数据卷配置 |
+| --network | networks | 网络 |
+
+商城部署文件:
+
+```YAML
+version: "3.8"
+
+services:
+ mysql:
+ image: mysql
+ container_name: mysql
+ ports:
+ - "3306:3306"
+ environment:
+ TZ: Asia/Shanghai
+ MYSQL_ROOT_PASSWORD: 123
+ volumes:
+ - "./mysql/conf:/etc/mysql/conf.d"
+ - "./mysql/data:/var/lib/mysql"
+ - "./mysql/init:/docker-entrypoint-initdb.d"
+ networks:
+ - hm-net
+ hmall:
+ build:
+ context: .
+ dockerfile: Dockerfile
+ container_name: hmall
+ ports:
+ - "8080:8080"
+ networks:
+ - hm-net
+ depends_on:
+ - mysql
+ nginx:
+ image: nginx
+ container_name: nginx
+ ports:
+ - "18080:18080"
+ - "18081:18081"
+ volumes:
+ - "./nginx/nginx.conf:/etc/nginx/nginx.conf"
+ - "./nginx/html:/usr/share/nginx/html"
+ depends_on:
+ - hmall
+ networks:
+ - hm-net
+networks:
+ hm-net:
+ name: hmall
+```
+
+编写好docker-compose.yml文件,就可以部署项目了。常见的命令:https://docs.docker.com/compose/reference/
+
+基本语法如下:
+
+```bash
+docker compose [OPTIONS] [COMMAND]
+```
+
+其中,OPTIONS和COMMAND都是可选参数,比较常见的有:
+
+
+
+需要删除旧容器及旧镜像
+
+在root目录运行即可docker compose up -d
+
diff --git a/public/markdowns/Git.md b/public/markdowns/Git.md
new file mode 100644
index 0000000..0d2c5c7
--- /dev/null
+++ b/public/markdowns/Git.md
@@ -0,0 +1,420 @@
+---
+title: Git工具
+tags:
+ - Git
+ - 瑞吉外卖
+categories:
+ - Git
+description: Git快速入门教程
+abbrlink: a97adaa0
+---
+
+# 1、Git概述
+
+- Git是一个分布式版本控制工具,主要用于管理开发过程中的源代码文件(Java类、xml文件、html页面等),在软件开发过程中被广泛使用。
+- 作用
+ 1. 代码回溯
+ 2. 版本切换
+ 3. 多人协作
+ 4. 远程备份
+
+## 简介
+
+- Git 是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理。通过Git仓库来存储和管理这些文件,Git仓库分为两种:
+ 1. 本地仓库:开发人员自己电脑上的Git仓库
+ 2. 远程仓库:远程服务器上的Git仓库
+- `commit`:提交。将本地文件和版本信息保存到本地仓库
+- `push`:推送,将本地仓库文件和版本信息上传到远程仓库
+- `pull`:拉取,将远程仓库文件和版本信息下载到本地仓库
+
+Git一般的操作就是将本地仓库中的数据提交后推送到远程仓库上,而另一个本地仓库需要时只需要拉取一下在远程仓库上的数据即可,反之同理
+
+## 下载和安装
+
+- 这个应该没啥好说的,安装完毕之后再任意目录点击右键出现如下菜单,则说明安装成功
+
+ +
+一般经常使用的都是`Git Bash Here`
+
+
+
+# Git代码托管服务
+
+## 常用的Git代码托管服务
+
+- Git中存在两种类型的仓库,即`本地仓库`和`远程仓库`,那么我们如何搭建`- Git远程仓库`呢?
+- 我们可以借助互联网上提供的一些代码托管服务俩实现,比较常用的有GitHub、Gitee(狗都不用)、GitLab等
+ - `GitHub`( 地址:`https://github.com/` ),是一个面向开源私有软件项目的托管平台,因为只支持Git作为唯一的版本库格式进行托管,故名GitHub
+ - `Gitee`(地址: `https://gitee.com/` ),又名码云,是国内的一个代码托管平台,由于服务器在国内,所以相比较于GitHub,Gitee速度更快
+ - `GitLab`(地址: `https://about.gitlab.com/` ),是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的Web服务
+ - `BitBucket`(地址:`https://bitbucket.org/`) ,是一家代码托管网站,采用Mercurial和Git作为分布式版本控制系统,同时提供商业计划和免费账户
+
+## 使用GitHub代码托管服务
+
+具体步骤如下
+
+### 注册登录GitHub账号
+
+注册Github账号`https://github.com/`
+
+通过这个网址来注册github账号,注册和登录就没什么好说的了
+
+
+
+### 创建一个远程仓库
+
+
+
+右上角有一个+号,点开后New repository可以来创建远程仓库
+
+
+
+一般经常使用的都是`Git Bash Here`
+
+
+
+# Git代码托管服务
+
+## 常用的Git代码托管服务
+
+- Git中存在两种类型的仓库,即`本地仓库`和`远程仓库`,那么我们如何搭建`- Git远程仓库`呢?
+- 我们可以借助互联网上提供的一些代码托管服务俩实现,比较常用的有GitHub、Gitee(狗都不用)、GitLab等
+ - `GitHub`( 地址:`https://github.com/` ),是一个面向开源私有软件项目的托管平台,因为只支持Git作为唯一的版本库格式进行托管,故名GitHub
+ - `Gitee`(地址: `https://gitee.com/` ),又名码云,是国内的一个代码托管平台,由于服务器在国内,所以相比较于GitHub,Gitee速度更快
+ - `GitLab`(地址: `https://about.gitlab.com/` ),是一个用于仓库管理系统的开源项目,使用Git作为代码管理工具,并在此基础上搭建起来的Web服务
+ - `BitBucket`(地址:`https://bitbucket.org/`) ,是一家代码托管网站,采用Mercurial和Git作为分布式版本控制系统,同时提供商业计划和免费账户
+
+## 使用GitHub代码托管服务
+
+具体步骤如下
+
+### 注册登录GitHub账号
+
+注册Github账号`https://github.com/`
+
+通过这个网址来注册github账号,注册和登录就没什么好说的了
+
+
+
+### 创建一个远程仓库
+
+
+
+右上角有一个+号,点开后New repository可以来创建远程仓库
+
+ +
+就正常的创建就行了,下面都有这些英文解释,基本上不需要太大的变动
+
+创建完成后是这个样子
+
+
+
+就正常的创建就行了,下面都有这些英文解释,基本上不需要太大的变动
+
+创建完成后是这个样子
+
+ +
+
+
+### 邀请其他用户成为仓库成员
+
+
+
+
+
+# Git常用命令
+
+## Git全局设置
+
+安装Git后首先要做的是设置用户名称和email地址。这是非常重要的,因为每次Git提交都会使用该用户的信息
+
+
+
+在Git命令行中执行下面的命令:
+
+- 设置用户信息
+
+```bash
+git config --global user.name "你的用户名"
+```
+
+```bash
+git config --global user.email "你的邮箱"
+```
+
+- 查看配置信息
+
+```bash
+git config --list
+```
+
+- 签名的作用是为了区分不同操作者的身份
+- 用户的签名信息在每一个版本的提交信息中能够看到,以确认本次提交是谁做的
+- Git首次安装必须设置一下用户签名,否则无法提交代码
+
+注意:上面设置的user.name和user.email并不是在Github上注册的用户名和邮箱,此处可以任意设置\
+
+通过上面的命令设置的信息都保存在`~/.gitconfig`文件中
+
+## 获取Git仓库
+
+要使用Git对我们的代码进行版本控制,首先需要获得Git仓库
+
+`获取Git仓库的命令`
+
+本地初始化(不常用)
+
+```bash
+git init
+```
+
+从远程仓库克隆(常用)
+
+```bash
+git clone
+```
+
+这里给一个简单示例将远程仓库克隆过来
+
+我们创建一个文件夹暂存一下我们的Git仓库
+
+
+
+这里是我们的一个文件夹,我们右击鼠标Git Bash Here
+
+
+
+
+
+### 邀请其他用户成为仓库成员
+
+
+
+
+
+# Git常用命令
+
+## Git全局设置
+
+安装Git后首先要做的是设置用户名称和email地址。这是非常重要的,因为每次Git提交都会使用该用户的信息
+
+
+
+在Git命令行中执行下面的命令:
+
+- 设置用户信息
+
+```bash
+git config --global user.name "你的用户名"
+```
+
+```bash
+git config --global user.email "你的邮箱"
+```
+
+- 查看配置信息
+
+```bash
+git config --list
+```
+
+- 签名的作用是为了区分不同操作者的身份
+- 用户的签名信息在每一个版本的提交信息中能够看到,以确认本次提交是谁做的
+- Git首次安装必须设置一下用户签名,否则无法提交代码
+
+注意:上面设置的user.name和user.email并不是在Github上注册的用户名和邮箱,此处可以任意设置\
+
+通过上面的命令设置的信息都保存在`~/.gitconfig`文件中
+
+## 获取Git仓库
+
+要使用Git对我们的代码进行版本控制,首先需要获得Git仓库
+
+`获取Git仓库的命令`
+
+本地初始化(不常用)
+
+```bash
+git init
+```
+
+从远程仓库克隆(常用)
+
+```bash
+git clone
+```
+
+这里给一个简单示例将远程仓库克隆过来
+
+我们创建一个文件夹暂存一下我们的Git仓库
+
+
+
+这里是我们的一个文件夹,我们右击鼠标Git Bash Here
+
+ +
+这样就来到了我们的一个文件夹内
+
+我们去GitHub上面复制一下HTTPS到这来
+
+
+
+我们执行git clone "你的远程仓库地址"
+
+
+
+因为我的远程仓库是空的,所以报了一个警告,我们再到文件夹中查看
+
+
+
+这样就来到了我们的一个文件夹内
+
+我们去GitHub上面复制一下HTTPS到这来
+
+
+
+我们执行git clone "你的远程仓库地址"
+
+
+
+因为我的远程仓库是空的,所以报了一个警告,我们再到文件夹中查看
+
+ +
+此时,远程仓库就被克隆过来了
+
+注意:仓库是不能嵌套的,不能在一个仓库目录内,克隆/创建另一个仓库。
+
+## 工作区、暂存区、版本库概念
+
+为了更好的学习Git,我们需要了解一下Git相关的一些概念,这些概念在后面的学习中会经常提到。
+
+- 版本库:其实你在`git init`之后,会在当前文件夹创建一个隐藏文件`.git`,这个文件就是版本库,版本库中存储了很多的配置信息、日志信息和文件版本信息等
+- 工作目录(工作区):包含`.git`文件夹的目录就是工作目录,主要用于存放开发的代码
+- 暂存区:一个临时保存修改文件的地方
+ - `.git`文件夹内有很多文件,其中有一个名为`index`的文件就是暂存区,也可以叫做`stage`
+
+## Git工作区中文件的状态
+
+- Git工作目录下的文件存在两种状态
+ - `untracked`未跟踪(未被纳入版本控制)
+ - `tracked`已跟踪(被纳入版本控制)
+ - `Unmodified`未修改状态
+ - `Modified`已修改状态
+ - `Staged`已暂存状态
+
+这些文件的状态会随着我们执行Git的命令发生变化
+
+## 本地仓库操作
+
+## 本地仓库相关命令
+
+| 命令 | 功能 |
+| :---------------------------------: | :--------------------------------------: |
+| git config —global user.name 用户名 | 设置用户签名 |
+| git config —global user.email 邮箱 | 设置用户签名 |
+| git init | 初始化本地库 |
+| git status | 查看文件状态 |
+| git add [文件名称] | 将文件的修改加入暂存区 |
+| git reset [文件名称] | 将暂存区的文件取消暂存 |
+| git reset —hard [版本号] | 切换到指定版本 |
+| git commit [文件名] | 将暂存区文件提交到版本库中 |
+| git commit -m “日志信息” | 将暂存区文件提交到版本库中并增加日志信息 |
+| git log | 查看日志 |
+| git reflog | 查看历史记录 |
+
+### git status
+
+
+
+此时,远程仓库就被克隆过来了
+
+注意:仓库是不能嵌套的,不能在一个仓库目录内,克隆/创建另一个仓库。
+
+## 工作区、暂存区、版本库概念
+
+为了更好的学习Git,我们需要了解一下Git相关的一些概念,这些概念在后面的学习中会经常提到。
+
+- 版本库:其实你在`git init`之后,会在当前文件夹创建一个隐藏文件`.git`,这个文件就是版本库,版本库中存储了很多的配置信息、日志信息和文件版本信息等
+- 工作目录(工作区):包含`.git`文件夹的目录就是工作目录,主要用于存放开发的代码
+- 暂存区:一个临时保存修改文件的地方
+ - `.git`文件夹内有很多文件,其中有一个名为`index`的文件就是暂存区,也可以叫做`stage`
+
+## Git工作区中文件的状态
+
+- Git工作目录下的文件存在两种状态
+ - `untracked`未跟踪(未被纳入版本控制)
+ - `tracked`已跟踪(被纳入版本控制)
+ - `Unmodified`未修改状态
+ - `Modified`已修改状态
+ - `Staged`已暂存状态
+
+这些文件的状态会随着我们执行Git的命令发生变化
+
+## 本地仓库操作
+
+## 本地仓库相关命令
+
+| 命令 | 功能 |
+| :---------------------------------: | :--------------------------------------: |
+| git config —global user.name 用户名 | 设置用户签名 |
+| git config —global user.email 邮箱 | 设置用户签名 |
+| git init | 初始化本地库 |
+| git status | 查看文件状态 |
+| git add [文件名称] | 将文件的修改加入暂存区 |
+| git reset [文件名称] | 将暂存区的文件取消暂存 |
+| git reset —hard [版本号] | 切换到指定版本 |
+| git commit [文件名] | 将暂存区文件提交到版本库中 |
+| git commit -m “日志信息” | 将暂存区文件提交到版本库中并增加日志信息 |
+| git log | 查看日志 |
+| git reflog | 查看历史记录 |
+
+### git status
+
+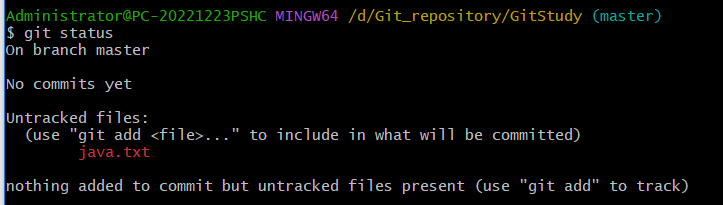 +
+### git add [文件名称]
+
+将未跟踪的文件加入到暂存区,并查看文件状态
+
+
+
+### git add [文件名称]
+
+将未跟踪的文件加入到暂存区,并查看文件状态
+
+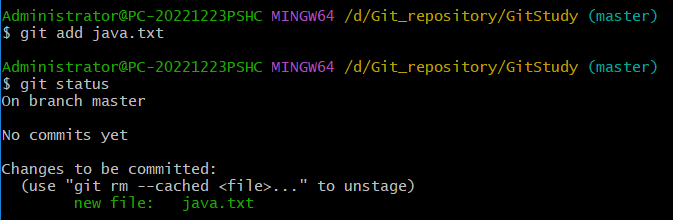 +
+此时发现暂存区就有文件了
+
+
+
+### gie reset
+
+将暂存区的文件取消暂存,并查看文件状态
+
+
+
+此时发现暂存区就有文件了
+
+
+
+### gie reset
+
+将暂存区的文件取消暂存,并查看文件状态
+
+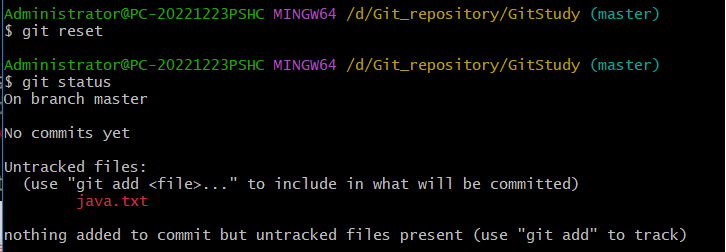 +
+### git commit -m "日志信息" [文件名]
+
+将暂存区的文件提交到版本库中
+
+- 若提交多次,会产生多个版本号
+- 使用`git log`来查看版本号
+
+
+
+### git commit -m "日志信息" [文件名]
+
+将暂存区的文件提交到版本库中
+
+- 若提交多次,会产生多个版本号
+- 使用`git log`来查看版本号
+
+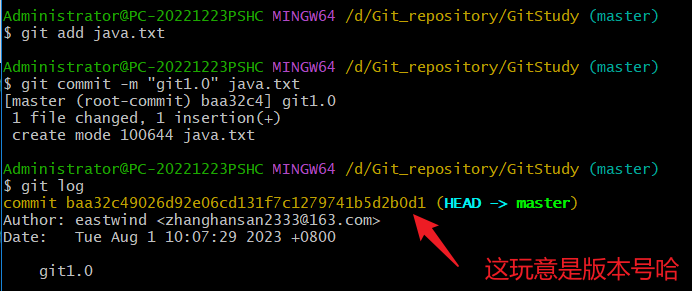 +
+提交之前需要先添加到暂存区
+
+
+
+### git reset --hard [版本号]`
+
+切换到指定版本
+
+这个版本号是`git commit`提交后在`git log`上查看的,这里就不做演示了
+
+
+
+### git rm [文件名]
+
+删除工作区文件,并查看状态,提交之后再次查看状态
+
+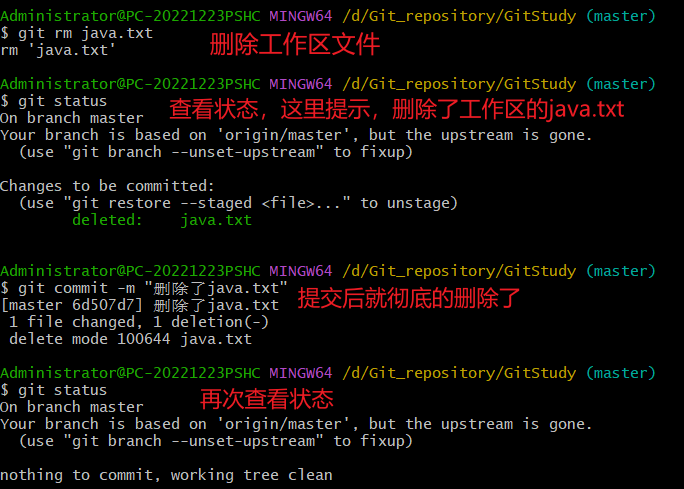
+
+删除的只是工作区的,仓库里的并没有被删除
+
+## 远程仓库操作
+
+| 命令 | 功能 |
+| :---------------------------------: | :----------------------: |
+| git remote | 查看远程仓库 |
+| git remote -v | 查看当前所有远程地址别名 |
+| git remote add [short-name] [url] | 添加远程仓库 |
+| git remote rm [short-name] | 移除远程仓库 |
+| git clone [url] | 从远程仓库克隆 |
+| git pull [short-name] [branch-name] | 从远程仓库拉取 |
+| git push [short-name] [branch-name] | 推送到远程仓库 |
+
+### git remote查看远程仓库
+
+- 如果想查看已经配置的远程仓库服务器,可以运行`git remote`命令。它会列出指定的每一个远程服务器的简写
+- 如果已经克隆了远程仓库,那么至少应该能看到`origin`,这是`Git克隆`的仓库服务器的`默认`名字
+
+### git remote -v则可以查看更为详细的信息
+
+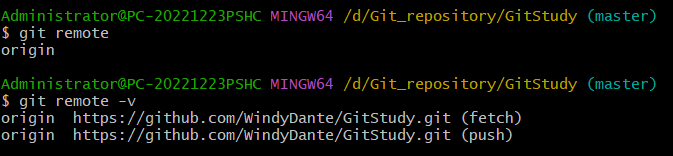
+
+### git remote add [short-name] [url]
+
+添加远程仓库,添加一个新的远程Git仓库,同时也指定搞一个可以引用的缩写
+
+- 使用`git remote -v`查看是否连接成功,成功连接之后,我们就可以向仓库推送/拉取数据了
+- 移除远程仓库,运行`git remote rm [short-name]`
+- 命令`git remote add
+
+提交之前需要先添加到暂存区
+
+
+
+### git reset --hard [版本号]`
+
+切换到指定版本
+
+这个版本号是`git commit`提交后在`git log`上查看的,这里就不做演示了
+
+
+
+### git rm [文件名]
+
+删除工作区文件,并查看状态,提交之后再次查看状态
+
+
+
+删除的只是工作区的,仓库里的并没有被删除
+
+## 远程仓库操作
+
+| 命令 | 功能 |
+| :---------------------------------: | :----------------------: |
+| git remote | 查看远程仓库 |
+| git remote -v | 查看当前所有远程地址别名 |
+| git remote add [short-name] [url] | 添加远程仓库 |
+| git remote rm [short-name] | 移除远程仓库 |
+| git clone [url] | 从远程仓库克隆 |
+| git pull [short-name] [branch-name] | 从远程仓库拉取 |
+| git push [short-name] [branch-name] | 推送到远程仓库 |
+
+### git remote查看远程仓库
+
+- 如果想查看已经配置的远程仓库服务器,可以运行`git remote`命令。它会列出指定的每一个远程服务器的简写
+- 如果已经克隆了远程仓库,那么至少应该能看到`origin`,这是`Git克隆`的仓库服务器的`默认`名字
+
+### git remote -v则可以查看更为详细的信息
+
+
+
+### git remote add [short-name] [url]
+
+添加远程仓库,添加一个新的远程Git仓库,同时也指定搞一个可以引用的缩写
+
+- 使用`git remote -v`查看是否连接成功,成功连接之后,我们就可以向仓库推送/拉取数据了
+- 移除远程仓库,运行`git remote rm [short-name]`
+- 命令`git remote add  +
+合并分支
+
+- `git merge [branch-name]`
+- 我们先在`test01`分支中添加点东西,然后再切换到`master`分支,合并分支,在`master`分支中可以看到`test01`分支中新添加的文件
+
+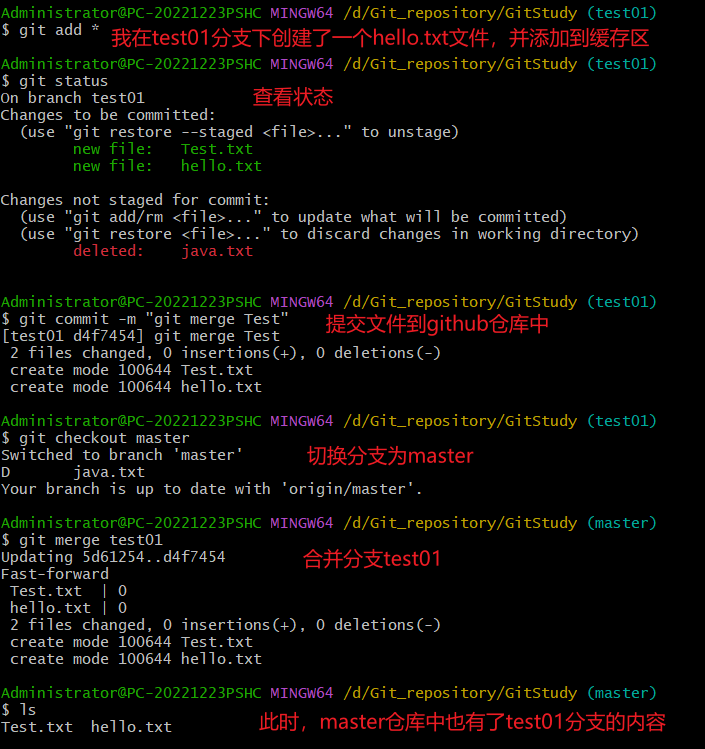
+
+合并分支的时候可能会出现冲突
+
+- 冲突产生的原因
+ - 合并分支时,两个分支在同一个文件的同一个位置有两套完全不同的修改。
+ - Git 无法替我们决定使用哪一个。必须通过手动操作来决定新代码内容。
+- 解决方案
+ - 编辑有冲突的文件,决定要使用的内容
+ - 将编辑好的文件添加到暂存区,(使用`git add`命令)
+ - 最后执行提交(注意:此时的提交只输入`git commit`,不要加文件名,或者执行`git commit [文件名] -i`)
+
+删除分支
+
+- `git branch -d [branch-name]`
+
+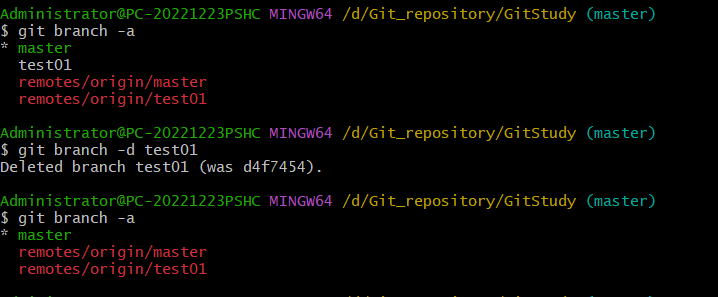
+
+## 标签操作
+
+### 简述
+
+- Git中的标签,指的是某个分支特定时间点的状态。
+- 通过标签,我们可以很方便地切换到标记时的状态(给我的感觉像是Linux的快照)
+
+### 标签操作的常用命令
+
+| 命令 | 功能 |
+| :-----------------------------: | :------------------: |
+| git tag | 创建标签 |
+| git tag [name] | 创建标签 |
+| git push [shortName] [name] | 将标签推送到远程仓库 |
+| git checkout -b [branch] [name] | 检出标签 |
+
+
+
+合并分支
+
+- `git merge [branch-name]`
+- 我们先在`test01`分支中添加点东西,然后再切换到`master`分支,合并分支,在`master`分支中可以看到`test01`分支中新添加的文件
+
+
+
+合并分支的时候可能会出现冲突
+
+- 冲突产生的原因
+ - 合并分支时,两个分支在同一个文件的同一个位置有两套完全不同的修改。
+ - Git 无法替我们决定使用哪一个。必须通过手动操作来决定新代码内容。
+- 解决方案
+ - 编辑有冲突的文件,决定要使用的内容
+ - 将编辑好的文件添加到暂存区,(使用`git add`命令)
+ - 最后执行提交(注意:此时的提交只输入`git commit`,不要加文件名,或者执行`git commit [文件名] -i`)
+
+删除分支
+
+- `git branch -d [branch-name]`
+
+
+
+## 标签操作
+
+### 简述
+
+- Git中的标签,指的是某个分支特定时间点的状态。
+- 通过标签,我们可以很方便地切换到标记时的状态(给我的感觉像是Linux的快照)
+
+### 标签操作的常用命令
+
+| 命令 | 功能 |
+| :-----------------------------: | :------------------: |
+| git tag | 创建标签 |
+| git tag [name] | 创建标签 |
+| git push [shortName] [name] | 将标签推送到远程仓库 |
+| git checkout -b [branch] [name] | 检出标签 |
+
+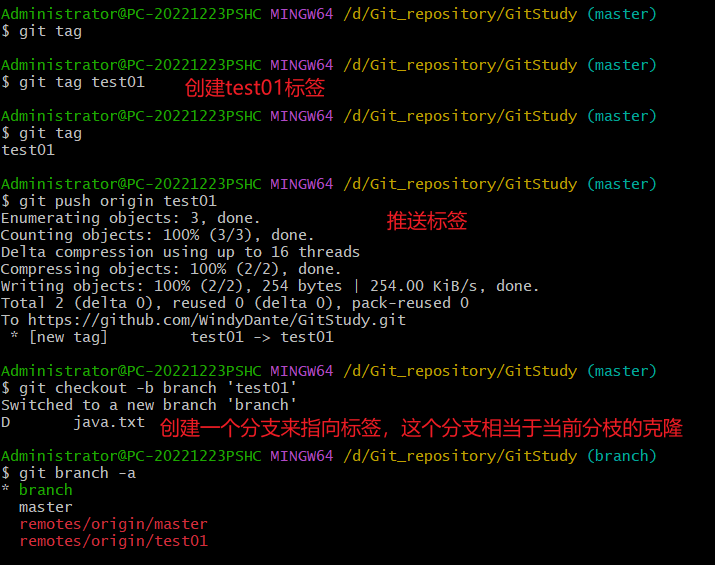 +
+分支与标签的区别
+
+- `标签` 是一个`静态`的概念,一旦标签确定后,其中的文件的状态就确定了。
+- `分支` 是一个`动态`的概念,其中的文件的状态可以发生变化。
+
+# 在IDEA中使用Git
+
+- 在IDEA中使用Git,其实也是用的我们自己安装的Git
+- 在 IDEA 中使用 Git 获取仓库有两种方式:
+ 1. 本地初始仓库
+ - 选择VCS选项卡 —> 创建Git仓库 —> 选择需要被Git管理的目录 —> 确定
+ 2. 从远程仓库克隆(常用)
+ - 这个可以自己选择克隆的本地位置
+ - 可以直接把远程仓库的代码都克隆到本地
+ - 远程克隆下来的项目会自带一个文件:`.gitignore`文件,在里面的信息是代表哪些文件不需要交给git管理
+
+关于本地仓库操作、远程仓库操作、分支操作,IDEA都给我们提供了图形化界面,方便我们使用,这里就不再展开说明了,不太明白的地方可以上百度搜搜
diff --git "a/public/markdowns/MyBatis-Plus\344\273\243\347\240\201\347\224\237\346\210\220\345\231\250.md" "b/public/markdowns/MyBatis-Plus\344\273\243\347\240\201\347\224\237\346\210\220\345\231\250.md"
new file mode 100644
index 0000000..fd9bdeb
--- /dev/null
+++ "b/public/markdowns/MyBatis-Plus\344\273\243\347\240\201\347\224\237\346\210\220\345\231\250.md"
@@ -0,0 +1,139 @@
+---
+title: MyBatis-Plus代码生成器
+tags:
+ - MyBatis-Plus
+ - 实用工具
+categories:
+ - 实用工具
+description: Git快速入门教程
+abbrlink: ced26210
+date: 2023-08-19 13:18:36
+---
+
+`MyBatis-Plus-Generator`:自动生成 Controller Service Mapper/DAO层等的基本代码,免去自己去写实体类映射数据库的繁琐操作
+
+
+
+# 添加依赖
+
+```xml
+
+
+
+
+分支与标签的区别
+
+- `标签` 是一个`静态`的概念,一旦标签确定后,其中的文件的状态就确定了。
+- `分支` 是一个`动态`的概念,其中的文件的状态可以发生变化。
+
+# 在IDEA中使用Git
+
+- 在IDEA中使用Git,其实也是用的我们自己安装的Git
+- 在 IDEA 中使用 Git 获取仓库有两种方式:
+ 1. 本地初始仓库
+ - 选择VCS选项卡 —> 创建Git仓库 —> 选择需要被Git管理的目录 —> 确定
+ 2. 从远程仓库克隆(常用)
+ - 这个可以自己选择克隆的本地位置
+ - 可以直接把远程仓库的代码都克隆到本地
+ - 远程克隆下来的项目会自带一个文件:`.gitignore`文件,在里面的信息是代表哪些文件不需要交给git管理
+
+关于本地仓库操作、远程仓库操作、分支操作,IDEA都给我们提供了图形化界面,方便我们使用,这里就不再展开说明了,不太明白的地方可以上百度搜搜
diff --git "a/public/markdowns/MyBatis-Plus\344\273\243\347\240\201\347\224\237\346\210\220\345\231\250.md" "b/public/markdowns/MyBatis-Plus\344\273\243\347\240\201\347\224\237\346\210\220\345\231\250.md"
new file mode 100644
index 0000000..fd9bdeb
--- /dev/null
+++ "b/public/markdowns/MyBatis-Plus\344\273\243\347\240\201\347\224\237\346\210\220\345\231\250.md"
@@ -0,0 +1,139 @@
+---
+title: MyBatis-Plus代码生成器
+tags:
+ - MyBatis-Plus
+ - 实用工具
+categories:
+ - 实用工具
+description: Git快速入门教程
+abbrlink: ced26210
+date: 2023-08-19 13:18:36
+---
+
+`MyBatis-Plus-Generator`:自动生成 Controller Service Mapper/DAO层等的基本代码,免去自己去写实体类映射数据库的繁琐操作
+
+
+
+# 添加依赖
+
+```xml
+
+
+ +
+点击创建一个工作空间
+
+
+
+点击创建一个工作空间
+
+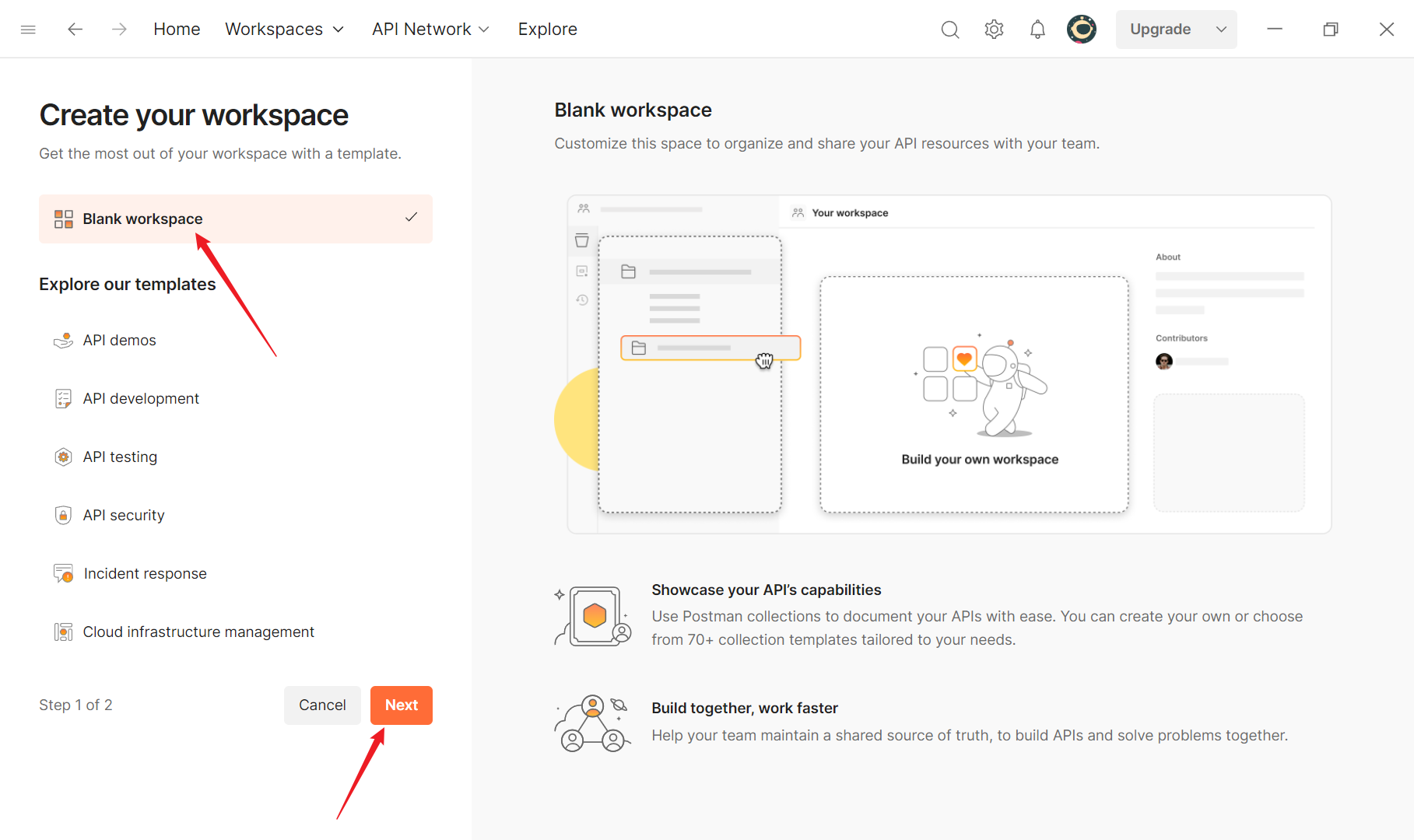 +
+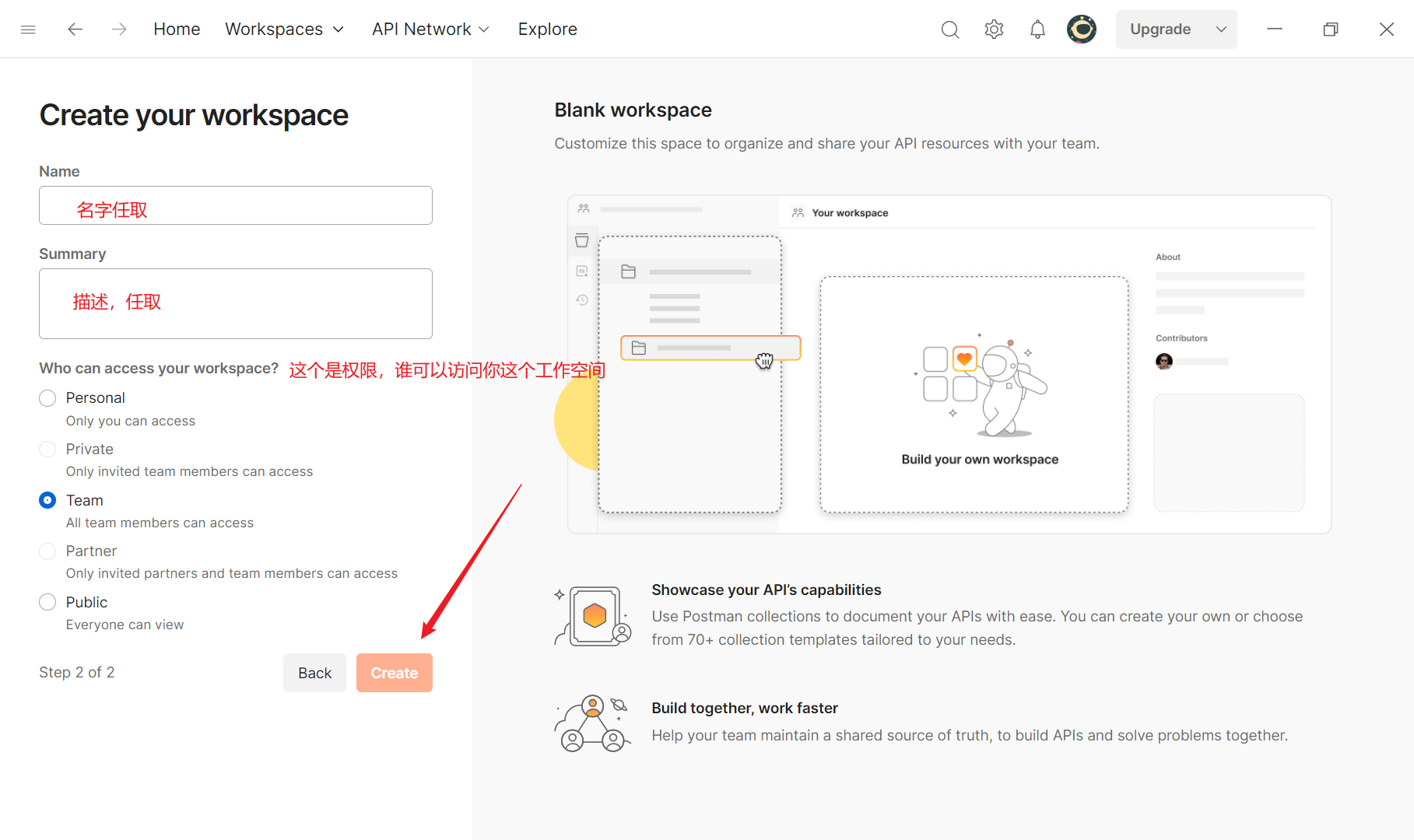
+
+创建完成后会来到如下页面
+
+点击这个按钮会新建一个连接
+
+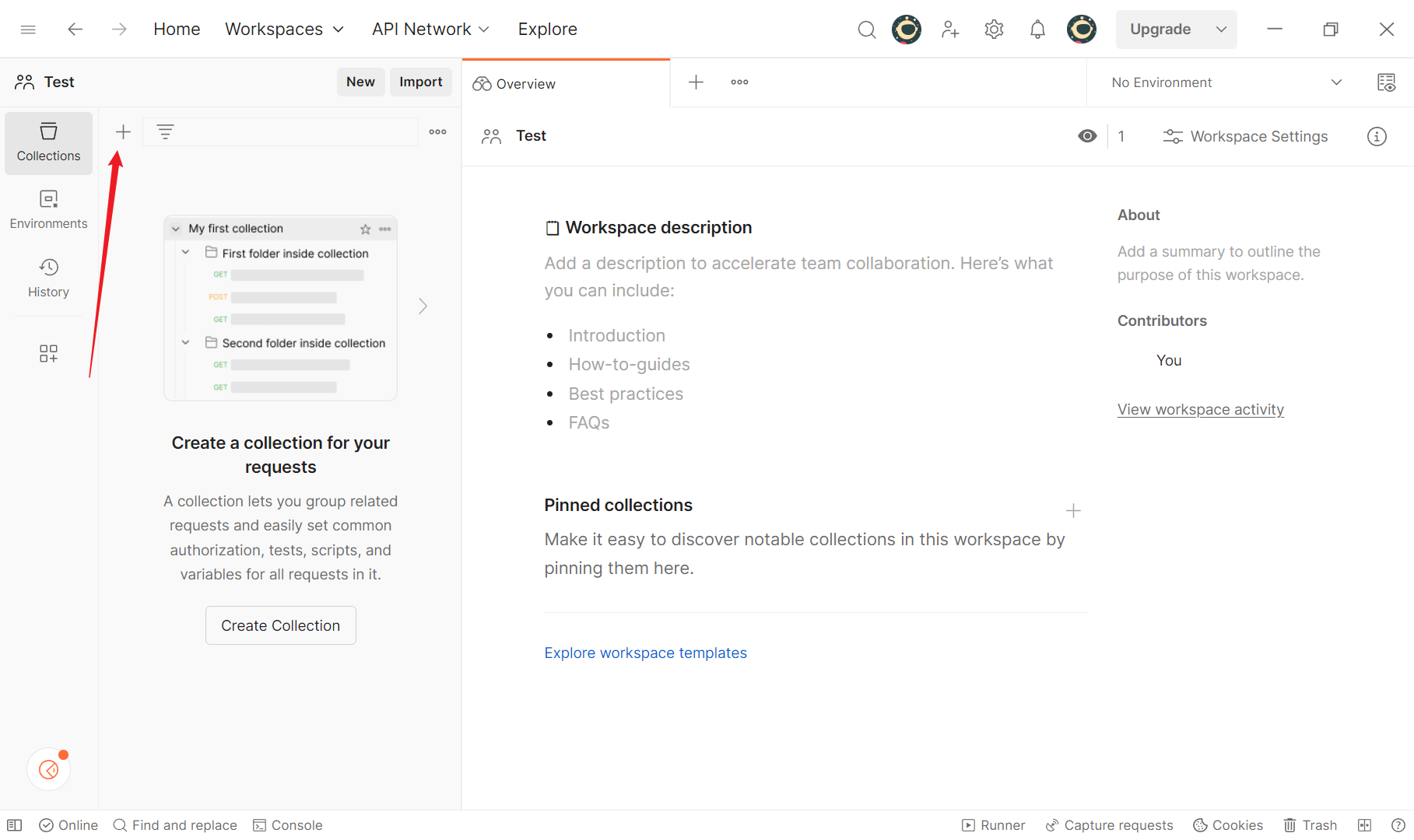
+
+右击这个按钮,添加一个请求
+
+
+
+
+
+创建完成后会来到如下页面
+
+点击这个按钮会新建一个连接
+
+
+
+右击这个按钮,添加一个请求
+
+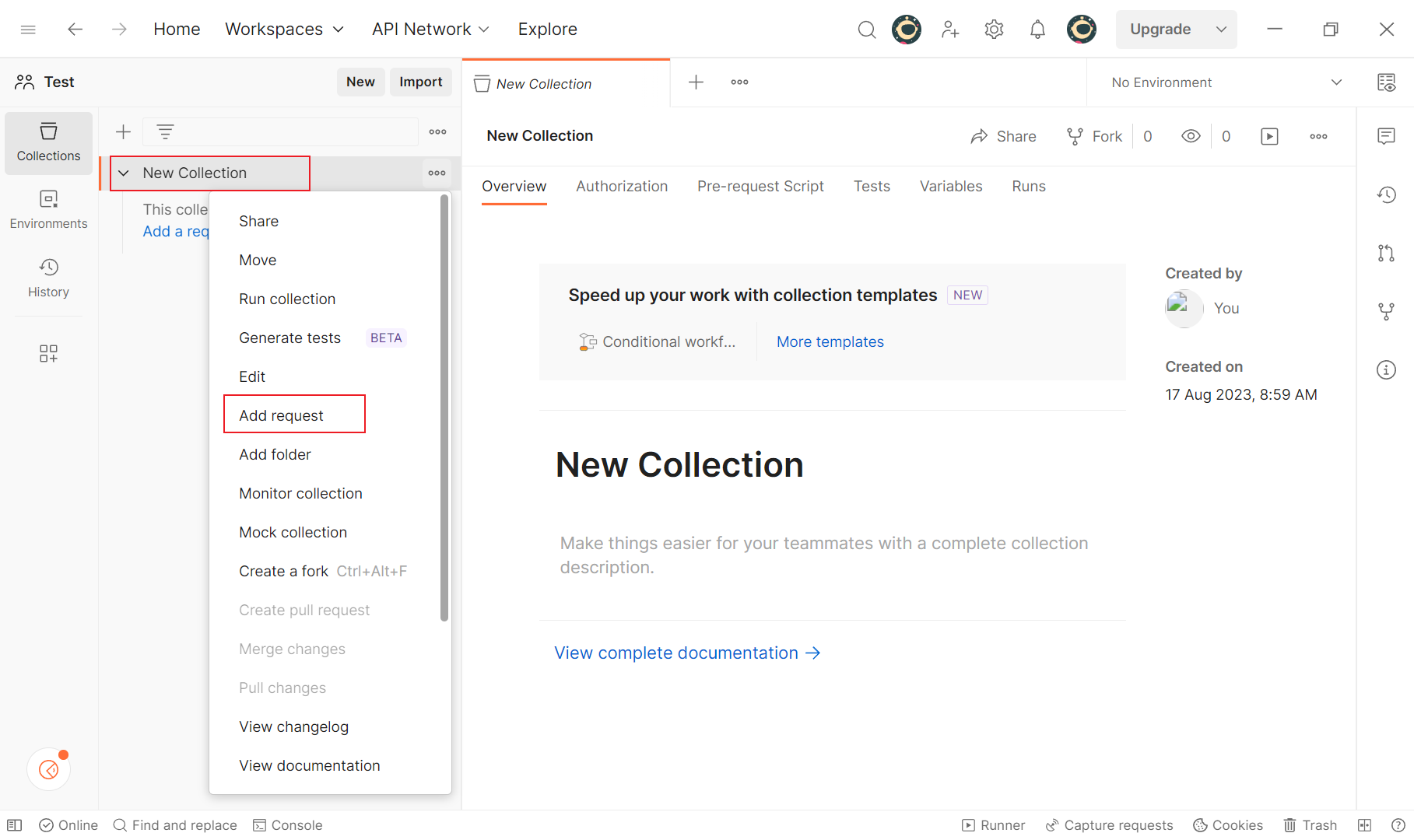 +
+默认是get请求,你可以根据自己的需求来确定
+
+
+
+
+
+# 常见的连接方式
+
+讲一下常见的几种连接参数
+
+## Get请求
+
+一般把地址拷贝到地址栏里就可以了,下面的Response是响应的内容
+
+
+
+默认是get请求,你可以根据自己的需求来确定
+
+
+
+
+
+# 常见的连接方式
+
+讲一下常见的几种连接参数
+
+## Get请求
+
+一般把地址拷贝到地址栏里就可以了,下面的Response是响应的内容
+
+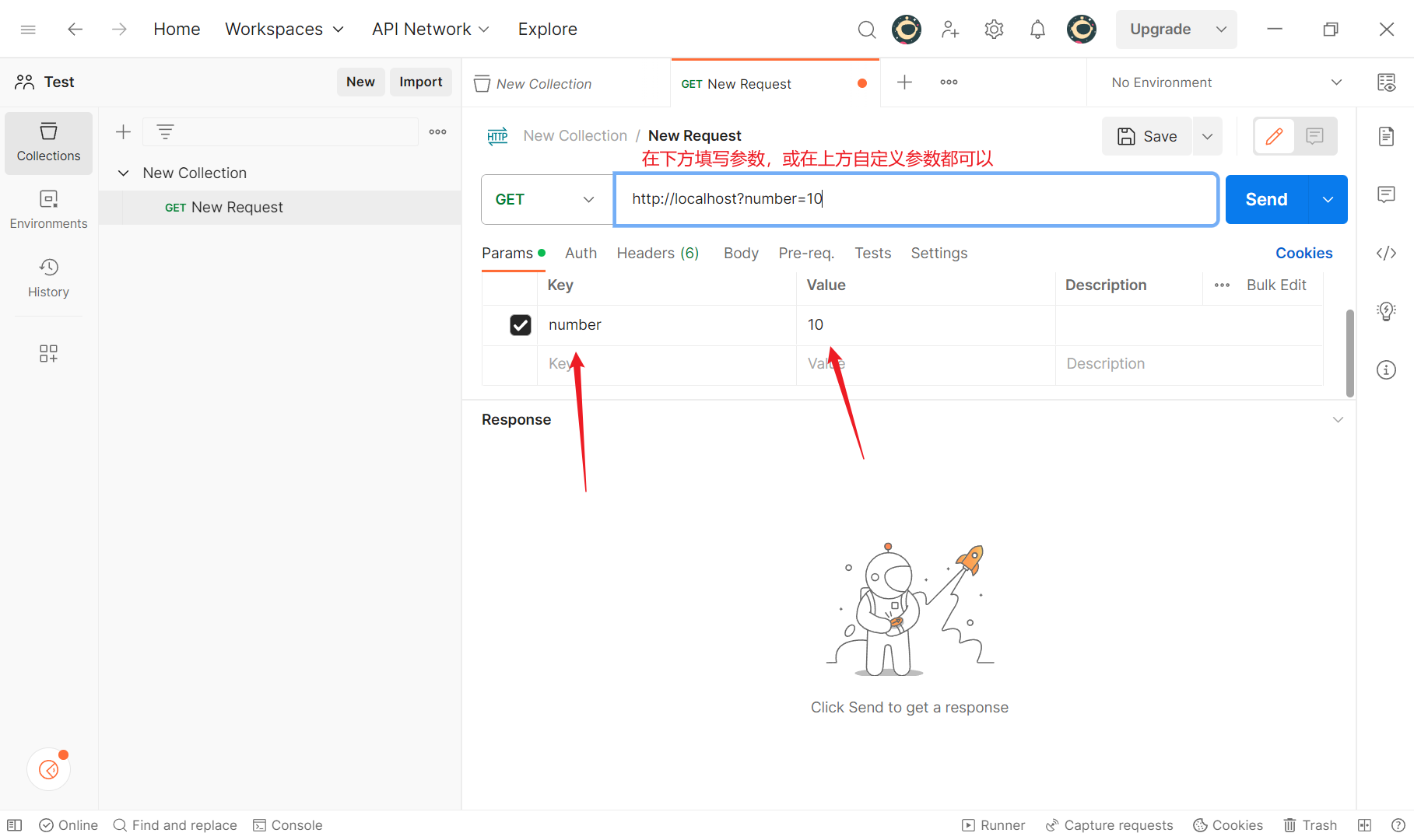 +
+## Post请求
+
+### 表单类型的接口请求
+
+表单类型数据其实就是在请求头中查看Content-Type,它的值如果是:application/x-www-form-urlencoded ,那么就说明客户端提交的数据是以表单形式提交的,这里一般发送的都是表单类的请求测试
+
+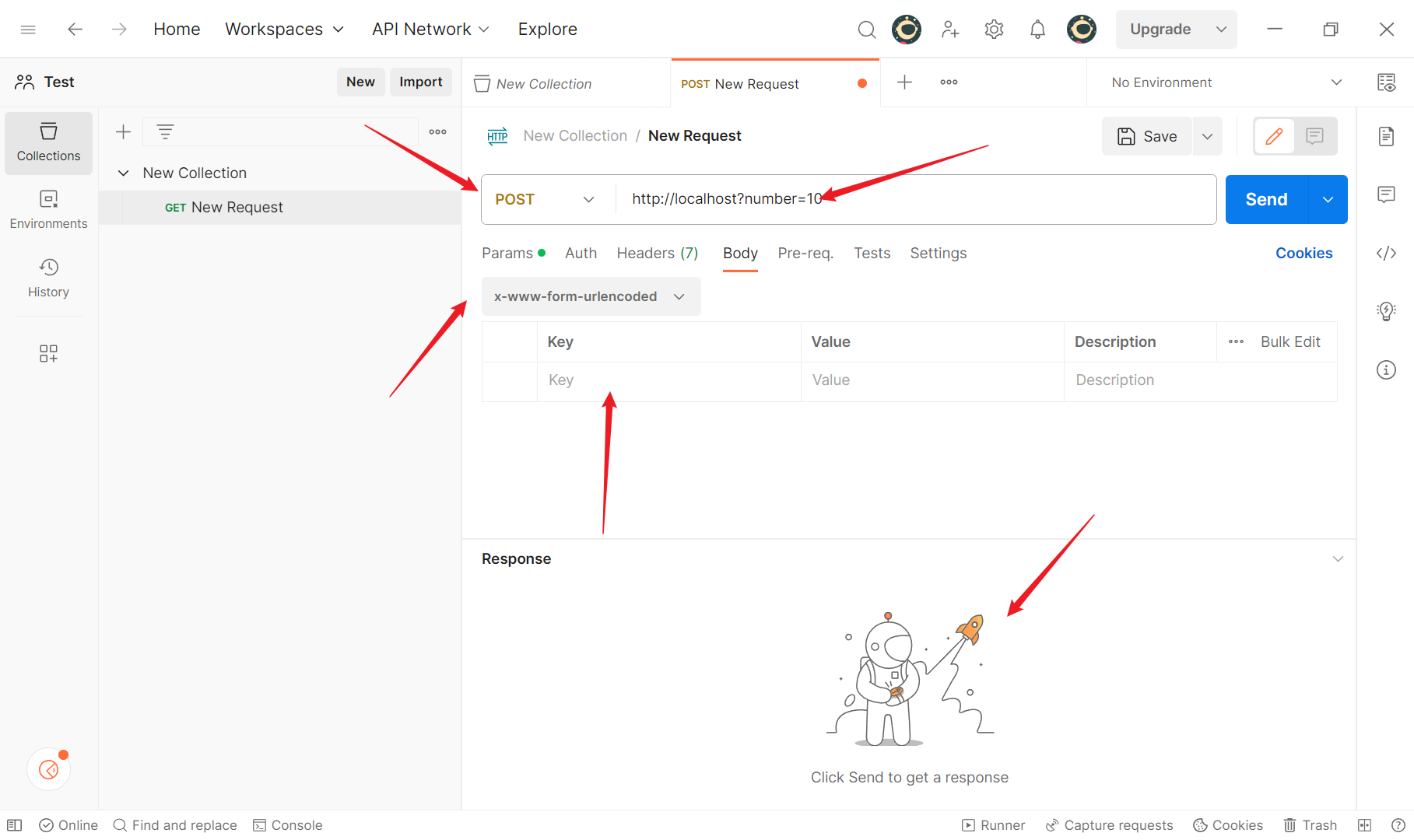
+
+### 上传文件的表单请求
+
+跟表单数据差不多,其实就是将x-www-form-urlencoded改为了form-data,可以携带的参数由Text变为File,File的Value就可以选择文件了
+
+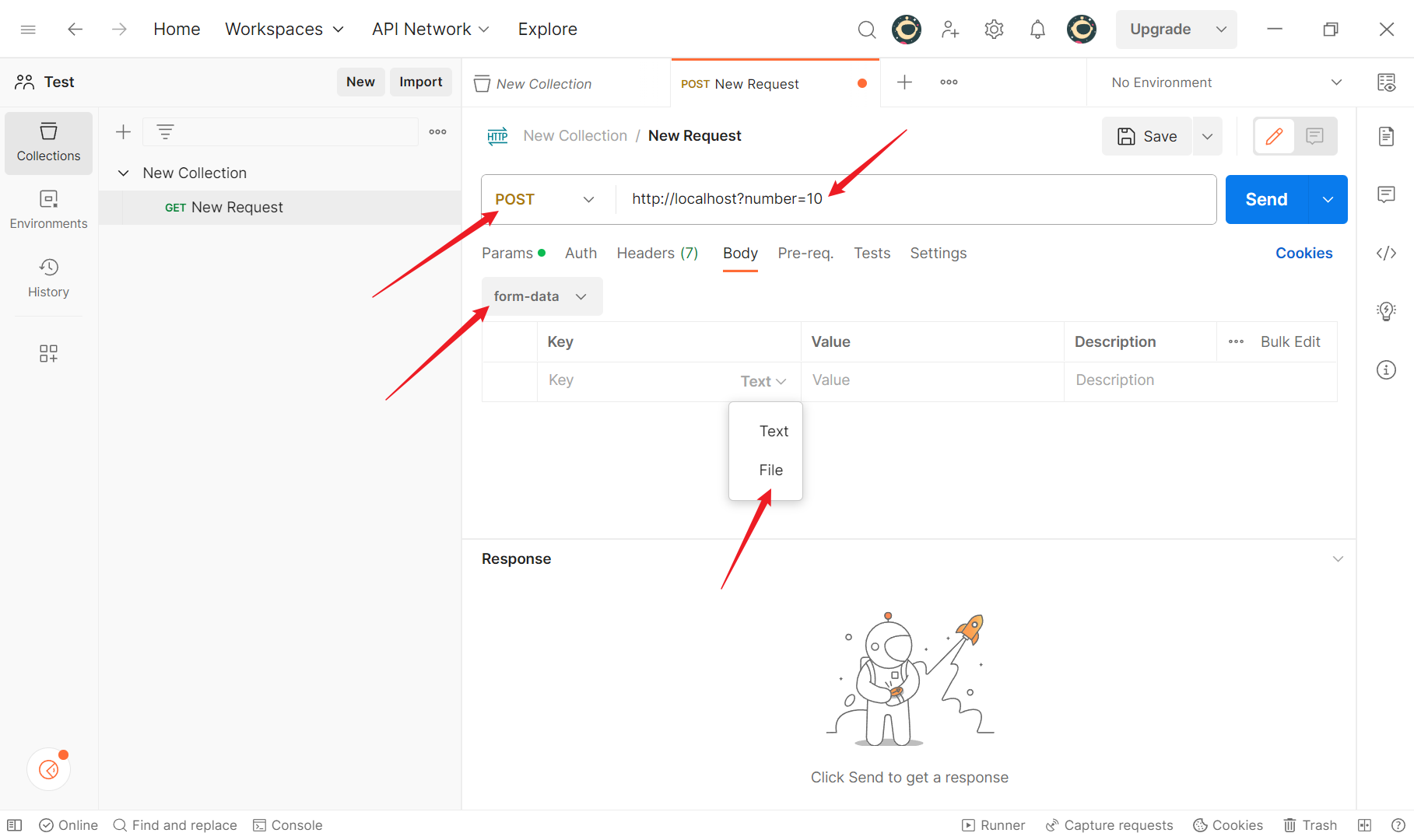
+
+### json类型的接口请求
+
+都没啥区别,其实还是跟上面的类似,只需要简单的变动一下参数
+
+
+
+## Post请求
+
+### 表单类型的接口请求
+
+表单类型数据其实就是在请求头中查看Content-Type,它的值如果是:application/x-www-form-urlencoded ,那么就说明客户端提交的数据是以表单形式提交的,这里一般发送的都是表单类的请求测试
+
+
+
+### 上传文件的表单请求
+
+跟表单数据差不多,其实就是将x-www-form-urlencoded改为了form-data,可以携带的参数由Text变为File,File的Value就可以选择文件了
+
+
+
+### json类型的接口请求
+
+都没啥区别,其实还是跟上面的类似,只需要简单的变动一下参数
+
+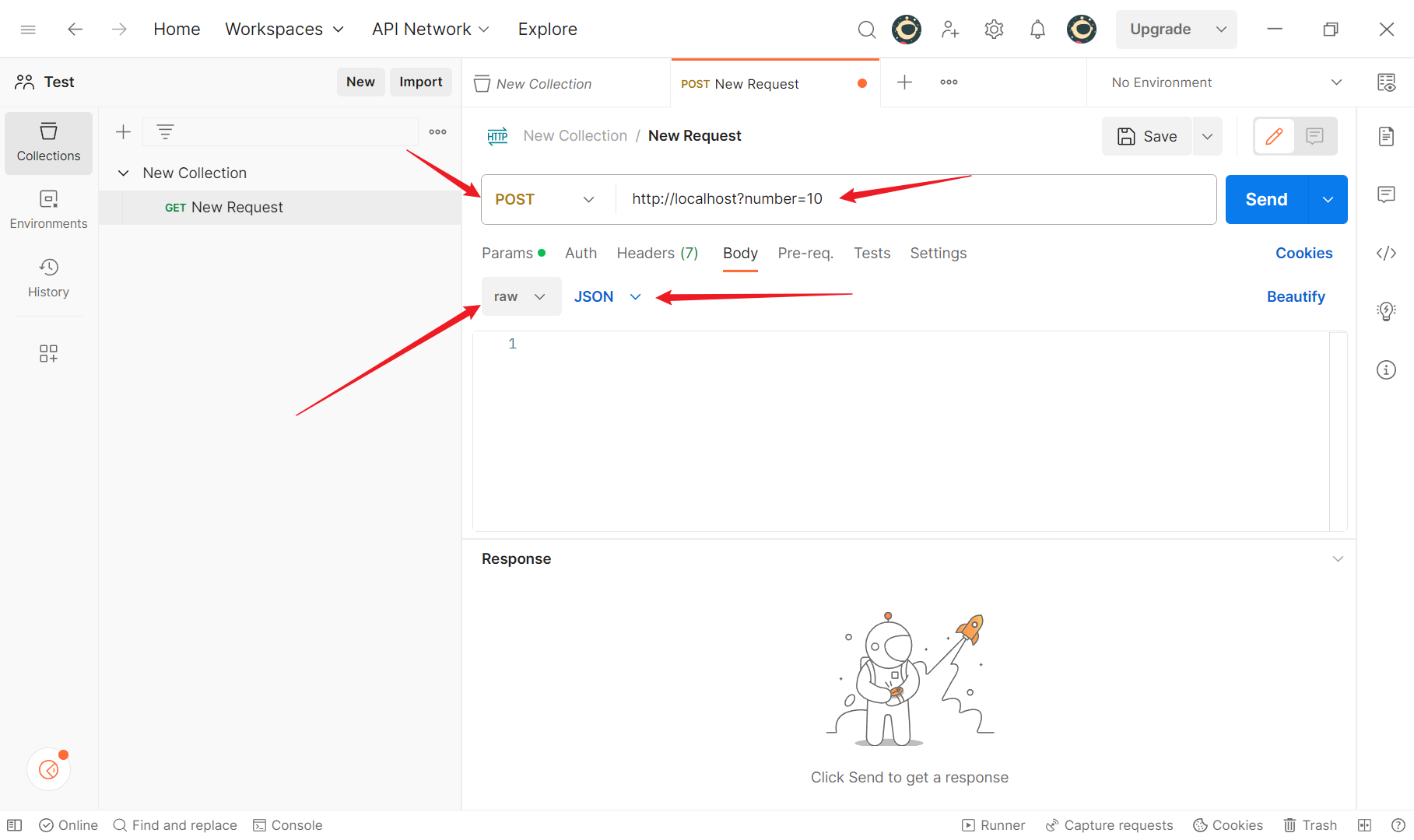 diff --git "a/public/markdowns/Redis\345\205\245\351\227\250.md" "b/public/markdowns/Redis\345\205\245\351\227\250.md"
new file mode 100644
index 0000000..8e3f2a4
--- /dev/null
+++ "b/public/markdowns/Redis\345\205\245\351\227\250.md"
@@ -0,0 +1,746 @@
+---
+title: Redis入门
+tags:
+ - Redis
+ - 瑞吉外卖
+categories:
+ - Redis
+description: Redis的快速入门教程
+abbrlink: 6a343b7f
+---
+
+# Redis入门
+
+- Redis是一个基于内存的`key-value`结构数据库
+ - 基于内存存储,读写性能高
+ - 适合存储热点数据(热点商品、咨询、新闻)
+- 官网:`https://redis.io/`
+
+
+
+# Redis的简介
+
+- Redis是用C语言开发的一个开源的、高性能的键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化NoSql数据库
+
+- NoSql(Not Only Sql),不仅仅是SQL,泛指非关系型数据库,NoSql数据库并不是要取代关系型数据库,而是关系型数据库的补充
+
+ 关系型数据库(RDBMS):MySQL、Oracl、DB2、SQLServer
+ 非关系型数据库(NoSql):Redis、Mongo DB、MemCached
+
+- Redis应用场景:缓存、消息队列、任务队列、分布式锁
+
+
+
+## 下载与安装
+
+- 这里我们在Linux和Windows上都装一下
+ - Windows 版:`https://github.com/microsoftarchive/redis/releases`
+ - Linux 版:`https://download.redis.io/releases/`
+
+### Windows安装Redis
+
+- 直接下载对应版本的`.zip`压缩包,直接解压
+
+
+
+### Linux安装Redis
+
+- Linux系统安装Redis步骤:
+
+ 1. 将Redis安装包上传到Linux
+
+ 2. 解压安装包,改成自己的redis版本
+
+ ```bash
+ tar -zxvf redis-4.0.0.tar.gz -C /usr/local/
+ ```
+
+ 3. 安装Redis的依赖环境gcc
+
+ ```bash
+ # 安装依赖环境
+ yum install gcc-c++
+ ```
+
+ 4. 进入`/usr/local/redis根目录`,进行编译
+
+ ```bash
+ # 进入到根目录
+ cd /usr/local/redis根目录
+
+ # 编译
+ make
+ ```
+
+ 5. 进入redis的src目录,进行安装
+
+ ```bash
+ # 进入到src目录
+ cd /usr/local/redis根目录/src
+ # 进行安装
+ make install
+ ```
+
+
+
+## 服务启动与停止
+
+### Linux启动与停止
+
+- 进入到`/src`目录下,执行`redis-server`即可启动服务,默认端口号为`6379`
+
+```bash
+# 进入到根目录
+cd /usr/local/redis/src
+
+# 执行redis-server
+./redis-server
+```
+
+
+
+### Linux设置后台运行
+
+进入到redis根目录下,修改配置redis.conf文件
+
+```bash
+# 进入到redis根目录下
+cd /usr/local/redis
+
+# 修改配置文件
+vim redis.conf
+```
+
+找到`daemonize no`字段,将其修改为`daemonize yes`
+
+在redis根目录以redis.conf作为配置文件在后台运行
+
+```bash
+src/redis-server ./redis.conf
+```
+
+
+
+### Linux开启密码校验
+
+- 还是修改redis.conf配置文件,找到`requirepass`这行,将其注释去掉,并在后面写上自己的密码
+- 然后杀掉原进程再重新启动
+
+
+
+```bash
+# 重新启动
+src/redis-server ./redis.conf
+
+# 登录时同时进行认证(连接的是cli客户端服务,-h是本地服务,-p设置的是端口号,-a是auth也相当于密码)
+src/redis-cli -h localhost -p 6379 -a 密码
+```
+
+修改完毕之后还是杀进程,然后重启服务
+
+
+
+
+
+### Linux开启远程连接
+
+- 还是修改redis.conf配置文件,找到`bind 127.0.0.1`这行,把这行注释掉,这一行是让我们本地进行连接的,注释之后就是开启了远程连接
+- 之后设置防火墙,开启6379端口
+- 杀死进程,并重新启动服务
+
+```bash
+# 开启6379端口
+firewall-cmd --zone=public --add-port=6379/tcp --permanent
+
+# 设置立即生效
+firewall-cmd --reload
+
+# 查看开放的端口
+firewall-cmd --zone=public --list-ports
+```
+
+最后在Windows的redis根目录下,按住Shift+右键打开PowerShell窗口,连接Linux的Redis
+
+```bash
+.\redis-cli.exe -h 虚拟机的ip地址 -p 6379 -a 密码
+```
+
+
+
+# Redis数据类型
+
+## 介绍
+
+Redis存储的是key-value结构的数据,其中key是字符串类型,value有五种常用的数据类型
+
+- 字符串 string(普通字符串,常用)
+- 哈希 hash(hash适合存储对象)
+- 列表 list(list按照插入顺序排序,可以有重复元素)
+- 集合 set(无序集合,没有重复元素)
+- 有序集合 sorted set(有序集合,没有重复元素)
+
+
+
+## Redis常用命令
+
+### 字符串string操作命令
+
+| 命令 | 描述 |
+| :---------------------: | :---------------------------------------------: |
+| SET key value | 设置指定key的值 |
+| GET key | 获取指定key的值 |
+| SETEX key seconds value | 设置指定key的值,并将key的过期时间设为seconds秒 |
+| SETNX key value | 只有在key不存在时设置key的值 |
+
+#### 操作命令示例:
+
+```bash
+127.0.0.1:6379> set name 666
+OK
+127.0.0.1:6379> get name
+"666"
+127.0.0.1:6379> setex name2 3 888
+OK
+127.0.0.1:6379> get name2
+(nil)
+127.0.0.1:6379> setnx name2 888
+(integer) 1
+127.0.0.1:6379> setnx name2 555
+(integer) 0
+127.0.0.1:6379> keys *
+1) "name2"
+2) "name"
+127.0.0.1:6379> get name2
+"888"
+```
+
+### 哈希hash操作命令
+
+`Redis Hash`是一个`String`类型的`Field`和`Value`的映射表,`Hash`特别适合用于存储对象
+
+| 命令 | 描述 |
+| :------------------: | :------------------------------------: |
+| HSET key field value | 将哈希表key 中的字段field的值设为value |
+| HGET key field | 获取存储在哈希表中指定字段的值 |
+| HDEL key field | 删除存储在哈希表中的指定字段 |
+| HKEYS key | 获取哈希表中所有字段 |
+| HVALS key | 获取哈希表中所有值 |
+| HGETALL key | 获取在哈希表中指定key的所有字段和值 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> hset table1 name wangwu // 设置table1表中的name字段值为wangwu
+(integer) 1
+127.0.0.1:6379> hget table1 name // 获取存储在table1表中的name字段
+"wangwu"
+127.0.0.1:6379> hdel table1 name // 删除存储在table1表中的name字段
+(integer) 1
+127.0.0.1:6379> hget table1 name // 此时已经被删除了,得到的是nil
+(nil)
+127.0.0.1:6379> hset table1 name lisi // 设置table1表中的name字段值为lisi
+(integer) 1
+127.0.0.1:6379> hset table1 age 10 // 设置table1表中的age字段值为10
+(integer) 1
+127.0.0.1:6379> hkeys table1 // 获取哈希表中所有字段
+1) "name"
+2) "age"
+127.0.0.1:6379> hvals table1 // 获取哈希表中所有值
+1) "wangwu"
+2) "10"
+127.0.0.1:6379> hgetall table1 // 获取在哈希表中指定key的所有字段和值
+1) "name"
+2) "wangwu"
+3) "age"
+4) "10"
+```
+
+
+
+### 列表list操作命令
+
+`Redis List`是简单的字符串列表,按照插入顺序排序
+
+| 命令 | 描述 |
+| :-------------------------: | :----------------------------------------------------------: |
+| `LPUSH` key value1 [value2] | 将一个或多个值插入到列表头部 |
+| `LRANGE` key start stop | 获取列表指定范围内的元素 |
+| `RPOP` key | 移除并获取列表最后一个元素 |
+| `LLEN` key | 获取列表长度 |
+| `BRPOP` key1 [key2] timeout | 移出并获取列表的最后一个元素 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> lpush list a b c // 将a、b、c插入到列表头部
+(integer) 3
+127.0.0.1:6379> lrange list 0 -1 // 查询从0到-1位置的元素,-1表示最后一个值
+1) "c" // c在最前面是因为列表是按照插入顺序排序的,最后插入的在最前面
+2) "b"
+3) "a"
+127.0.0.1:6379> rpop list // 删除最后一个元素,并得到值,a是最先插入的,所以是最后一个
+"a"
+127.0.0.1:6379> llen list // 获取长度
+(integer) 2
+127.0.0.1:6379> brpop list 3 // 移除列表的最后一个元素,如果列表没有值,会阻塞timeout秒,否则删除
+1) "list"
+2) "b"
+127.0.0.1:6379> brpop list 3
+1) "list"
+2) "c"
+127.0.0.1:6379> brpop list 3 // 阻塞3秒
+(nil)
+(3.09s)
+```
+
+### 集合set操作命令
+
+`Redis set`是`String`类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据
+概念和数学中的集合概念基本一致
+
+| 命令 | 描述 |
+| :------------------------: | :----------------------: |
+| SADD key member1 [member2] | 向集合添加一个或多个成员 |
+| SMEMBERS key | 返回集合中的所有成员 |
+| SCARD key | 获取集合的成员数 |
+| SINTER key1 [key2] | 返回给定所有集合的交集 |
+| SUNION key1 [key2] | 返回所有给定集合的并集 |
+| SDIFF key1 [key2] | 返回给定所有集合的差集 |
+| SREM key member1 [member2] | 移除集合中一个或多个成员 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> sadd set a a b b c d // 向set集合添加a、a、b、b、c、d
+(integer) 4
+127.0.0.1:6379> smembers set // 由于集合的唯一性,所以,只有a、b、c、d
+1) "d"
+2) "c"
+3) "b"
+4) "a"
+127.0.0.1:6379> scard set // 获取长度
+(integer) 4
+127.0.0.1:6379> srem set a b c // 删除集合中指定的对象
+(integer) 3
+127.0.0.1:6379> smembers set
+1) "d"
+```
+
+### 有序集合sorted set常用命令
+
+`Redis Sorted Set`有序集合是`String`类型元素的集合,且不允许重复的成员。每个元素都会关联一个`double`类型的分数(`score`) 。`Redis`正是通过分数来为集合中的成员进行从小到大排序。有序集合的成员是唯一的,但分数却可以重复。
+
+| 命令 | 描述 |
+| :--------------------------------------: | :----------------------------------------------------: |
+| ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
+| ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合中指定区间内的成员 |
+| ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量increment |
+| ZREM key member [member …] | 移除有序集合中的一个或多个成员 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> zadd sortset 3 a 1 c 2 b // 向集合sortset添加值与分数
+(integer) 3
+127.0.0.1:6379> zrange sortset 0 -1 // 查询,按照分数从小到大排序,最小的在最前面
+1) "c"
+2) "b"
+3) "a"
+127.0.0.1:6379> zincrby sortset 3 c // 为字段c加3分
+"4"
+127.0.0.1:6379> zrange sortset 0 -1 // 查询,此时c>a>b在最下面
+1) "b"
+2) "a"
+3) "c"
+127.0.0.1:6379> zrem sortset a b c // 删除有序集合元素
+(integer) 3
+127.0.0.1:6379> zrange sortset 0 -1
+(empty list or set)
+127.0.0.1:6379>
+```
+
+### 通用命令
+
+针对key来操作
+
+| 命令 | 描述 |
+| :----------: | :------------------------------------------------------: |
+| KEYs pattern | 查找所有符合给定模式(pattern)的key |
+| EXISTs key | 检查给定key是否存在 |
+| TYPE key | 返回key所储存的值的类型 |
+| TTL key | 返回给定key的剩余生存时间(TTL, time to live),以秒为单位 |
+| DEL key | 该命令用于在key存在是删除key |
+
+```bash
+127.0.0.1:6379> keys * // 查看所有的key
+1) "name"
+2) "table2"
+3) "table1"
+4) "NewName"
+5) "set"
+127.0.0.1:6379> exists name // 查看某个key是否存在,存在返回1,不存在返回0
+(integer) 1
+127.0.0.1:6379> exists abc
+(integer) 0
+127.0.0.1:6379> type name // 查看key的类型
+string
+127.0.0.1:6379> type set
+set
+127.0.0.1:6379> type table1
+hash
+127.0.0.1:6379> ttl name // 查看key的剩余存活时间,-1表示永久存活
+(integer) -1
+127.0.0.1:6379> setex test 10 test // 设置test字段存活时间10s,值为test
+OK
+127.0.0.1:6379> ttl test // 查看test
+(integer) 8
+127.0.0.1:6379> ttl test
+(integer) 2
+127.0.0.1:6379> keys * // 查看所有key
+1) "name"
+2) "table2"
+3) "table1"
+4) "NewName"
+5) "set"
+127.0.0.1:6379> del name // 删除name字段
+(integer) 1
+127.0.0.1:6379> keys * // 查看所有key,此时name字段就不存在了
+1) "table2"
+2) "table1"
+3) "NewName"
+4) "set"
+```
+
+
+
+# 在Java中使用Redis
+
+## 简介
+
+- Redis的Java客户端有很多,官方推荐的有三种
+ - `Jedis`
+ - `Lettuce`
+ - `Redisson`
+- Spring对Redis客户端进行了整合,提供了SpringDataRedis,在Spring Boot项目中还提供了对应的Starter,即`spring-boot-starter-data-redis`
+
+
+
+## Jedis
+
+- 使用Jedis的步骤
+ 1. 获取连接
+ 2. 执行操作
+ 3. 关闭连接
+- 在此之前我们需要导入一下Jedis的maven坐标
+
+```xml
+
diff --git "a/public/markdowns/Redis\345\205\245\351\227\250.md" "b/public/markdowns/Redis\345\205\245\351\227\250.md"
new file mode 100644
index 0000000..8e3f2a4
--- /dev/null
+++ "b/public/markdowns/Redis\345\205\245\351\227\250.md"
@@ -0,0 +1,746 @@
+---
+title: Redis入门
+tags:
+ - Redis
+ - 瑞吉外卖
+categories:
+ - Redis
+description: Redis的快速入门教程
+abbrlink: 6a343b7f
+---
+
+# Redis入门
+
+- Redis是一个基于内存的`key-value`结构数据库
+ - 基于内存存储,读写性能高
+ - 适合存储热点数据(热点商品、咨询、新闻)
+- 官网:`https://redis.io/`
+
+
+
+# Redis的简介
+
+- Redis是用C语言开发的一个开源的、高性能的键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化NoSql数据库
+
+- NoSql(Not Only Sql),不仅仅是SQL,泛指非关系型数据库,NoSql数据库并不是要取代关系型数据库,而是关系型数据库的补充
+
+ 关系型数据库(RDBMS):MySQL、Oracl、DB2、SQLServer
+ 非关系型数据库(NoSql):Redis、Mongo DB、MemCached
+
+- Redis应用场景:缓存、消息队列、任务队列、分布式锁
+
+
+
+## 下载与安装
+
+- 这里我们在Linux和Windows上都装一下
+ - Windows 版:`https://github.com/microsoftarchive/redis/releases`
+ - Linux 版:`https://download.redis.io/releases/`
+
+### Windows安装Redis
+
+- 直接下载对应版本的`.zip`压缩包,直接解压
+
+
+
+### Linux安装Redis
+
+- Linux系统安装Redis步骤:
+
+ 1. 将Redis安装包上传到Linux
+
+ 2. 解压安装包,改成自己的redis版本
+
+ ```bash
+ tar -zxvf redis-4.0.0.tar.gz -C /usr/local/
+ ```
+
+ 3. 安装Redis的依赖环境gcc
+
+ ```bash
+ # 安装依赖环境
+ yum install gcc-c++
+ ```
+
+ 4. 进入`/usr/local/redis根目录`,进行编译
+
+ ```bash
+ # 进入到根目录
+ cd /usr/local/redis根目录
+
+ # 编译
+ make
+ ```
+
+ 5. 进入redis的src目录,进行安装
+
+ ```bash
+ # 进入到src目录
+ cd /usr/local/redis根目录/src
+ # 进行安装
+ make install
+ ```
+
+
+
+## 服务启动与停止
+
+### Linux启动与停止
+
+- 进入到`/src`目录下,执行`redis-server`即可启动服务,默认端口号为`6379`
+
+```bash
+# 进入到根目录
+cd /usr/local/redis/src
+
+# 执行redis-server
+./redis-server
+```
+
+
+
+### Linux设置后台运行
+
+进入到redis根目录下,修改配置redis.conf文件
+
+```bash
+# 进入到redis根目录下
+cd /usr/local/redis
+
+# 修改配置文件
+vim redis.conf
+```
+
+找到`daemonize no`字段,将其修改为`daemonize yes`
+
+在redis根目录以redis.conf作为配置文件在后台运行
+
+```bash
+src/redis-server ./redis.conf
+```
+
+
+
+### Linux开启密码校验
+
+- 还是修改redis.conf配置文件,找到`requirepass`这行,将其注释去掉,并在后面写上自己的密码
+- 然后杀掉原进程再重新启动
+
+
+
+```bash
+# 重新启动
+src/redis-server ./redis.conf
+
+# 登录时同时进行认证(连接的是cli客户端服务,-h是本地服务,-p设置的是端口号,-a是auth也相当于密码)
+src/redis-cli -h localhost -p 6379 -a 密码
+```
+
+修改完毕之后还是杀进程,然后重启服务
+
+
+
+
+
+### Linux开启远程连接
+
+- 还是修改redis.conf配置文件,找到`bind 127.0.0.1`这行,把这行注释掉,这一行是让我们本地进行连接的,注释之后就是开启了远程连接
+- 之后设置防火墙,开启6379端口
+- 杀死进程,并重新启动服务
+
+```bash
+# 开启6379端口
+firewall-cmd --zone=public --add-port=6379/tcp --permanent
+
+# 设置立即生效
+firewall-cmd --reload
+
+# 查看开放的端口
+firewall-cmd --zone=public --list-ports
+```
+
+最后在Windows的redis根目录下,按住Shift+右键打开PowerShell窗口,连接Linux的Redis
+
+```bash
+.\redis-cli.exe -h 虚拟机的ip地址 -p 6379 -a 密码
+```
+
+
+
+# Redis数据类型
+
+## 介绍
+
+Redis存储的是key-value结构的数据,其中key是字符串类型,value有五种常用的数据类型
+
+- 字符串 string(普通字符串,常用)
+- 哈希 hash(hash适合存储对象)
+- 列表 list(list按照插入顺序排序,可以有重复元素)
+- 集合 set(无序集合,没有重复元素)
+- 有序集合 sorted set(有序集合,没有重复元素)
+
+
+
+## Redis常用命令
+
+### 字符串string操作命令
+
+| 命令 | 描述 |
+| :---------------------: | :---------------------------------------------: |
+| SET key value | 设置指定key的值 |
+| GET key | 获取指定key的值 |
+| SETEX key seconds value | 设置指定key的值,并将key的过期时间设为seconds秒 |
+| SETNX key value | 只有在key不存在时设置key的值 |
+
+#### 操作命令示例:
+
+```bash
+127.0.0.1:6379> set name 666
+OK
+127.0.0.1:6379> get name
+"666"
+127.0.0.1:6379> setex name2 3 888
+OK
+127.0.0.1:6379> get name2
+(nil)
+127.0.0.1:6379> setnx name2 888
+(integer) 1
+127.0.0.1:6379> setnx name2 555
+(integer) 0
+127.0.0.1:6379> keys *
+1) "name2"
+2) "name"
+127.0.0.1:6379> get name2
+"888"
+```
+
+### 哈希hash操作命令
+
+`Redis Hash`是一个`String`类型的`Field`和`Value`的映射表,`Hash`特别适合用于存储对象
+
+| 命令 | 描述 |
+| :------------------: | :------------------------------------: |
+| HSET key field value | 将哈希表key 中的字段field的值设为value |
+| HGET key field | 获取存储在哈希表中指定字段的值 |
+| HDEL key field | 删除存储在哈希表中的指定字段 |
+| HKEYS key | 获取哈希表中所有字段 |
+| HVALS key | 获取哈希表中所有值 |
+| HGETALL key | 获取在哈希表中指定key的所有字段和值 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> hset table1 name wangwu // 设置table1表中的name字段值为wangwu
+(integer) 1
+127.0.0.1:6379> hget table1 name // 获取存储在table1表中的name字段
+"wangwu"
+127.0.0.1:6379> hdel table1 name // 删除存储在table1表中的name字段
+(integer) 1
+127.0.0.1:6379> hget table1 name // 此时已经被删除了,得到的是nil
+(nil)
+127.0.0.1:6379> hset table1 name lisi // 设置table1表中的name字段值为lisi
+(integer) 1
+127.0.0.1:6379> hset table1 age 10 // 设置table1表中的age字段值为10
+(integer) 1
+127.0.0.1:6379> hkeys table1 // 获取哈希表中所有字段
+1) "name"
+2) "age"
+127.0.0.1:6379> hvals table1 // 获取哈希表中所有值
+1) "wangwu"
+2) "10"
+127.0.0.1:6379> hgetall table1 // 获取在哈希表中指定key的所有字段和值
+1) "name"
+2) "wangwu"
+3) "age"
+4) "10"
+```
+
+
+
+### 列表list操作命令
+
+`Redis List`是简单的字符串列表,按照插入顺序排序
+
+| 命令 | 描述 |
+| :-------------------------: | :----------------------------------------------------------: |
+| `LPUSH` key value1 [value2] | 将一个或多个值插入到列表头部 |
+| `LRANGE` key start stop | 获取列表指定范围内的元素 |
+| `RPOP` key | 移除并获取列表最后一个元素 |
+| `LLEN` key | 获取列表长度 |
+| `BRPOP` key1 [key2] timeout | 移出并获取列表的最后一个元素 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> lpush list a b c // 将a、b、c插入到列表头部
+(integer) 3
+127.0.0.1:6379> lrange list 0 -1 // 查询从0到-1位置的元素,-1表示最后一个值
+1) "c" // c在最前面是因为列表是按照插入顺序排序的,最后插入的在最前面
+2) "b"
+3) "a"
+127.0.0.1:6379> rpop list // 删除最后一个元素,并得到值,a是最先插入的,所以是最后一个
+"a"
+127.0.0.1:6379> llen list // 获取长度
+(integer) 2
+127.0.0.1:6379> brpop list 3 // 移除列表的最后一个元素,如果列表没有值,会阻塞timeout秒,否则删除
+1) "list"
+2) "b"
+127.0.0.1:6379> brpop list 3
+1) "list"
+2) "c"
+127.0.0.1:6379> brpop list 3 // 阻塞3秒
+(nil)
+(3.09s)
+```
+
+### 集合set操作命令
+
+`Redis set`是`String`类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据
+概念和数学中的集合概念基本一致
+
+| 命令 | 描述 |
+| :------------------------: | :----------------------: |
+| SADD key member1 [member2] | 向集合添加一个或多个成员 |
+| SMEMBERS key | 返回集合中的所有成员 |
+| SCARD key | 获取集合的成员数 |
+| SINTER key1 [key2] | 返回给定所有集合的交集 |
+| SUNION key1 [key2] | 返回所有给定集合的并集 |
+| SDIFF key1 [key2] | 返回给定所有集合的差集 |
+| SREM key member1 [member2] | 移除集合中一个或多个成员 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> sadd set a a b b c d // 向set集合添加a、a、b、b、c、d
+(integer) 4
+127.0.0.1:6379> smembers set // 由于集合的唯一性,所以,只有a、b、c、d
+1) "d"
+2) "c"
+3) "b"
+4) "a"
+127.0.0.1:6379> scard set // 获取长度
+(integer) 4
+127.0.0.1:6379> srem set a b c // 删除集合中指定的对象
+(integer) 3
+127.0.0.1:6379> smembers set
+1) "d"
+```
+
+### 有序集合sorted set常用命令
+
+`Redis Sorted Set`有序集合是`String`类型元素的集合,且不允许重复的成员。每个元素都会关联一个`double`类型的分数(`score`) 。`Redis`正是通过分数来为集合中的成员进行从小到大排序。有序集合的成员是唯一的,但分数却可以重复。
+
+| 命令 | 描述 |
+| :--------------------------------------: | :----------------------------------------------------: |
+| ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
+| ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合中指定区间内的成员 |
+| ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量increment |
+| ZREM key member [member …] | 移除有序集合中的一个或多个成员 |
+
+#### 操作命令示例
+
+```bash
+127.0.0.1:6379> zadd sortset 3 a 1 c 2 b // 向集合sortset添加值与分数
+(integer) 3
+127.0.0.1:6379> zrange sortset 0 -1 // 查询,按照分数从小到大排序,最小的在最前面
+1) "c"
+2) "b"
+3) "a"
+127.0.0.1:6379> zincrby sortset 3 c // 为字段c加3分
+"4"
+127.0.0.1:6379> zrange sortset 0 -1 // 查询,此时c>a>b在最下面
+1) "b"
+2) "a"
+3) "c"
+127.0.0.1:6379> zrem sortset a b c // 删除有序集合元素
+(integer) 3
+127.0.0.1:6379> zrange sortset 0 -1
+(empty list or set)
+127.0.0.1:6379>
+```
+
+### 通用命令
+
+针对key来操作
+
+| 命令 | 描述 |
+| :----------: | :------------------------------------------------------: |
+| KEYs pattern | 查找所有符合给定模式(pattern)的key |
+| EXISTs key | 检查给定key是否存在 |
+| TYPE key | 返回key所储存的值的类型 |
+| TTL key | 返回给定key的剩余生存时间(TTL, time to live),以秒为单位 |
+| DEL key | 该命令用于在key存在是删除key |
+
+```bash
+127.0.0.1:6379> keys * // 查看所有的key
+1) "name"
+2) "table2"
+3) "table1"
+4) "NewName"
+5) "set"
+127.0.0.1:6379> exists name // 查看某个key是否存在,存在返回1,不存在返回0
+(integer) 1
+127.0.0.1:6379> exists abc
+(integer) 0
+127.0.0.1:6379> type name // 查看key的类型
+string
+127.0.0.1:6379> type set
+set
+127.0.0.1:6379> type table1
+hash
+127.0.0.1:6379> ttl name // 查看key的剩余存活时间,-1表示永久存活
+(integer) -1
+127.0.0.1:6379> setex test 10 test // 设置test字段存活时间10s,值为test
+OK
+127.0.0.1:6379> ttl test // 查看test
+(integer) 8
+127.0.0.1:6379> ttl test
+(integer) 2
+127.0.0.1:6379> keys * // 查看所有key
+1) "name"
+2) "table2"
+3) "table1"
+4) "NewName"
+5) "set"
+127.0.0.1:6379> del name // 删除name字段
+(integer) 1
+127.0.0.1:6379> keys * // 查看所有key,此时name字段就不存在了
+1) "table2"
+2) "table1"
+3) "NewName"
+4) "set"
+```
+
+
+
+# 在Java中使用Redis
+
+## 简介
+
+- Redis的Java客户端有很多,官方推荐的有三种
+ - `Jedis`
+ - `Lettuce`
+ - `Redisson`
+- Spring对Redis客户端进行了整合,提供了SpringDataRedis,在Spring Boot项目中还提供了对应的Starter,即`spring-boot-starter-data-redis`
+
+
+
+## Jedis
+
+- 使用Jedis的步骤
+ 1. 获取连接
+ 2. 执行操作
+ 3. 关闭连接
+- 在此之前我们需要导入一下Jedis的maven坐标
+
+```xml
+ +
+打开后的页面如上图所示,我们单击`连接到Redis服务器`
+
+
+
+打开后的页面如上图所示,我们单击`连接到Redis服务器`
+
+ +
+
+
+ +
+连接成功后一路确定即可
+
+
+
+连接成功后一路确定即可
+
+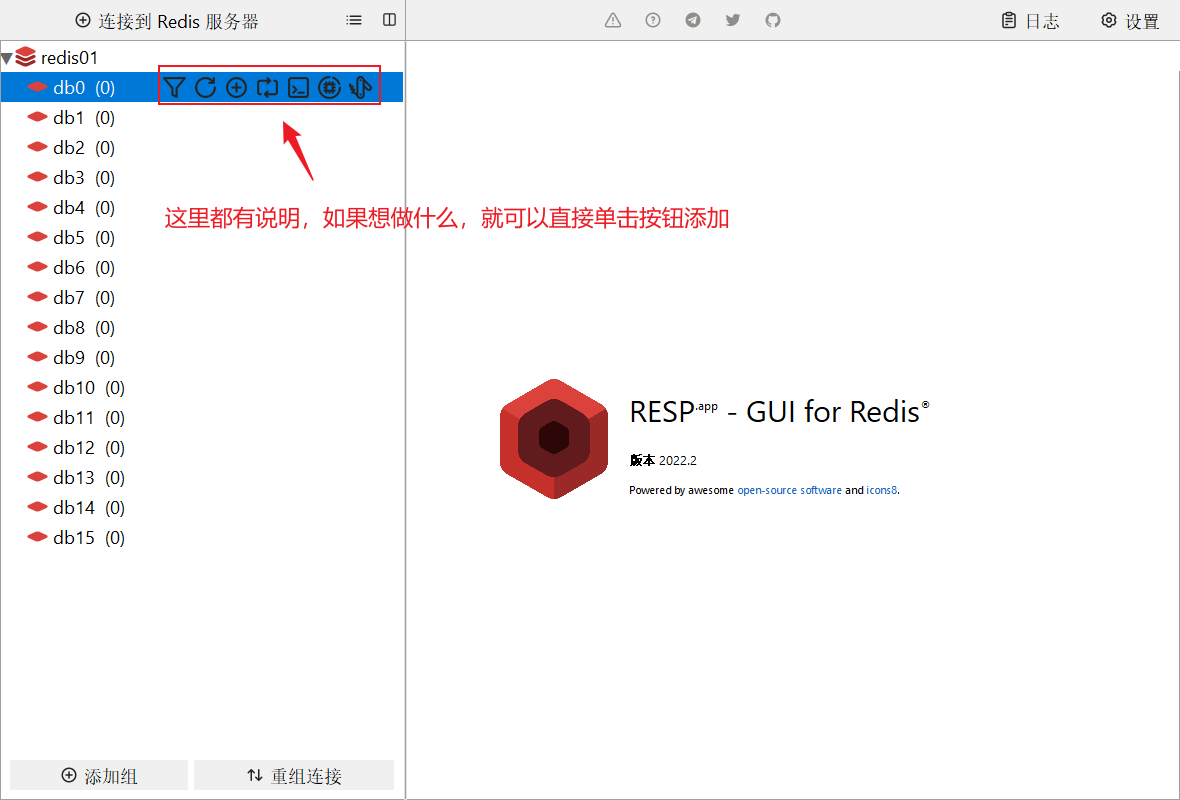 +
+添加键后的效果如下
+
+
+
+添加键后的效果如下
+
+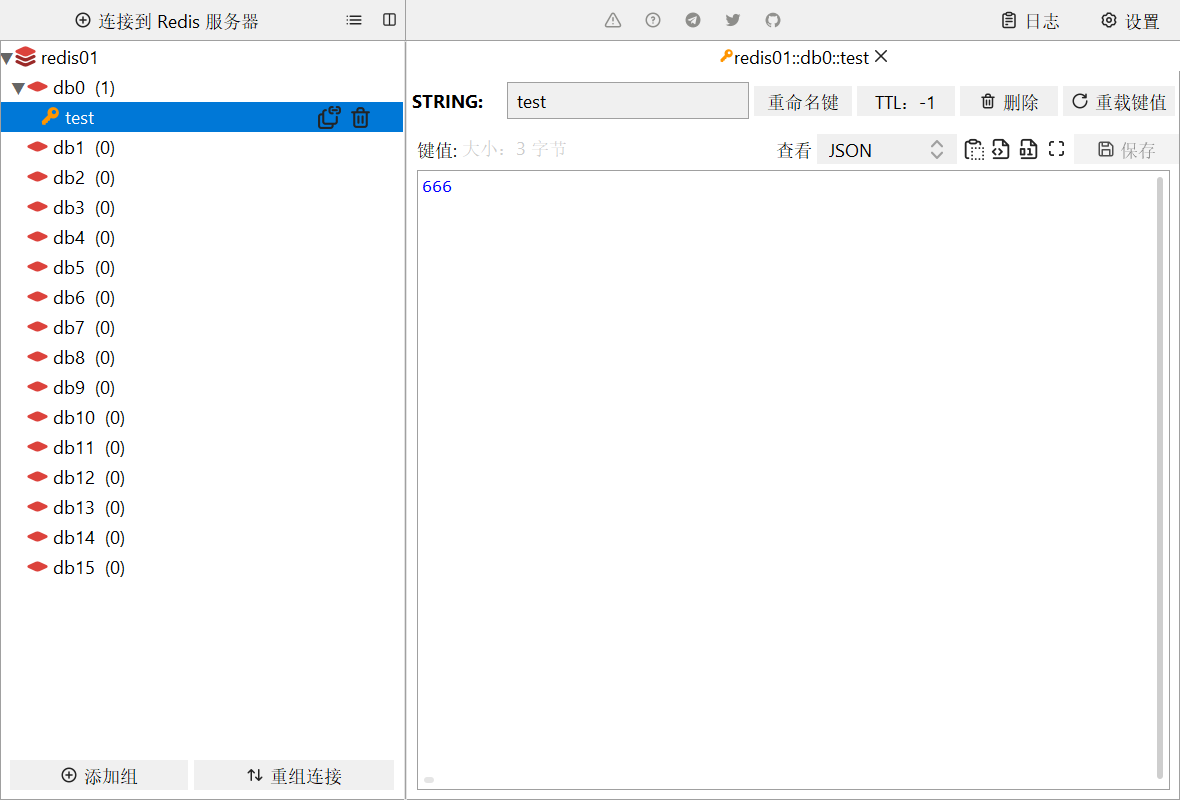 +
+
+
+# Redis常见命令
+
+## Redis数据结构介绍
+
+Redis是一个key-value的数据库,key一般是String类型,value的类型多样
+
+
+
+
+
+# Redis常见命令
+
+## Redis数据结构介绍
+
+Redis是一个key-value的数据库,key一般是String类型,value的类型多样
+
+ +
+学习Redis可以多看看Redis的官方文档:https://redis.io/commands/
+
+甚至你可以在Redis的命令行中使用help来查看帮助
+
+```bash
+help
+```
+
+
+
+## Redis的通用命令
+
+### KEYS
+
+一般是用来查找满足条件的key
+
+```bash
+KEYS pattern
+```
+
+示例:
+
+```bash
+KEYS *
+```
+
+**查询所有的key**
+
+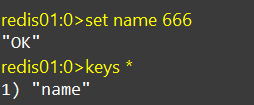
+
+一般都是根据pattern通配符来查找专门的key
+
+**不建议在生产环境使用,因为Redis是单线程的,模糊查询很慢,如果数据量较大,一查可能会出现问题**
+
+
+
+### DEL
+
+删除一个指定的key
+
+废话不多说,直接上示例
+
+**删除单个key**
+
+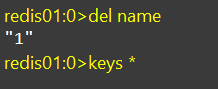
+
+**删除多个key,中间用空格隔开**
+
+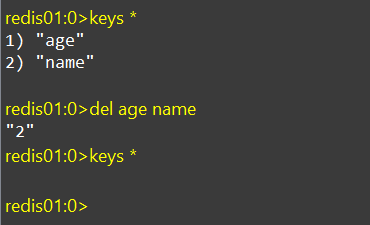
+
+
+
+### EXISTS
+
+判断key是否存在
+
+EXISTS后面可以传递多个key,返回的是key存在的数量
+
+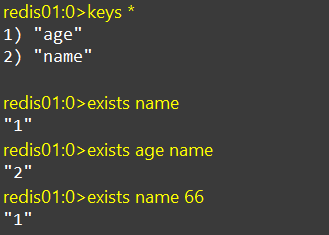
+
+
+
+### EXPIRE
+
+为key设置有效期,到期后key会被自动删除,设置的有效期一般为秒
+
+
+
+学习Redis可以多看看Redis的官方文档:https://redis.io/commands/
+
+甚至你可以在Redis的命令行中使用help来查看帮助
+
+```bash
+help
+```
+
+
+
+## Redis的通用命令
+
+### KEYS
+
+一般是用来查找满足条件的key
+
+```bash
+KEYS pattern
+```
+
+示例:
+
+```bash
+KEYS *
+```
+
+**查询所有的key**
+
+
+
+一般都是根据pattern通配符来查找专门的key
+
+**不建议在生产环境使用,因为Redis是单线程的,模糊查询很慢,如果数据量较大,一查可能会出现问题**
+
+
+
+### DEL
+
+删除一个指定的key
+
+废话不多说,直接上示例
+
+**删除单个key**
+
+
+
+**删除多个key,中间用空格隔开**
+
+
+
+
+
+### EXISTS
+
+判断key是否存在
+
+EXISTS后面可以传递多个key,返回的是key存在的数量
+
+
+
+
+
+### EXPIRE
+
+为key设置有效期,到期后key会被自动删除,设置的有效期一般为秒
+
+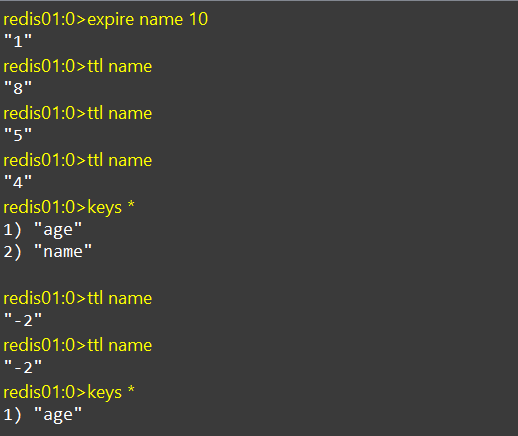 +
+### TTL
+
+查看key的有效时间,一般和EXPIRE联用
+
+```bash
+TTL key
+```
+
+使用TTL查看一个key的默认有效时间
+
+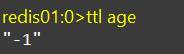
+
+-1代表永久有效
+
+
+
+## String类型
+
+String类型,也就是字符串类型,是Redis中最简单的存储类型
+
+其value是字符串,不过根据字符串的格式不同,又可以分为3类:
+
+- string:普通字符串
+- int:整数类型
+- float:浮点类型,可以做自增、自减操作
+
+不管哪种格式,底层都是字节数组形式存储,只不过编码方式不同。字符串类型的最大空间不能超过512m
+
+| Key | Value |
+| :---: | :---------: |
+| msg | hello world |
+| num | 10 |
+| score | 66.6 |
+
+### String类型的常见命令
+
+#### SET、GET
+
+set:添加或者修改已经存在的一个String类型的键值对
+
+get:根据key获取String类型的键值对
+
+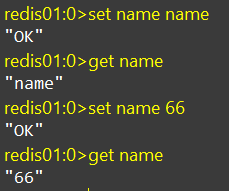
+
+
+
+#### MSET、MGET
+
+mset:批量添加多个String类型的键值对
+
+mget:根据多个key获取多个String类型的value
+
+
+
+
+
+#### INCR、INCRBY、INCRBYFLOAT
+
+incr:让一个整型的key自增1
+
+incrby:让一个整型的key自增,并指定步长,例如:incrby num 2,让num值自增2
+
+incrbyfloat:让一个浮点类型的数字自增并指定步长
+
+
+
+### TTL
+
+查看key的有效时间,一般和EXPIRE联用
+
+```bash
+TTL key
+```
+
+使用TTL查看一个key的默认有效时间
+
+
+
+-1代表永久有效
+
+
+
+## String类型
+
+String类型,也就是字符串类型,是Redis中最简单的存储类型
+
+其value是字符串,不过根据字符串的格式不同,又可以分为3类:
+
+- string:普通字符串
+- int:整数类型
+- float:浮点类型,可以做自增、自减操作
+
+不管哪种格式,底层都是字节数组形式存储,只不过编码方式不同。字符串类型的最大空间不能超过512m
+
+| Key | Value |
+| :---: | :---------: |
+| msg | hello world |
+| num | 10 |
+| score | 66.6 |
+
+### String类型的常见命令
+
+#### SET、GET
+
+set:添加或者修改已经存在的一个String类型的键值对
+
+get:根据key获取String类型的键值对
+
+
+
+
+
+#### MSET、MGET
+
+mset:批量添加多个String类型的键值对
+
+mget:根据多个key获取多个String类型的value
+
+
+
+
+
+#### INCR、INCRBY、INCRBYFLOAT
+
+incr:让一个整型的key自增1
+
+incrby:让一个整型的key自增,并指定步长,例如:incrby num 2,让num值自增2
+
+incrbyfloat:让一个浮点类型的数字自增并指定步长
+
+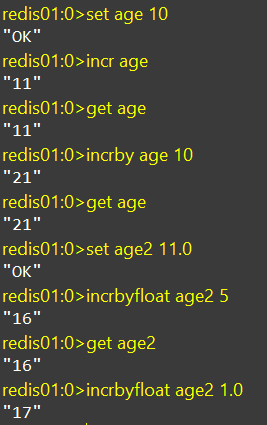 +
+#### SETNX、SETEX
+
+setnx:添加一个String类型的键值对,前提是这个key不存在,否则不执行
+
+setex:添加一个String类型的键值对,并且指定有效期
+
+
+
+#### SETNX、SETEX
+
+setnx:添加一个String类型的键值对,前提是这个key不存在,否则不执行
+
+setex:添加一个String类型的键值对,并且指定有效期
+
+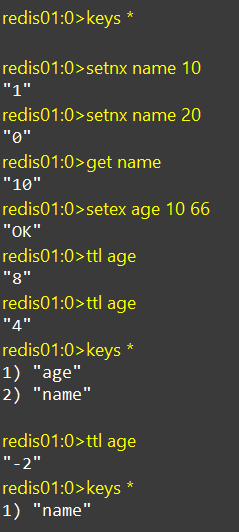 +
+
+
+## Key的层级格式
+
+Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
+
+Redis的key允许有多个单词形成层级结构,多个单词之间用`:`隔开,格式如下:
+
+```txt
+项目名:业务名:类型:id
+```
+
+这个格式并非固定,也可以根据自己的需求来删除和添加词条
+
+例如我们的项目叫eastwind,有user和product两种不同类型的数据,我们可以这样定义key
+
+- user相关的key:eastwind:user:1
+- product相关的key:eastwind:product:1
+
+
+
+如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
+
+| KEY | VALUE |
+| -------------------- | ------------------------------------------- |
+| eastwind:user:1 | {"id":1,"name":"Jack","age":21} |
+| eastwind:product:1 | {"id":1,"name":"小米x66","price":4999} |
+
+测试一下层级
+
+
+
+添加以下代码后,来到redis的桌面端查看
+
+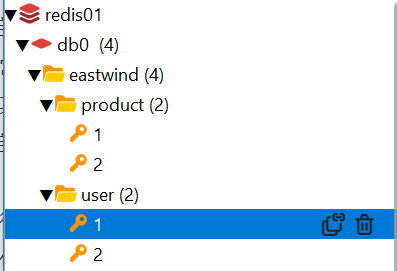
+
+此时这里就有了层级关系
+
+
+
+## Hash类型
+
+Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构
+
+String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便
+
+
+
+
+
+## Key的层级格式
+
+Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
+
+Redis的key允许有多个单词形成层级结构,多个单词之间用`:`隔开,格式如下:
+
+```txt
+项目名:业务名:类型:id
+```
+
+这个格式并非固定,也可以根据自己的需求来删除和添加词条
+
+例如我们的项目叫eastwind,有user和product两种不同类型的数据,我们可以这样定义key
+
+- user相关的key:eastwind:user:1
+- product相关的key:eastwind:product:1
+
+
+
+如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
+
+| KEY | VALUE |
+| -------------------- | ------------------------------------------- |
+| eastwind:user:1 | {"id":1,"name":"Jack","age":21} |
+| eastwind:product:1 | {"id":1,"name":"小米x66","price":4999} |
+
+测试一下层级
+
+
+
+添加以下代码后,来到redis的桌面端查看
+
+
+
+此时这里就有了层级关系
+
+
+
+## Hash类型
+
+Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构
+
+String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便
+
+ +
+Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
+
+
+
+Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
+
+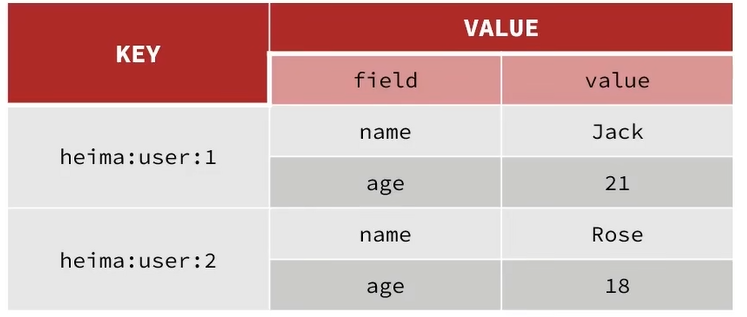 +
+### Hash类型的常见命令
+
+#### HSET、HGET
+
+hset:添加或修改hash类型key的field的值
+
+```
+hset hash名 字段名 值
+```
+
+hget:获取一个hash类型key的field的值
+
+```
+hget hash名 字段名
+```
+
+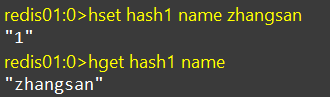
+
+
+
+#### HMSET、HMGET
+
+hmset:添加多个键值对
+
+hmget:获取多个键值对
+
+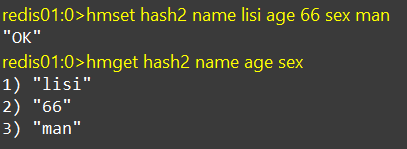
+
+
+
+#### HGETALL、HKEYS、HVALS
+
+hgetall:获取一个hash类型中的所有字段和值
+
+hkeys:获取一个hash类型中所有的字段
+
+hvals:获取一个hash类型中所有的值
+
+
+
+### Hash类型的常见命令
+
+#### HSET、HGET
+
+hset:添加或修改hash类型key的field的值
+
+```
+hset hash名 字段名 值
+```
+
+hget:获取一个hash类型key的field的值
+
+```
+hget hash名 字段名
+```
+
+
+
+
+
+#### HMSET、HMGET
+
+hmset:添加多个键值对
+
+hmget:获取多个键值对
+
+
+
+
+
+#### HGETALL、HKEYS、HVALS
+
+hgetall:获取一个hash类型中的所有字段和值
+
+hkeys:获取一个hash类型中所有的字段
+
+hvals:获取一个hash类型中所有的值
+
+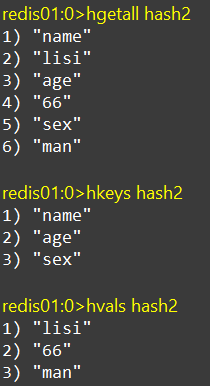 +
+#### HINCRBY
+
+hincrby:让一个hash类型的字段值自增并指定步长
+
+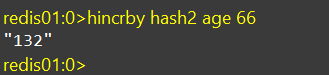
+
+#### HSETNX
+
+hsetnx:添加一个hash类型的字段值,前提是该字段不存在,否则不执行
+
+
+
+
+
+## List类型
+
+Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
+
+特征也与LinkedList类似:
+
+- 有序
+- 元素可以重复
+- 插入和删除快
+- 查询速度一般
+
+常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
+
+
+
+关于左侧和右侧插入的情况,举出一个例子
+
+```
+我们想插入值C,如果在左侧插入,那么就在A的前面,如果在右侧插入,就在B的后面
+A-B
+C-A-B
+A-B-C
+```
+
+
+
+### List类型的常见命令
+
+#### LPUSH
+
+向列表左侧插入一个或多个元素
+
+
+
+根据上面的例子,我们会依次插入name、123、jsda,都是左侧插入,所以插入顺序如下
+
+```
+jsda-123-name
+```
+
+
+
+#### LPOP
+
+lpop:移除并返回列表左侧的第一个元素,没有则返回nil
+
+
+
+#### RPUSH
+
+向列表右侧插入一个或多个元素
+
+
+
+右侧插入也是同理,我们这次只插入了一个age
+
+```
+123-name-age
+```
+
+
+
+#### LRANGE
+
+xxxxxxxxxx @Testvoid commonTest() { //查看所有key(keys *) Set
+
+#### HINCRBY
+
+hincrby:让一个hash类型的字段值自增并指定步长
+
+
+
+#### HSETNX
+
+hsetnx:添加一个hash类型的字段值,前提是该字段不存在,否则不执行
+
+
+
+
+
+## List类型
+
+Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
+
+特征也与LinkedList类似:
+
+- 有序
+- 元素可以重复
+- 插入和删除快
+- 查询速度一般
+
+常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
+
+
+
+关于左侧和右侧插入的情况,举出一个例子
+
+```
+我们想插入值C,如果在左侧插入,那么就在A的前面,如果在右侧插入,就在B的后面
+A-B
+C-A-B
+A-B-C
+```
+
+
+
+### List类型的常见命令
+
+#### LPUSH
+
+向列表左侧插入一个或多个元素
+
+
+
+根据上面的例子,我们会依次插入name、123、jsda,都是左侧插入,所以插入顺序如下
+
+```
+jsda-123-name
+```
+
+
+
+#### LPOP
+
+lpop:移除并返回列表左侧的第一个元素,没有则返回nil
+
+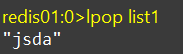
+
+#### RPUSH
+
+向列表右侧插入一个或多个元素
+
+
+
+右侧插入也是同理,我们这次只插入了一个age
+
+```
+123-name-age
+```
+
+
+
+#### LRANGE
+
+xxxxxxxxxx @Testvoid commonTest() { //查看所有key(keys *) Set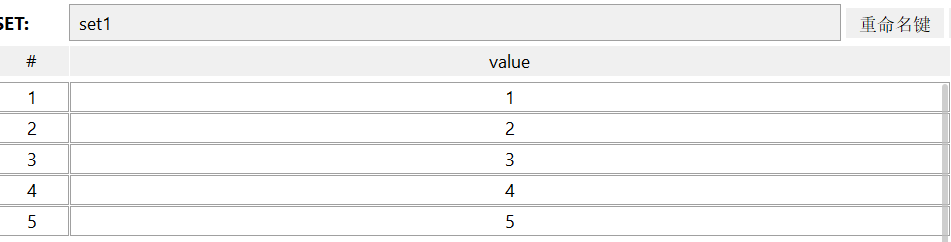 +
+srem:移除set中的指定元素
+
+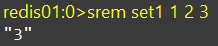
+
+
+
+scard:返回set中元素的个数
+
+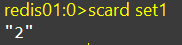
+
+#### SISMEMBER、SMEMBERS
+
+sismember:判断一个元素是否存在于set中
+
+smembers:获取set中的所有元素
+
+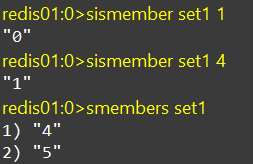
+
+#### SINTER、SUNION、SDIFF
+
+sinter:求两个集合的交集
+
+sunion:求两个集合的并集
+
+sdiff:求两个集合的差集(补集)
+
+## SortedSet
+
+Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
+
+SortedSet具备下列特性:
+
+- 可排序
+- 元素不重复
+- 查询速度快
+
+因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
+
+### SortedSet的常见命令
+
+#### ZADD、ZREM
+
+zadd:添加一个或多个元素到sorted set,如果已经存在则更新其score值
+
+zrem:删除sorted set中的一个指定元素
+
+
+
+
+
+srem:移除set中的指定元素
+
+
+
+
+
+scard:返回set中元素的个数
+
+
+
+#### SISMEMBER、SMEMBERS
+
+sismember:判断一个元素是否存在于set中
+
+smembers:获取set中的所有元素
+
+
+
+#### SINTER、SUNION、SDIFF
+
+sinter:求两个集合的交集
+
+sunion:求两个集合的并集
+
+sdiff:求两个集合的差集(补集)
+
+## SortedSet
+
+Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
+
+SortedSet具备下列特性:
+
+- 可排序
+- 元素不重复
+- 查询速度快
+
+因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
+
+### SortedSet的常见命令
+
+#### ZADD、ZREM
+
+zadd:添加一个或多个元素到sorted set,如果已经存在则更新其score值
+
+zrem:删除sorted set中的一个指定元素
+
+
+
+ +
+
+
+
+
+
+
+ +
+#### ZSCORE、ZRANK
+
+zscore:获取sorted set中指定元素的score值
+
+zrank:获取sorted set中的指定元素的排名,一般分数越高,排名越靠后
+
+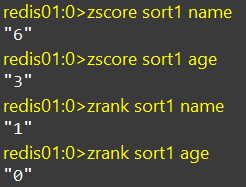
+
+#### ZCARD、ZCOUNT
+
+zcard:统计元素个数
+
+zcount:统计score值在给定范围内的所有元素的个数
+
+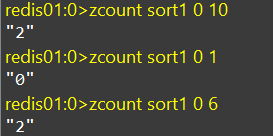
+
+#### ZINCRBY
+
+让sorted set中的指定元素自增,步长为指定的值,添加的是score
+
+
+
+#### ZRANGE
+
+按照score排序后,获取指定范围内的元素,这里的范围代指索引,也可以称为排名
+
+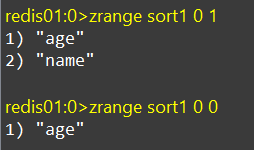
+
+#### ZRANGEBYSCORE
+
+按照score排序后,获取score范围内的元素,根据score来获取值
+
+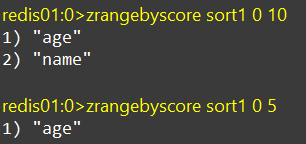
+
+#### ZDIFF、ZINTER、ZUNION
+
+求差集、交集、并集,跟set一致
+
+
+
+注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
+
+- `升序`获取sorted set 中的指定元素的排名:ZRANK key member
+- `降序`获取sorted set 中的指定元素的排名:ZREVRANK key memeber
+
+
+
+# Redis的Java客户端
+
+## Jedis
+
+### 快速入门
+
+新建一个maven工程
+
+引入依赖
+
+```xml
+
+
+
+#### ZSCORE、ZRANK
+
+zscore:获取sorted set中指定元素的score值
+
+zrank:获取sorted set中的指定元素的排名,一般分数越高,排名越靠后
+
+
+
+#### ZCARD、ZCOUNT
+
+zcard:统计元素个数
+
+zcount:统计score值在给定范围内的所有元素的个数
+
+
+
+#### ZINCRBY
+
+让sorted set中的指定元素自增,步长为指定的值,添加的是score
+
+
+
+#### ZRANGE
+
+按照score排序后,获取指定范围内的元素,这里的范围代指索引,也可以称为排名
+
+
+
+#### ZRANGEBYSCORE
+
+按照score排序后,获取score范围内的元素,根据score来获取值
+
+
+
+#### ZDIFF、ZINTER、ZUNION
+
+求差集、交集、并集,跟set一致
+
+
+
+注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
+
+- `升序`获取sorted set 中的指定元素的排名:ZRANK key member
+- `降序`获取sorted set 中的指定元素的排名:ZREVRANK key memeber
+
+
+
+# Redis的Java客户端
+
+## Jedis
+
+### 快速入门
+
+新建一个maven工程
+
+引入依赖
+
+```xml
+
+ +
+## 基于Session实现登录
+
+### 工作流程
+
+
+
+### 发送短信验证码
+
+进入短信验证码的页面,点击按钮查看对应的请求地址
+
+请求方式为`POST`,请求路径为`/user/code`,请求参数为phone(电话号码)
+
+
+
+来到UserController下进行代码的编写
+
+```java
+/**
+ * 发送手机验证码
+ */
+@PostMapping("code")
+public Result sendCode(@RequestParam("phone") String phone, HttpSession session) {
+ // 发送短信验证码并保存验证码
+ userService.sendCode(phone,session);
+ return Result.fail("功能未完成");
+}
+```
+
+IUserService
+
+```java
+Result sendCode(String phone, HttpSession session);
+```
+
+UserServiceImpl
+
+```java
+import cn.hutool.core.util.RandomUtil;
+import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
+import com.hmdp.dto.Result;
+import com.hmdp.entity.User;
+import com.hmdp.mapper.UserMapper;
+import com.hmdp.service.IUserService;
+import com.hmdp.utils.RegexUtils;
+import lombok.extern.slf4j.Slf4j;
+import org.springframework.beans.factory.annotation.Autowired;
+import org.springframework.stereotype.Service;
+
+import javax.servlet.http.HttpSession;
+
+/**
+ *
+
+## 基于Session实现登录
+
+### 工作流程
+
+
+
+### 发送短信验证码
+
+进入短信验证码的页面,点击按钮查看对应的请求地址
+
+请求方式为`POST`,请求路径为`/user/code`,请求参数为phone(电话号码)
+
+
+
+来到UserController下进行代码的编写
+
+```java
+/**
+ * 发送手机验证码
+ */
+@PostMapping("code")
+public Result sendCode(@RequestParam("phone") String phone, HttpSession session) {
+ // 发送短信验证码并保存验证码
+ userService.sendCode(phone,session);
+ return Result.fail("功能未完成");
+}
+```
+
+IUserService
+
+```java
+Result sendCode(String phone, HttpSession session);
+```
+
+UserServiceImpl
+
+```java
+import cn.hutool.core.util.RandomUtil;
+import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
+import com.hmdp.dto.Result;
+import com.hmdp.entity.User;
+import com.hmdp.mapper.UserMapper;
+import com.hmdp.service.IUserService;
+import com.hmdp.utils.RegexUtils;
+import lombok.extern.slf4j.Slf4j;
+import org.springframework.beans.factory.annotation.Autowired;
+import org.springframework.stereotype.Service;
+
+import javax.servlet.http.HttpSession;
+
+/**
+ *  +
+没啥问题,登录后再查看一下,成功
+
+
+
+没啥问题,登录后再查看一下,成功
+
+ +
+### 隐藏用户敏感信息
+
+如果直接存储一个user对象可能会泄露很多的信息在上面,所以我们需要修改存储session属性的方法
+
+```diff
+ @Override
+ public Result login(LoginFormDTO loginForm, HttpSession session) {
+ // 1、校验手机号
+ // 获取登录账号
+ String loginFormPhone = loginForm.getPhone();
+
+ // 获取登录验证码
+ String loginFormCode = loginForm.getCode();
+
+ // 获取session中的验证码
+ String code = (String) session.getAttribute("code");
+
+
+ // 2、校验验证码
+ if (!RegexUtils.isEmailInvalid(loginFormCode)){
+ // 3、不一致,报错
+ return Result.fail("请输入正确的邮箱");
+ }
+
+
+ // 4、一致,根据手机号查询用户
+ LambdaQueryWrapper
+
+### 隐藏用户敏感信息
+
+如果直接存储一个user对象可能会泄露很多的信息在上面,所以我们需要修改存储session属性的方法
+
+```diff
+ @Override
+ public Result login(LoginFormDTO loginForm, HttpSession session) {
+ // 1、校验手机号
+ // 获取登录账号
+ String loginFormPhone = loginForm.getPhone();
+
+ // 获取登录验证码
+ String loginFormCode = loginForm.getCode();
+
+ // 获取session中的验证码
+ String code = (String) session.getAttribute("code");
+
+
+ // 2、校验验证码
+ if (!RegexUtils.isEmailInvalid(loginFormCode)){
+ // 3、不一致,报错
+ return Result.fail("请输入正确的邮箱");
+ }
+
+
+ // 4、一致,根据手机号查询用户
+ LambdaQueryWrapper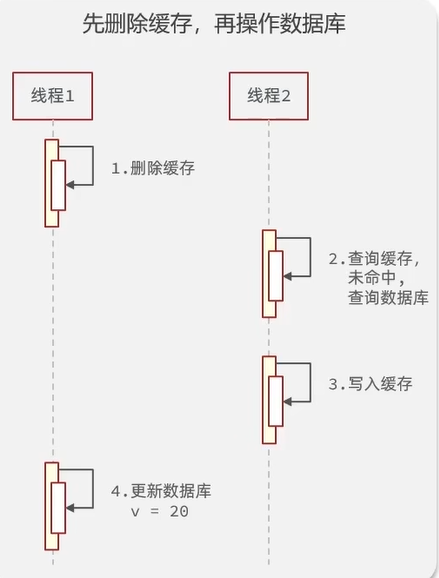 +
+ 读写查很快,而数据库更新很慢,所以极容易出现上述的异常情况
+
+- **先操作数据库,再删除缓存(常用)**
+
+ - 正常情况
+ - 先更新数据库为新数据,再删除缓存,因为缓存删除了,所以如果有人来查询缓存,此时必然是没有的,会先到数据库查询,再为缓存赋值,是最新数据
+ - 异常情况(可能性低)
+ - 假设一种特殊情况:缓存失效了,此时线程1去查数据库,会得到旧数据,得到之后,被线程2拿到了控制权,线程2要改变数据库,再删缓存,那么流程就是,线程2先更新了数据库,又删除了缓存(此时缓存是空的,删了等于没删),删完之后切回线程1,线程1将刚刚查询得到的旧数据写入缓存,此时的缓存是旧数据,而数据库是新数据,有问题
+
+ 下图为错误图示例
+
+
+
+ 读写查很快,而数据库更新很慢,所以极容易出现上述的异常情况
+
+- **先操作数据库,再删除缓存(常用)**
+
+ - 正常情况
+ - 先更新数据库为新数据,再删除缓存,因为缓存删除了,所以如果有人来查询缓存,此时必然是没有的,会先到数据库查询,再为缓存赋值,是最新数据
+ - 异常情况(可能性低)
+ - 假设一种特殊情况:缓存失效了,此时线程1去查数据库,会得到旧数据,得到之后,被线程2拿到了控制权,线程2要改变数据库,再删缓存,那么流程就是,线程2先更新了数据库,又删除了缓存(此时缓存是空的,删了等于没删),删完之后切回线程1,线程1将刚刚查询得到的旧数据写入缓存,此时的缓存是旧数据,而数据库是新数据,有问题
+
+ 下图为错误图示例
+
+ 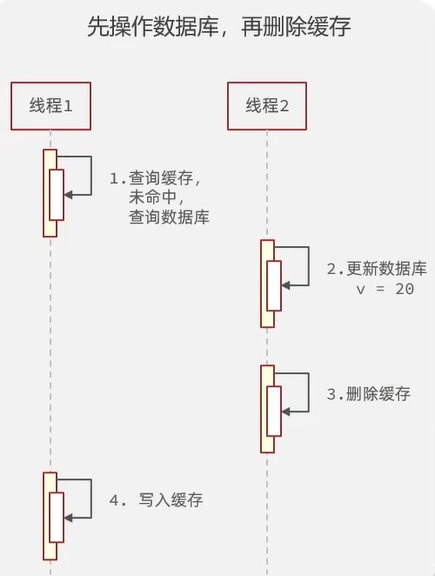 +
+缓存更新策略的最佳实践方案:
+
+1. 低一致性需求:使用Redis自带的内存淘汰机制
+2. 高一致性需求:主动更新,并以超时剔除作为兜底方案
+ - 读操作:
+ - 缓存命中直接返回
+ - 缓存未命中则查询数据库,并写入缓存,设定超时时间
+ - 写操作:
+ - 先写数据库,再删除缓存
+ - 要确保数据库与缓存操作的原子性
+
+
+
+## 给查询商铺的缓存添加超时剔除和主动更新的策略
+
+修改ShopController中的业务逻辑,满足下面的需求:
+
+- 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
+- 根据id修改店铺时,先修改数据库,再删除缓存
+
+### 超时剔除
+
+ShopServiceImpl(添加了一个超时时间)
+
+```java
+@Override
+ public Result queryById(Long id) {
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+ // 不存在,根据id查询数据库
+ Shop shop = getById(id);
+ if (shop == null){
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ //返回
+ return Result.ok(shop);
+ }
+```
+
+### 主动更新
+
+ShopController
+
+```java
+@PutMapping
+public Result updateShop(@RequestBody Shop shop) {
+ // 写入数据库
+ return shopService.update(shop);
+}
+```
+
+IShopService
+
+```java
+Result update(Shop shop);
+```
+
+ShopServiceImpl
+
+```java
+@Override
+@Transactional
+public Result update(Shop shop) {
+ Long id = shop.getId();
+ if (id == null){
+ return Result.fail("店铺id不能为空");
+ }
+ // 先更新数据库
+ updateById(shop);
+ // 再删除缓存
+ stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
+ return Result.ok();
+}
+```
+
+测试Redis中的缓存是否会存储30分钟(成功)
+
+
+
+测试修改后数据库和缓存是否都会被修改(在postman中测试)
+
+请求方式`PUT`,请求地址http://localhost:8081/shop
+
+测试数据
+
+```json
+{
+ "area": "大关",
+ "openHours": "10:00-22:00",
+ "sold": 4215,
+ "address": "金华路锦昌文华苑29号",
+ "comments": 3035,
+ "avgPrice": 80,
+ "score": 37,
+ "name": "102茶餐厅",
+ "typeId": 1,
+ "id": 1
+}
+```
+
+数据库更新成功
+
+
+
+redis中的数据也被删除了,当再次查询时才会从数据库中查询
+
+
+
+缓存更新策略的最佳实践方案:
+
+1. 低一致性需求:使用Redis自带的内存淘汰机制
+2. 高一致性需求:主动更新,并以超时剔除作为兜底方案
+ - 读操作:
+ - 缓存命中直接返回
+ - 缓存未命中则查询数据库,并写入缓存,设定超时时间
+ - 写操作:
+ - 先写数据库,再删除缓存
+ - 要确保数据库与缓存操作的原子性
+
+
+
+## 给查询商铺的缓存添加超时剔除和主动更新的策略
+
+修改ShopController中的业务逻辑,满足下面的需求:
+
+- 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
+- 根据id修改店铺时,先修改数据库,再删除缓存
+
+### 超时剔除
+
+ShopServiceImpl(添加了一个超时时间)
+
+```java
+@Override
+ public Result queryById(Long id) {
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+ // 不存在,根据id查询数据库
+ Shop shop = getById(id);
+ if (shop == null){
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ //返回
+ return Result.ok(shop);
+ }
+```
+
+### 主动更新
+
+ShopController
+
+```java
+@PutMapping
+public Result updateShop(@RequestBody Shop shop) {
+ // 写入数据库
+ return shopService.update(shop);
+}
+```
+
+IShopService
+
+```java
+Result update(Shop shop);
+```
+
+ShopServiceImpl
+
+```java
+@Override
+@Transactional
+public Result update(Shop shop) {
+ Long id = shop.getId();
+ if (id == null){
+ return Result.fail("店铺id不能为空");
+ }
+ // 先更新数据库
+ updateById(shop);
+ // 再删除缓存
+ stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
+ return Result.ok();
+}
+```
+
+测试Redis中的缓存是否会存储30分钟(成功)
+
+
+
+测试修改后数据库和缓存是否都会被修改(在postman中测试)
+
+请求方式`PUT`,请求地址http://localhost:8081/shop
+
+测试数据
+
+```json
+{
+ "area": "大关",
+ "openHours": "10:00-22:00",
+ "sold": 4215,
+ "address": "金华路锦昌文华苑29号",
+ "comments": 3035,
+ "avgPrice": 80,
+ "score": 37,
+ "name": "102茶餐厅",
+ "typeId": 1,
+ "id": 1
+}
+```
+
+数据库更新成功
+
+
+
+redis中的数据也被删除了,当再次查询时才会从数据库中查询
+
+ +
+## 缓存穿透
+
+缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
+
+就是说,如果客户端发起了一个请求,请求一家店铺,但是这家店铺是不存在的,也就是假的请求,然后此时会请求到Redis中,Redis查看后肯定是没有的,毕竟是假的,然后发给数据库,数据库肯定也没有,然后返回
+
+此时,如果有一个不坏好意的人,整了多个线程,一直反复的发,反复的请求,可能就要坏事了
+
+常见的解决方案有两种
+
+- 缓存空对象
+
+- 缓存空对象流程图
+
+
+
+## 缓存穿透
+
+缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
+
+就是说,如果客户端发起了一个请求,请求一家店铺,但是这家店铺是不存在的,也就是假的请求,然后此时会请求到Redis中,Redis查看后肯定是没有的,毕竟是假的,然后发给数据库,数据库肯定也没有,然后返回
+
+此时,如果有一个不坏好意的人,整了多个线程,一直反复的发,反复的请求,可能就要坏事了
+
+常见的解决方案有两种
+
+- 缓存空对象
+
+- 缓存空对象流程图
+
+ 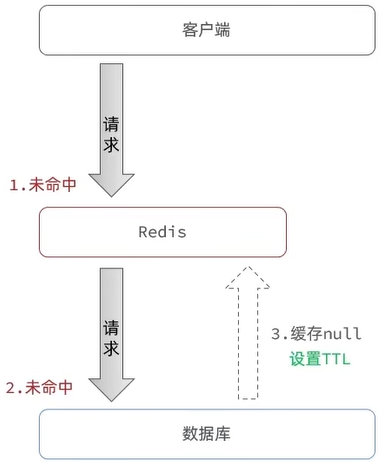 +
+ - 当你发了一个假的不存在的对象给我,我最后从数据库会得到一个null,此时我将其缓存起来,当你再次请求,我就直接从Redis里面返回给你之前那个null,简单粗暴
+ - 优点:实现简单,维护方便
+ - 缺点
+ - 额外的内存消耗(反复给你发不同的空的对象,会缓存起来一堆垃圾),可以设置一个TTL(缓存有效期),设置为5分钟或者2分钟不等,专门用来缓存垃圾数据
+ - 可能造成短期的不一致(如果我们已经在Redis缓存了发来的空对象,此时Redis会缓存起来,如果真的有一个对象就是刚刚被创建出来的,此时,用户再查询,会是null,也就是刚刚缓存的空对象)
+
+- 布隆过滤
+
+- 布隆过滤流程图
+
+
+
+ - 当你发了一个假的不存在的对象给我,我最后从数据库会得到一个null,此时我将其缓存起来,当你再次请求,我就直接从Redis里面返回给你之前那个null,简单粗暴
+ - 优点:实现简单,维护方便
+ - 缺点
+ - 额外的内存消耗(反复给你发不同的空的对象,会缓存起来一堆垃圾),可以设置一个TTL(缓存有效期),设置为5分钟或者2分钟不等,专门用来缓存垃圾数据
+ - 可能造成短期的不一致(如果我们已经在Redis缓存了发来的空对象,此时Redis会缓存起来,如果真的有一个对象就是刚刚被创建出来的,此时,用户再查询,会是null,也就是刚刚缓存的空对象)
+
+- 布隆过滤
+
+- 布隆过滤流程图
+
+ 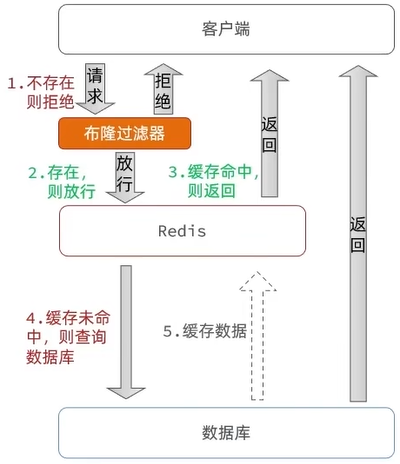 +
+ - 客户端请求布隆过滤器,若数据不存在直接拒绝,存在则放行通过去Redis中查询,如果Redis中存在,则从Redis缓存中查询,如果Redis缓存中有,则直接返回,若没有则去数据库中查询,数据库中有返回,否则返回无数据
+ - 优点:内存占用较少,没有多余key(拦截后,就会拒绝请求了,不拦截才会去内部查询,有时候过滤器可能会误判,放一些进来也没什么大问题)
+ - 缺点
+ - 实现复杂
+ - 存在误判可能
+
+
+
+### 代码实现
+
+ShopServiceImpl
+
+```java
+@Override
+ public Result queryById(Long id) {
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+
+ // 如果是空字符串
+ if (cache != null){
+ // 如果在redis中没有查询到该商铺的信息,说明该缓存为null,去数据库中查询
+ // 如果数据库也为空,说明缓存穿透了,然后将空值写入Redis,并返回错误
+ // 当再次访问时,查询得到的会是空字符串,而不是空,就会直接拿到redis中的数据,会是空,然后报错
+ // StrUtil.isNotBlank会判别空字符串是空的,所以上面的并不会返回数据
+ return Result.fail("未找到该商铺信息");
+ }
+
+ // 不存在,根据id查询数据库
+ Shop shop = getById(id);
+ if (shop == null){
+ // 将空值写入Redis并设置时间为两分钟
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ //返回
+ return Result.ok(shop);
+ }
+```
+
+测试
+
+访问http://localhost:8080/api/shop/0,这是一个不存在的地址,看控制台返回什么
+
+没有找到数据,并且页面也显示为空
+
+
+
+再次访问该地址,会发现控制台并没有输出sql语句,而是直接去了redis缓存中查询
+
+## 缓存雪崩
+
+缓存雪崩是指同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力
+
+当Redis服务宕机时,情况就会极为严重,所有的请求都会直接来到数据库中
+
+
+
+ - 客户端请求布隆过滤器,若数据不存在直接拒绝,存在则放行通过去Redis中查询,如果Redis中存在,则从Redis缓存中查询,如果Redis缓存中有,则直接返回,若没有则去数据库中查询,数据库中有返回,否则返回无数据
+ - 优点:内存占用较少,没有多余key(拦截后,就会拒绝请求了,不拦截才会去内部查询,有时候过滤器可能会误判,放一些进来也没什么大问题)
+ - 缺点
+ - 实现复杂
+ - 存在误判可能
+
+
+
+### 代码实现
+
+ShopServiceImpl
+
+```java
+@Override
+ public Result queryById(Long id) {
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+
+ // 如果是空字符串
+ if (cache != null){
+ // 如果在redis中没有查询到该商铺的信息,说明该缓存为null,去数据库中查询
+ // 如果数据库也为空,说明缓存穿透了,然后将空值写入Redis,并返回错误
+ // 当再次访问时,查询得到的会是空字符串,而不是空,就会直接拿到redis中的数据,会是空,然后报错
+ // StrUtil.isNotBlank会判别空字符串是空的,所以上面的并不会返回数据
+ return Result.fail("未找到该商铺信息");
+ }
+
+ // 不存在,根据id查询数据库
+ Shop shop = getById(id);
+ if (shop == null){
+ // 将空值写入Redis并设置时间为两分钟
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ //返回
+ return Result.ok(shop);
+ }
+```
+
+测试
+
+访问http://localhost:8080/api/shop/0,这是一个不存在的地址,看控制台返回什么
+
+没有找到数据,并且页面也显示为空
+
+
+
+再次访问该地址,会发现控制台并没有输出sql语句,而是直接去了redis缓存中查询
+
+## 缓存雪崩
+
+缓存雪崩是指同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力
+
+当Redis服务宕机时,情况就会极为严重,所有的请求都会直接来到数据库中
+
+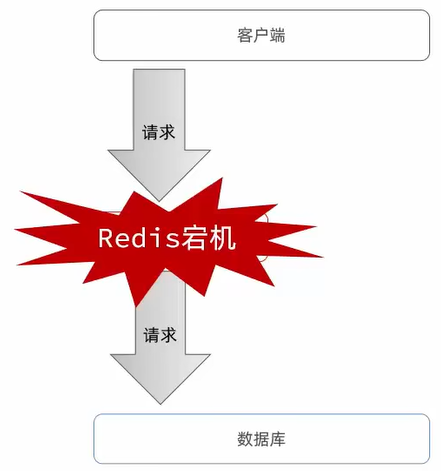 +
+解决方案:
+
+- 给不同的key的TTL(存活时间)添加随机值
+- 利用Redis集群提高服务的高可用性
+- 给缓存业务添加降级限流策略
+- 给业务添加多级缓存
+
+## 缓存击穿
+
+缓存击穿问题也叫热点Key问题,就是被高并发访问并且缓存重建业务比较复杂的key突然失效了,无数的请求访问在瞬间给数据库带来巨大的冲击
+
+可以理解为,当一个线程去访问一个高并发访问的缓存并且缓存创建业务复杂的key失效了,那么当前线程查询缓存会未命中,而它的流程也比较麻烦,此时如果有其他线程进来查询,也会去数据库查询,因为最开始的线程还没有将数据写入缓存,而它又是一个高并发的线程,所以,可能会导致数据库压力过大,宕机
+
+
+
+解决方案:
+
+- 给不同的key的TTL(存活时间)添加随机值
+- 利用Redis集群提高服务的高可用性
+- 给缓存业务添加降级限流策略
+- 给业务添加多级缓存
+
+## 缓存击穿
+
+缓存击穿问题也叫热点Key问题,就是被高并发访问并且缓存重建业务比较复杂的key突然失效了,无数的请求访问在瞬间给数据库带来巨大的冲击
+
+可以理解为,当一个线程去访问一个高并发访问的缓存并且缓存创建业务复杂的key失效了,那么当前线程查询缓存会未命中,而它的流程也比较麻烦,此时如果有其他线程进来查询,也会去数据库查询,因为最开始的线程还没有将数据写入缓存,而它又是一个高并发的线程,所以,可能会导致数据库压力过大,宕机
+
+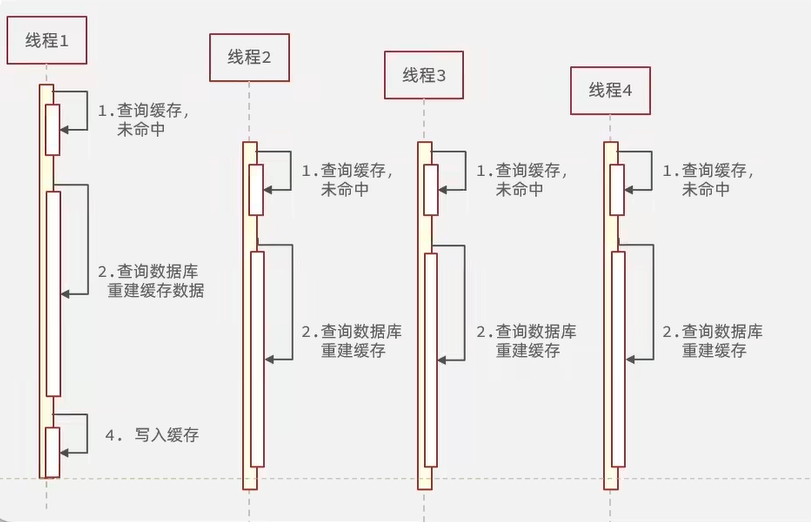 +
+常见的解决方案有两种:
+
+### 互斥锁
+
+- 假设若干个线程同时来访问缓存,其中最早的一个获取到了互斥锁,那么这个线程会去查询数据库重建缓存数据,并将查到的内容写入缓存后,释放锁,而其他线程在那个线程获取了互斥锁后,都没办法再获取互斥锁,则会休眠一会再重试,而且会不断重试,直到命中
+-
+
+常见的解决方案有两种:
+
+### 互斥锁
+
+- 假设若干个线程同时来访问缓存,其中最早的一个获取到了互斥锁,那么这个线程会去查询数据库重建缓存数据,并将查到的内容写入缓存后,释放锁,而其他线程在那个线程获取了互斥锁后,都没办法再获取互斥锁,则会休眠一会再重试,而且会不断重试,直到命中
+- 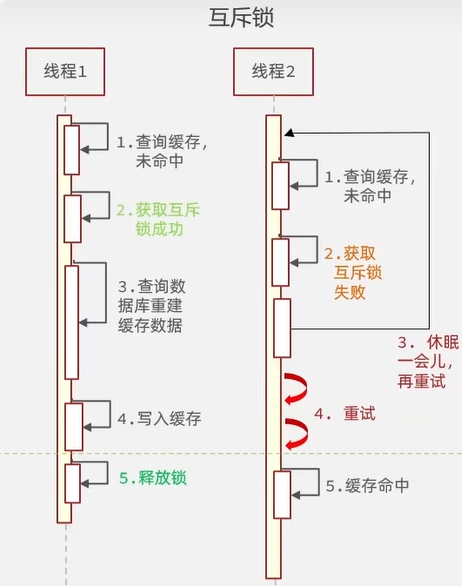 +- 缺点:当数千线程同时进入,只有一个线程可以得到互斥锁并重建缓存数据,其他线程只能无限期的等待,所以性能较差
+
+### 逻辑过期
+
+- 要设置逻辑过期,需要在缓存的时候添加**逻辑时间**,如果有线程查询缓存,当逻辑时间过期时,就会去获取互斥锁,然后开启一个新线程,由新线程来查询数据库,重建缓存数据并写入缓存,重置逻辑时间,最后释放锁,而之前的现场就会返回一份过期数据,如果在**新线程写入缓存**期间有其他线程来访问的话,查询缓存后,查到的是旧数据,此时会发现逻辑时间已经过期, 就会去获取互斥锁,获取失败后,会直接返回一份过期数据,只有当**新线程写入缓存的事件结束后**,其他线程再来访问,就可以得到新数据
+-
+- 缺点:当数千线程同时进入,只有一个线程可以得到互斥锁并重建缓存数据,其他线程只能无限期的等待,所以性能较差
+
+### 逻辑过期
+
+- 要设置逻辑过期,需要在缓存的时候添加**逻辑时间**,如果有线程查询缓存,当逻辑时间过期时,就会去获取互斥锁,然后开启一个新线程,由新线程来查询数据库,重建缓存数据并写入缓存,重置逻辑时间,最后释放锁,而之前的现场就会返回一份过期数据,如果在**新线程写入缓存**期间有其他线程来访问的话,查询缓存后,查到的是旧数据,此时会发现逻辑时间已经过期, 就会去获取互斥锁,获取失败后,会直接返回一份过期数据,只有当**新线程写入缓存的事件结束后**,其他线程再来访问,就可以得到新数据
+- 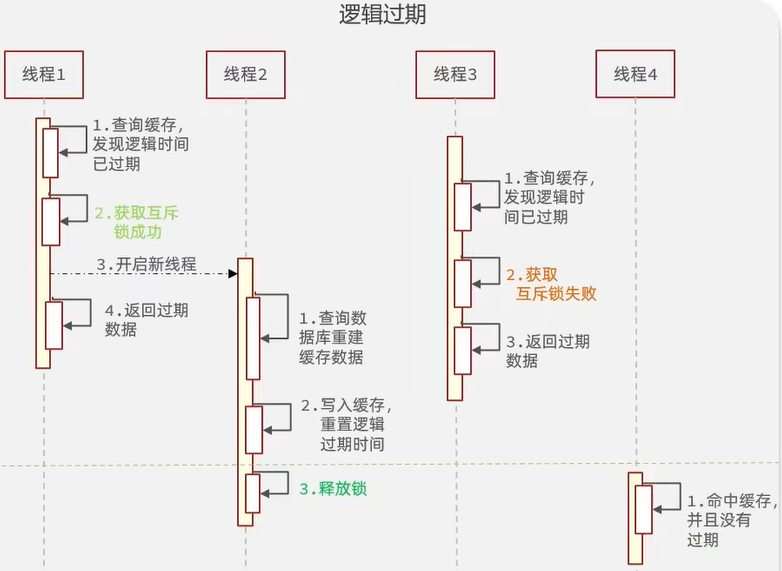 +
+### 互斥锁与逻辑过期的对比
+
+| 解决方案 | 优点 | 缺点 |
+| :------: | :----------------------------------------------: | :--------------------------------------------: |
+| 互斥锁 | 没有额外的内存消耗
+
+### 互斥锁与逻辑过期的对比
+
+| 解决方案 | 优点 | 缺点 |
+| :------: | :----------------------------------------------: | :--------------------------------------------: |
+| 互斥锁 | 没有额外的内存消耗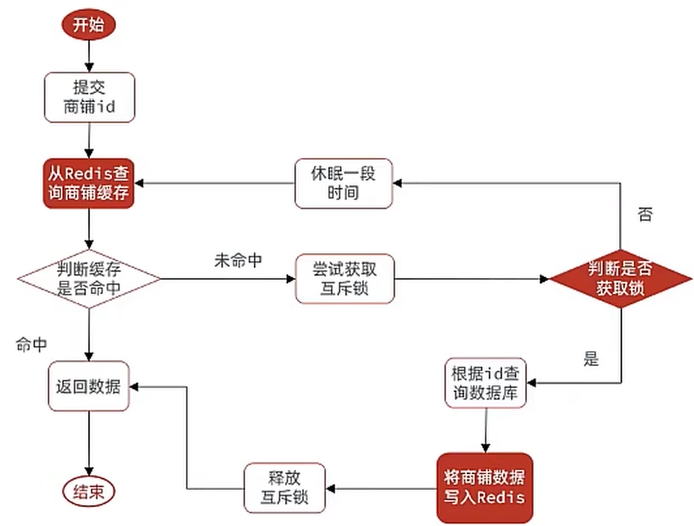 +
+在ServiceImpl下创建两个方法用于获取锁和释放锁
+
+```java
+// 获取锁
+private boolean TryLock(String key){
+ // 获取锁,并设置保存时间为10秒,因为业务一般1秒内都能结束
+ // 如果出现10秒还未结束的业务,说明有问题,将锁删除
+ // setIfAbsent,当key存在时,不创建key,否则创建key
+ Boolean aBoolean = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
+ // 返回可能会进行自动拆箱的操作,导致空指针,这里借助具体类修改
+ return BooleanUtil.isTrue(aBoolean);
+}
+
+// 释放锁
+private void unlock(String key){
+ stringRedisTemplate.delete(key);
+}
+```
+
+将缓存穿透的逻辑封装
+
+```java
+public Result queryWithPassThrough(Long id){
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+
+ // 如果是空字符串
+ if (cache != null){
+ // 如果在redis中没有查询到该商铺的信息,说明该缓存为null,去数据库中查询
+ // 如果数据库也为空,说明缓存穿透了,然后将空值写入Redis,并返回错误
+ // 当再次访问时,查询得到的会是空字符串,而不是空,就会直接拿到redis中的数据,会是空,然后报错
+ // StrUtil.isNotBlank会判别空字符串是空的,所以上面的并不会返回数据
+ return Result.fail("未找到该商铺信息");
+ }
+
+ // 不存在,根据id查询数据库
+ Shop shop = getById(id);
+ if (shop == null){
+ // 将空值写入Redis并设置时间为两分钟
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ //返回
+ return Result.ok(shop);
+}
+```
+
+#### 代码实现
+
+```java
+@Override
+public Result queryById(Long id) {
+ /* 缓存穿透
+ Result = queryWithPassThrough(id);*/
+
+ // 互斥锁解决缓存击穿
+
+ return queryWithMutex(id);
+}
+
+// 互斥锁
+public Result queryWithMutex(Long id){
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+
+ // 如果是空字符串
+ if (cache != null){
+ // 如果在redis中没有查询到该商铺的信息,说明该缓存为null,去数据库中查询
+ // 如果数据库也为空,说明缓存穿透了,然后将空值写入Redis,并返回错误
+ // 当再次访问时,查询得到的会是空字符串,而不是空,就会直接拿到redis中的数据,会是空,然后报错
+ // StrUtil.isNotBlank会判别空字符串是空的,所以上面的并不会返回数据
+ return Result.fail("未找到该商铺信息");
+ }
+
+ // 实现缓存重建
+ // 获取互斥锁
+ // 为每个商铺都添加一把锁,访问不同的店铺就会互不影响
+ String lockKey = "lock:shop" + id;
+ Shop shop = null;
+ try {
+ boolean isLock = TryLock(lockKey);
+ // 判断是否获取成功
+ if (!isLock){
+ // 失败,则休眠重试
+ Thread.sleep(50);
+ return queryWithMutex(id);
+ }
+
+
+ // 获取互斥锁成功,根据id查询数据库
+ shop = getById(id);
+ // 数据库不存在
+ if (shop == null){
+ // 将空值写入Redis并设置时间为两分钟
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ } catch (InterruptedException e) {
+ throw new RuntimeException(e);
+ }finally {
+ // 释放互斥锁
+ unlock(lockKey);
+ }
+
+ //返回
+ return Result.ok(shop);
+}
+```
+
+### 基于逻辑过期方式解决缓存击穿的问题
+
+#### 流程分析
+
+提交商铺id,从Redis中查询缓存,并判断缓存是否命中(一般情况下,都是绝对命中的,因为是逻辑过期)
+
+- 缓存命中:判断缓存是否过期(逻辑过期)
+ - 缓存未过期:直接返回商铺信息
+ - 缓存已过期:尝试获取互斥锁,判断是否能获取锁
+ - 获取锁成功:开启独立线程,并根据Id查询数据库,将商铺数据写入Redis,并设置逻辑过期时间,最后释放互斥锁
+ - 获取锁失败:说明有其他线程已经获取了锁正在进行操作,可以直接返回旧的商铺信息
+- 缓存未命中:很少出现这种情况,一旦出现了,返回空
+
+
+
+在ServiceImpl下创建两个方法用于获取锁和释放锁
+
+```java
+// 获取锁
+private boolean TryLock(String key){
+ // 获取锁,并设置保存时间为10秒,因为业务一般1秒内都能结束
+ // 如果出现10秒还未结束的业务,说明有问题,将锁删除
+ // setIfAbsent,当key存在时,不创建key,否则创建key
+ Boolean aBoolean = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
+ // 返回可能会进行自动拆箱的操作,导致空指针,这里借助具体类修改
+ return BooleanUtil.isTrue(aBoolean);
+}
+
+// 释放锁
+private void unlock(String key){
+ stringRedisTemplate.delete(key);
+}
+```
+
+将缓存穿透的逻辑封装
+
+```java
+public Result queryWithPassThrough(Long id){
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+
+ // 如果是空字符串
+ if (cache != null){
+ // 如果在redis中没有查询到该商铺的信息,说明该缓存为null,去数据库中查询
+ // 如果数据库也为空,说明缓存穿透了,然后将空值写入Redis,并返回错误
+ // 当再次访问时,查询得到的会是空字符串,而不是空,就会直接拿到redis中的数据,会是空,然后报错
+ // StrUtil.isNotBlank会判别空字符串是空的,所以上面的并不会返回数据
+ return Result.fail("未找到该商铺信息");
+ }
+
+ // 不存在,根据id查询数据库
+ Shop shop = getById(id);
+ if (shop == null){
+ // 将空值写入Redis并设置时间为两分钟
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ //返回
+ return Result.ok(shop);
+}
+```
+
+#### 代码实现
+
+```java
+@Override
+public Result queryById(Long id) {
+ /* 缓存穿透
+ Result = queryWithPassThrough(id);*/
+
+ // 互斥锁解决缓存击穿
+
+ return queryWithMutex(id);
+}
+
+// 互斥锁
+public Result queryWithMutex(Long id){
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)){
+ // 存在,直接返回
+ // 返回前需要转为对象
+ Shop shop = JSONUtil.toBean(cache, Shop.class);
+ return Result.ok(shop);
+ }
+
+ // 如果是空字符串
+ if (cache != null){
+ // 如果在redis中没有查询到该商铺的信息,说明该缓存为null,去数据库中查询
+ // 如果数据库也为空,说明缓存穿透了,然后将空值写入Redis,并返回错误
+ // 当再次访问时,查询得到的会是空字符串,而不是空,就会直接拿到redis中的数据,会是空,然后报错
+ // StrUtil.isNotBlank会判别空字符串是空的,所以上面的并不会返回数据
+ return Result.fail("未找到该商铺信息");
+ }
+
+ // 实现缓存重建
+ // 获取互斥锁
+ // 为每个商铺都添加一把锁,访问不同的店铺就会互不影响
+ String lockKey = "lock:shop" + id;
+ Shop shop = null;
+ try {
+ boolean isLock = TryLock(lockKey);
+ // 判断是否获取成功
+ if (!isLock){
+ // 失败,则休眠重试
+ Thread.sleep(50);
+ return queryWithMutex(id);
+ }
+
+
+ // 获取互斥锁成功,根据id查询数据库
+ shop = getById(id);
+ // 数据库不存在
+ if (shop == null){
+ // 将空值写入Redis并设置时间为两分钟
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
+ // 查询数据库后不存在,返回错误
+ return Result.fail("未找到该商铺信息");
+ }
+ // 存在,写入redis
+ // 转换前需要将对象转为json字符串存入
+ stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(shop),CACHE_SHOP_TTL, TimeUnit.MINUTES);
+ } catch (InterruptedException e) {
+ throw new RuntimeException(e);
+ }finally {
+ // 释放互斥锁
+ unlock(lockKey);
+ }
+
+ //返回
+ return Result.ok(shop);
+}
+```
+
+### 基于逻辑过期方式解决缓存击穿的问题
+
+#### 流程分析
+
+提交商铺id,从Redis中查询缓存,并判断缓存是否命中(一般情况下,都是绝对命中的,因为是逻辑过期)
+
+- 缓存命中:判断缓存是否过期(逻辑过期)
+ - 缓存未过期:直接返回商铺信息
+ - 缓存已过期:尝试获取互斥锁,判断是否能获取锁
+ - 获取锁成功:开启独立线程,并根据Id查询数据库,将商铺数据写入Redis,并设置逻辑过期时间,最后释放互斥锁
+ - 获取锁失败:说明有其他线程已经获取了锁正在进行操作,可以直接返回旧的商铺信息
+- 缓存未命中:很少出现这种情况,一旦出现了,返回空
+
+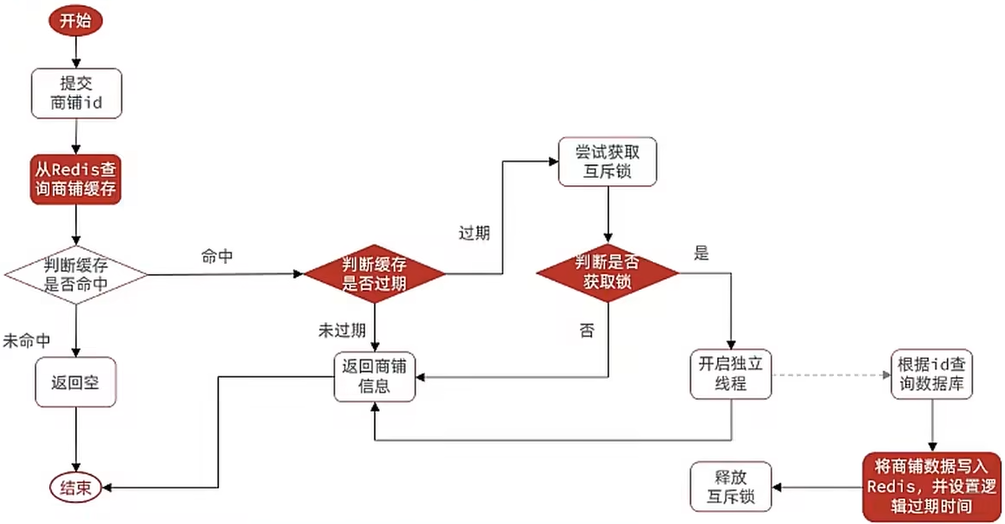 +
+#### 代码实现
+
+在原来的对象上添加逻辑过期时间,但是又不能修改原来的对象,修改了可能会影响到整体的代码逻辑,如何来添加新的数据呢
+
+**解决方案**
+
+- 新建一个类,继承对应的对象,并在新的对象上添加自己需要的属性,并创建一个包含原有数据的类data
+
+```java
+import lombok.Data;
+
+import java.time.LocalDateTime;
+
+@Data
+public class RedisData
+
+#### 代码实现
+
+在原来的对象上添加逻辑过期时间,但是又不能修改原来的对象,修改了可能会影响到整体的代码逻辑,如何来添加新的数据呢
+
+**解决方案**
+
+- 新建一个类,继承对应的对象,并在新的对象上添加自己需要的属性,并创建一个包含原有数据的类data
+
+```java
+import lombok.Data;
+
+import java.time.LocalDateTime;
+
+@Data
+public class RedisData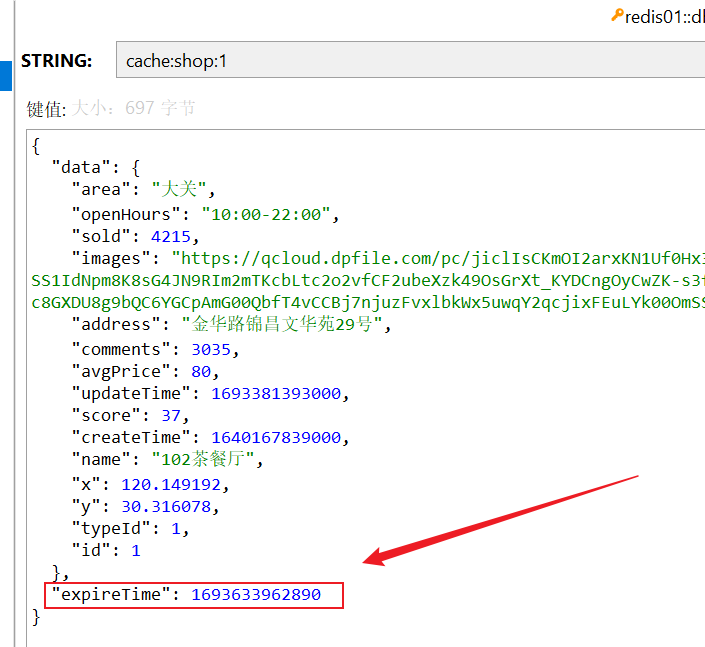 +
+ShopServiceImpl
+
+添加一段逻辑过期的代码
+
+```java
+@Override
+ public Result queryById(Long id) {
+ /* 缓存穿透
+ Result = queryWithPassThrough(id);*/
+
+ // 互斥锁解决缓存击穿
+
+// return queryWithMutex(id);
+
+ return queryWithLogicalExpire(id);
+ }
+
+
+ // 创建线程池
+ private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
+
+ // 逻辑过期解决缓冲击穿问题
+ public Result queryWithLogicalExpire(Long id) {
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)) {
+ // 不存在,返回空
+ // 返回前需要转为对象
+ return null;
+ }
+
+ // 从缓存中命中数据后,反序列化json为对象
+ RedisData redisData = JSONUtil.toBean(cache, RedisData.class);
+ JSONObject data = (JSONObject) redisData.getData();
+ Shop jsonShop = JSONUtil.toBean(data, Shop.class);
+ // 取出过期时间
+ LocalDateTime expireTime = redisData.getExpireTime();
+ // 判断是否过期
+ if (expireTime.isAfter(LocalDateTime.now())) {
+ // isAfter判断现在的时间是否在过期时间后
+ // 如果现在的时间在过期时间之后,说明还没过期
+ // 如果在过期时间之前,说明已过期
+ //未过期,直接返回商铺信息
+ return Result.ok(jsonShop);
+ }
+ // 已过期,缓存重建
+ // 判断是否获取互斥锁
+ if (TryLock(LOCK_SHOP_KEY + id)) {
+
+ // 获取互斥锁成功,开启新线程,实现缓存重建
+ // 线程最好通过线程池来获取,节省资源
+ CACHE_REBUILD_EXECUTOR.submit(() -> {
+ try {
+ // 重建缓存(在savaShop2Redis中有写过这个方法)
+ savaShop2Redis(id, 30L);
+ } catch (Exception e) {
+ throw new RuntimeException(e);
+ } finally {
+ // 释放锁
+ unlock(LOCK_SHOP_KEY + id);
+ }
+ });
+
+ }
+ // 获取互斥锁失败,直接返回商铺信息
+ return Result.ok(jsonShop);
+
+ }
+```
+
+即使逻辑过期了,也不影响数据,数据并不会消失
+
+## 缓存工具封装
+
+基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
+
+1. 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
+2. 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
+3. 根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透的问题
+4. 根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
+
+在utils包下新建CacheClient类,用于缓存工具的封装
+
+```java
+import cn.hutool.core.util.StrUtil;
+import cn.hutool.json.JSONUtil;
+import lombok.extern.slf4j.Slf4j;
+import org.springframework.beans.factory.annotation.Autowired;
+import org.springframework.data.redis.core.StringRedisTemplate;
+import org.springframework.stereotype.Component;
+
+import java.time.LocalDateTime;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Function;
+
+
+@Component
+@Slf4j
+public class CacheClient {
+ @Autowired
+ private final StringRedisTemplate stringRedisTemplate;
+
+ public CacheClient(StringRedisTemplate stringRedisTemplate) {
+ this.stringRedisTemplate = stringRedisTemplate;
+ }
+
+ /**
+ * 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
+ * */
+ public void set(String key, Object value, Long time, TimeUnit timeUnit){
+ stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value),time,timeUnit);
+ }
+
+
+ /**
+ * 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
+ * */
+ public void setWithLogicalExpire(String key,Object value,Long time,TimeUnit timeUnit){
+ RedisData
+
+ShopServiceImpl
+
+添加一段逻辑过期的代码
+
+```java
+@Override
+ public Result queryById(Long id) {
+ /* 缓存穿透
+ Result = queryWithPassThrough(id);*/
+
+ // 互斥锁解决缓存击穿
+
+// return queryWithMutex(id);
+
+ return queryWithLogicalExpire(id);
+ }
+
+
+ // 创建线程池
+ private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
+
+ // 逻辑过期解决缓冲击穿问题
+ public Result queryWithLogicalExpire(Long id) {
+ // 从redis查询商铺缓存
+ String cache = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
+ // 判断是否存在
+ if (StrUtil.isNotBlank(cache)) {
+ // 不存在,返回空
+ // 返回前需要转为对象
+ return null;
+ }
+
+ // 从缓存中命中数据后,反序列化json为对象
+ RedisData redisData = JSONUtil.toBean(cache, RedisData.class);
+ JSONObject data = (JSONObject) redisData.getData();
+ Shop jsonShop = JSONUtil.toBean(data, Shop.class);
+ // 取出过期时间
+ LocalDateTime expireTime = redisData.getExpireTime();
+ // 判断是否过期
+ if (expireTime.isAfter(LocalDateTime.now())) {
+ // isAfter判断现在的时间是否在过期时间后
+ // 如果现在的时间在过期时间之后,说明还没过期
+ // 如果在过期时间之前,说明已过期
+ //未过期,直接返回商铺信息
+ return Result.ok(jsonShop);
+ }
+ // 已过期,缓存重建
+ // 判断是否获取互斥锁
+ if (TryLock(LOCK_SHOP_KEY + id)) {
+
+ // 获取互斥锁成功,开启新线程,实现缓存重建
+ // 线程最好通过线程池来获取,节省资源
+ CACHE_REBUILD_EXECUTOR.submit(() -> {
+ try {
+ // 重建缓存(在savaShop2Redis中有写过这个方法)
+ savaShop2Redis(id, 30L);
+ } catch (Exception e) {
+ throw new RuntimeException(e);
+ } finally {
+ // 释放锁
+ unlock(LOCK_SHOP_KEY + id);
+ }
+ });
+
+ }
+ // 获取互斥锁失败,直接返回商铺信息
+ return Result.ok(jsonShop);
+
+ }
+```
+
+即使逻辑过期了,也不影响数据,数据并不会消失
+
+## 缓存工具封装
+
+基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
+
+1. 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
+2. 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
+3. 根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透的问题
+4. 根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题
+
+在utils包下新建CacheClient类,用于缓存工具的封装
+
+```java
+import cn.hutool.core.util.StrUtil;
+import cn.hutool.json.JSONUtil;
+import lombok.extern.slf4j.Slf4j;
+import org.springframework.beans.factory.annotation.Autowired;
+import org.springframework.data.redis.core.StringRedisTemplate;
+import org.springframework.stereotype.Component;
+
+import java.time.LocalDateTime;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Function;
+
+
+@Component
+@Slf4j
+public class CacheClient {
+ @Autowired
+ private final StringRedisTemplate stringRedisTemplate;
+
+ public CacheClient(StringRedisTemplate stringRedisTemplate) {
+ this.stringRedisTemplate = stringRedisTemplate;
+ }
+
+ /**
+ * 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置TTL过期时间
+ * */
+ public void set(String key, Object value, Long time, TimeUnit timeUnit){
+ stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value),time,timeUnit);
+ }
+
+
+ /**
+ * 将任意Java对象序列化为json并存储在string类型的key中,并且可以设置逻辑过期时间,用于处理缓存击穿问题
+ * */
+ public void setWithLogicalExpire(String key,Object value,Long time,TimeUnit timeUnit){
+ RedisData