[TOC]
要对分布式条件下的进程保持水平扩展的能力,就必须保证进程不保存内存状态数据,可以做到随时结束和重生,尽管如此我们仍然希望在结束或者重生的过程中能够尽量小的影响到当前的既有服务的用户,比如服务进程能够停止 Accept 新的用户业务,但是仍然能够将当前已经在处理过程中的用户服务完成。go语言在1.8开始提供了 graceful shutdown 的能力,参见 What's Coming in Go 1.8,如果1.8以前的版本,可以使用库 https://github.com/tylerb/graceful 来实现。
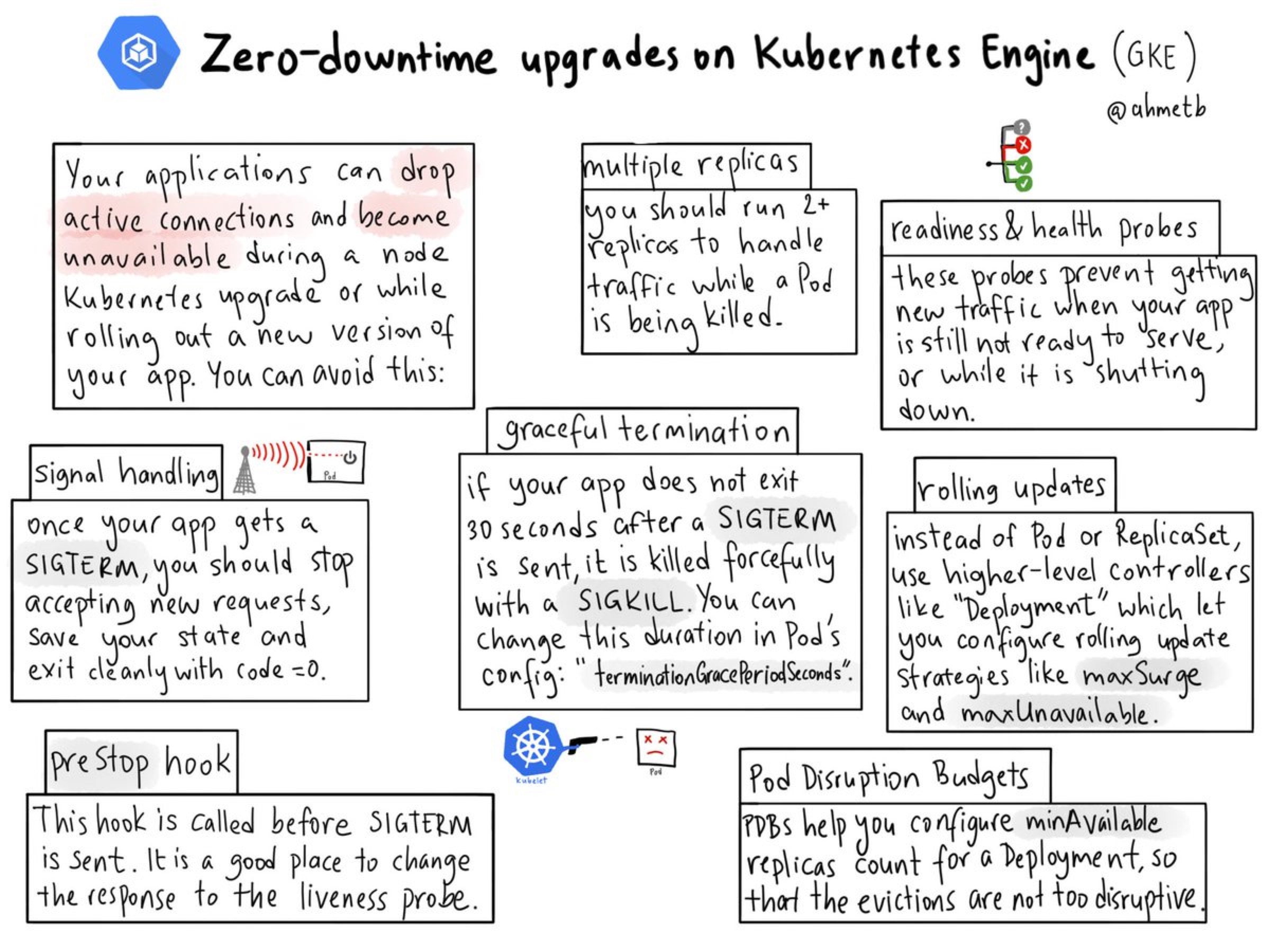
部署在Kubernetes中的Pod由于自动扩容 HPA、Pod或Deployment删除、Rolling Update等各种操作中,会导致Pod终止,Kubernetes中的Pod在终止过程中会经历以下阶段:
-
集群会发送一个
SIGTERM信号量到准备结束容器的main进程(pid==1) 开始 “grace period” 计时(默认30秒 - 可以修改). -
容器接受到
SIGTERM, 启动 gracefule shutdown并最终退出。 -
如果在指定定义时间内,容器没有终止,那么集群会发送
SIGKILL信号量来强制终止容器参见:
- Kubernetes: Termination of pods
- Kubernetes: Pods lifecycle hooks and termination notice
- Kubernetes: Container lifecycle hooks
Pod 终止的流程: Kubernetes: Termination of pods
-
用户发送删除 Pod 的命令,默认 grace period 为 30s ,可以通过
--grace-period=60调整; -
API Server 标记 Pod 状态为 Dead 状态,记录更新时间和 grace period;
-
通过 Client 命令查看,Pod被标记为 “Terminating”;
-
(与3同时发生)当 Kubelet 进程监听 API Server 获取到 Pod 被更新为 Terminating,由于在第2步中设置了时间,于是启动关闭 Pod 的过程;
-
如果 Pod 定义了 preStop Hook,则在 Pod 内部进行调用;如果在 grace period 过期后,preStop 仍然在运行,步骤 2 的调用会将小幅度扩大 grace period 2s;
-
Pod 中的进程接收到到 TERM 信号量;
-
(与3同时发生),Pod从Service 对应的 endpoints 中删除,不再被认为是 Replication Controllers 中运行的Pod,逐渐关闭的可以继续服务流量,就像负载局衡器(例如服务代理)把它们从它们的轮转中剔除一样;
-
当 grace period 超时过期,在 Pod 中仍然运行的任何进程都会被 SIGKILL杀掉;
-
Kubelet 会在 API Server 上设置 grace period 为 0(立即删除)来完成删除的过程;Pod 将从API Server 中消息,不再出现在命令的列表中;
HttpServer 的 Shutdown 方法可以实现 graceful shutdown
func (srv *Server) Shutdown(ctx context.Context) error调用 Shutdown 方法,不会中断现在已经活跃的连接;Shutdown 首先会关闭当前正在监听的 listeners, 关闭当前 idle 的连接,然后一直等待其他连接状态变成 idle 并关闭;如果函数调用传递了 context 超时时间,在Shutdown 完成以前,已经超时,Shutdown返回 context 超时错误,否则返回在关闭listeners 过程中的任何错误;
当 Shutdown 方法被调用, Serve, ListenAndServe和 ListenAndServeTLS会立即返回 ErrServerClosed,因此需要保证程序不会退出而是等待 Shutdown返回。Shutdown 不会试图关闭或者接管类似于 WebSocket 等一类的长连接,需要程序主动处理长连接的的关闭问题。
因此一般不将 srv.ListenAndServe()等类似函数放到主 goroutine 中,以避免 Shutdown 后主 goroutine 退出,导致不能 graceful shutdown,正确的写法如下:
package main
import (
"context"
"io"
"log"
"net/http"
"os"
"os/signal"
"time"
)
var SHUTDOWN_TIMEOUT = 30 * time.Second
func main() {
// subscribe to SIGINT/SIGTEM signals
stopChan := make(chan os.Signal)
signal.Notify(stopChan, syscall.SIGINT, syscall.SIGTERM)
mux := http.NewServeMux()
mux.Handle("/", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
time.Sleep(SHUTDOWN_TIMEOUT)
io.WriteString(w, "Finished!")
}))
srv := &http.Server{Addr: ":8081", Handler: mux}
go func() {
// service connections
if err := srv.ListenAndServe(); err != nil {
log.Printf("listen: %s\n", err)
}
}()
<-stopChan // wait for SIGINT or SIGTERM
log.Println("Shutting down server...")
// shut down gracefully, but wait no longer than 30 seconds before halting
ctx, _ := context.WithTimeout(context.Background(), 30*time.Second)
srv.Shutdown(ctx)
log.Println("Server gracefully stopped")
}如果涉及到多个项目同时支持该功能,建议封装成一个通用库处理该情况,可以参考 https://github.com/TV4/graceful/
Dockerfile ˙
CMD myapp正真运行的命令是 /bin/sh -c myapp,因此得到信号量 SIGTERM实际上是 /bin/sh 而不是子进程 myapp,信号量是否传递给子进程 myapp 取决于运行的实际的shell。Alpine Linux 不会将信号量传递给子进程,而 bash 则可以;如果 Shell 不能将信号量传递到子进程,可以选择的方式如下:
Option #1: run the CMD in the exec form
CMD [ "myapp" ]
Option #2: run the command with Bash
CMD [ "/bin/bash", "-c", "myapp --arg=$ENV_VAR" ]
###4.1 修改 grace period
Option #1 CMD
$ kubectl delete --grace-period=60
Option #2 Deployment
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: test
spec:
replicas: 1
template:
spec:
containers:
- name: test
image: ...
terminationGracePeriodSeconds: 60
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx
spec:
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
# SIGTERM triggers a quick exit; gracefully terminate instead
command: ["/usr/sbin/nginx","-s","quit"]